

NVIDIA提出多模态大模型Omni-RGPT!Token Mark实现区域级理解!
为了实现图像中的交互式区域特定理解,最近的方法采用了各种策略来表示目标区域:在文本标记中编码文本框坐标,利用视觉 RoI 特征,或应用视觉标记。将这些能力扩展到视频领域,一些方法将初始帧的边界框坐标作为文本形式用于区域级视频理解任务。然而,一种能够有效解决图像和视频中区域特定任务的通用方法仍然是一个开放的挑战。

北航联合美团提出LLaVA-ST!细粒度时空多模态理解的MLLM!
我们将需要基于语言输入处理视觉坐标的任务称为细粒度多模态理解。对于这些任务,当前的MLLMs主要集中在两个方面:有的模型擅长图像中物体的空间定位,但在细粒度时间理解任务上表现不佳;有的模型专门擅长像TVG这样的细粒度时间理解,但无法确定物体的边界框。现有的MLLMs无法统一实现空间、时间和交错的细粒度多模态理解任务。

清华提出ArtCrafter!可控多样的风格迁移框架!
ArtCrafter,这是一种新颖的文本到图像风格迁移框架。具体来说,我们引入了一个基于注意力的风格提取模块,该模块经过精心设计,以捕捉图像中微妙的风格元素。

NJU联合腾讯提出VITA-1.5!GPT-4o级别的实时视觉语音交互框架!
本文提出了一种精心设计的分阶段训练方法,逐步训练大型语言模型以理解视觉和语音信息,最终实现流畅的视觉和语音交互。我们的方法不仅保留了强大的视听能力,而且无需单独的自适应语音识别(ASR)和文本到语音(TTS)模块,就能实现高效的语音转语音对话能力,显著加快了多模态端到端的响应速度。

基于Gemini!Waymo提出端到端自动驾驶多模态模型EMMA!
我们介绍了EMMA,一个端到端的自动驾驶多模态模型。基于多模态大型语言模型的基础,EMMA直接将原始相机传感器数据映射到各种特定于驾驶的输出中,包括规划器轨迹、感知对象和道路图元素。EMMA通过将所有非传感器输入(例如导航指令和自我车辆状态)和输出(例如轨迹和3D位置)表示为自然语言文本,最大化了预训练大型语言模型的世界知识效用。

电影角色大变身!MovieCharacter框架让角色视频合成更简单高效!
角色视频合成的最新进展仍然依赖于广泛的微调或复杂的3D建模过程,这可能会限制可访问性并阻碍实时应用性。为了解决这些挑战,我们提出了一种简单而有效的无调整框架,名为MovieCharacter,旨在简化合成过程同时确保高质量的结果。

阿里提出LLaVA-MoD架构!利用MOE技术让小模型也能大显身手!
多模态大型语言模型(MLLM)通过在大型语言模型(LLM)中集成视觉编码器,在多模态任务中取得了有希望的结果。然而,大型模型的大小和广泛的训练数据带来了显著的计算挑战。例如,LLaVA-NeXT的最大版本使用了Qwen-1.5-110B,并且使用128个H800 GPU训练了18小时。

阿里达摩院提出Animate3D: 4D内容生成的新框架!
由于3D内容创作在AR/VR、游戏和电影行业中的广泛应用,它已经引起了显著的关注。随着扩散模型的发展和大规模3D对象数据集的建立,最近三代3D基础生成通过微调的文本到图像(T2I)扩散模型以及从头开始训练大型重建模型得到了广泛的探索,引领了3D资产创建进入新时代。

上海AI Lab提出TimeSuite:解锁MLLM长视频理解的潜力!
多模态大型语言模型(MLLMs)通过遵循一般的人类指令来解释视觉内容,已经展示了令人印象深刻的视频理解性能。然而,这些MLLMs在长视频理解方面仍然存在困难,因为长视频序列可能包含各种动态动作和复杂的时间关系,这使得MLLMs难以有效定位与问题相关的关键片段。
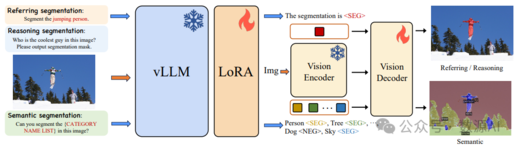
SAM+多模态大模型实现开集分割!清华联合美团提出LaSagnA!
最近进展使大型视觉语言模型 (Large Language Models for Vision,vLLMs) 能够生成详细的感知输出,包 括边界框和掩码。然而,限制这些 vLLMs 进一步应 用的两个约束是:每个查询无法处理多个目标,以及 无法识别图像中查询对象不存在。
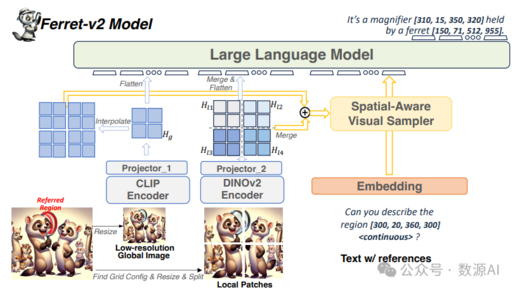
支持任意分辨率图像的MLLM!定位识别超强!Apple提出Ferret-v2!
多模态大型语言模型(Multimodal Large Language Models,MLLMs)在人工智能 的最新进展中扮演着关键角色,作为通用全能助手开发的基础元素。然而,这些方法依赖 于粗粒度的图像级对齐,缺乏对细节的理解(如区域描述和推理)。

一秒钟实现移动图像中任何物体!Meta提出新的分层可控文生图模型!
可控场景生成(即生成具有可重新排列布局的图 像的任务)是生成建模的一个重要课题 [16, 34],其应 用范围包括社交媒体平台的内容生成和编辑,以及互 动式室内设计和视频游戏。

20000 文本提示微调Stable Diffusion!商汤联合上海AI Lab提出CoMa!
文本到图像生成领域最近随着扩散模型的引入取得了显著进步。然而,对不 一致问题仍然缺乏合理的解释。缓解文本提示和图像之间的不对齐仍然是一个挑战。

32.2M指代分割数据集,新SOTA!国科大提出统一的对象级和部分级定位新方法UniRES!
数源AI推荐的论文介绍了一种指代表达分割(RES)任务,旨在通过描述性语言在像素级别定位特定区域。文章提出了多粒度指代表达分割(MRES)任务,并构建了RefCOCOm评估基准和MRES-32M数据集。提出的UniRES模型在对象级和部分级定位任务上表现优异,超越了先前的方法。
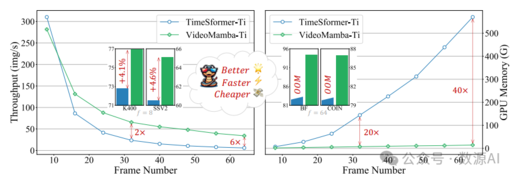
Mamba再下一城!上海AI Lab提出视频领域新SOTA VideoMamba!
数源AI推荐的论文'VideoMamba: State Space Model for Efficient Video Understanding'介绍了VideoMamba模型,它通过线性复杂度运算符实现高效长视频理解。该模型克服了3D CNN和视频变换器的局限,具备可扩展性、敏感性、优越性和兼容性。

幻方发布超强多模态LLM DeepSeek-VL!支持代码,文档OCR等!
DeepSeek-VL是一个为现实世界设计的开源视觉语言模型,它通过数据构建、模型架构和训练策略三个维度来实现对高分辨率图像的高效处理和丰富语义理解。
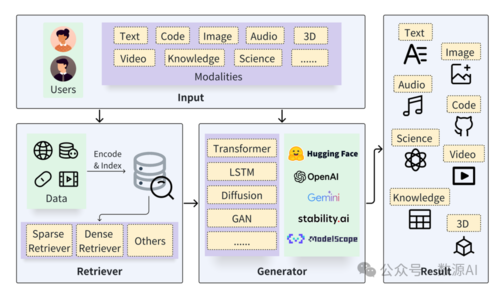
最新RAG综述来了!北京大学发布AIGC的检索增强技术综述
北京大学崔斌教授领导的数据与智能实验室发布了关于检索增强生成(RAG)技术的综述,涵盖近300篇相关论文。RAG技术结合检索与生成,用于问答、对话生成等AI任务,展现出卓越潜力。
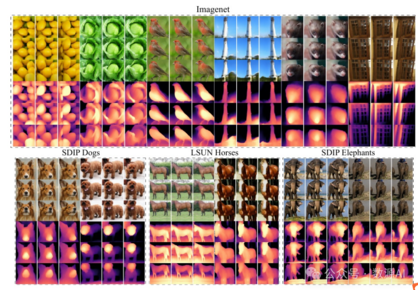
一张ImageNet图像构建3D对象!华为诺亚提出3D生成新方法G3DR!
数源AI推荐的论文《G3DR: Generative 3D Reconstruction in ImageNet》介绍了一种新的3D生成方法G3DR,能从单个图像生成多种高质量3D对象。G3DR利用深度正则化技术和预训练的语言视觉模型CLIP,

7000万高质量视频文本对!文生视频最大的开源数据集Panda-70M来了!
数源AI推荐的论文介绍了Panda-70M数据集,该数据集通过多模态教师模型自动为7000万个视频生成高质量字幕。研究表明,该数据集在视频字幕生成、视频文本检索和文本驱动视频生成等下游任务上表现优异。
LLM指导3D说话面部生成!百度提出AVI-Talking!
数源AI推荐了一篇论文AVI-Talking,该论文提出了一种基于音频-视觉指令的系统,用于生成表现力丰富的3D说话人脸。系统通过大型语言模型理解音频信息,并生成指令来指导基于扩散的生成网络合成逼真的3D面部动画。

