
云上的卡夫卡
ZD至顶网软件频道消息:
从是否正确出发,而不是从能否接受出发。
Start with what is right rather than what is acceptable.
弗兰兹·卡夫卡
1、背景
假设你意气风发,要开发新一代的互联网应用,以期在互联网事业中一展宏图。借助云计算,很容易开发出如下原型系统:
- Web应用:部署在云服务器上,为个人电脑或者移动用户提供的访问体验。
- SQL数据库:为Web应用提供数据持久化以及数据查询。

这套架构简洁而高效,很快便能够部署到百度云等云计算平台,以便快速推向市场。互联网不就是讲究小步快跑嘛!
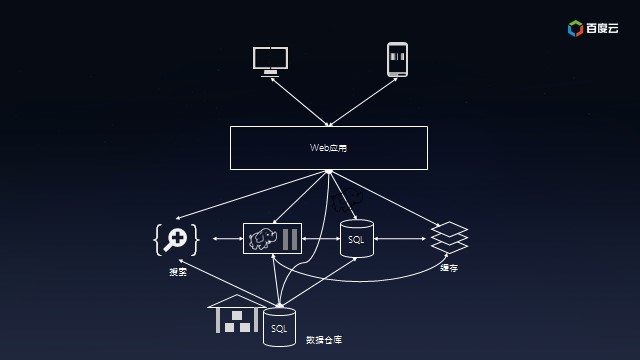
好景不长。随着用户的迅速增长,所有的访问都直接通过SQL数据库使得它不堪重负,不得不加上缓存服务以降低SQL数据库的荷载;为了理解用户行为,开始收集日志并保存到Hadoop上离线处理,同时把日志放在全文检索系统中以便快速定位问题;由于需要给投资方看业务状况,也需要把数据汇总到数据仓库中以便提供交互式报表。此时的系统的架构已经盘根错节了,考虑将来还会加入实时模块以及外部数据交互,真是痛并快乐着……
这时候,应该跑慢一些,让灵魂跟上来。
本质上,这是一个数据集成问题。没有任何一个系统能够解决所有的事情,所以业务数据根据不同用途存而放在不同的系统,比如归档、分析、搜索、缓存等。数据冗余本身没有任何问题,但是不同系统之间像意大利面条一样复杂的数据同步却是挑战。
这时候就轮到Kafka出场了。
Kafka可以让合适的数据以合适的形式出现在合适的地方。Kafka的做法是提供消息队列,让生产者单往队列的末尾添加数据,让多个消费者从队列里面依次读取数据然后自行处理。之前连接的复杂度是O(N^2),而现在降低到O(N),扩展起来方便多了:
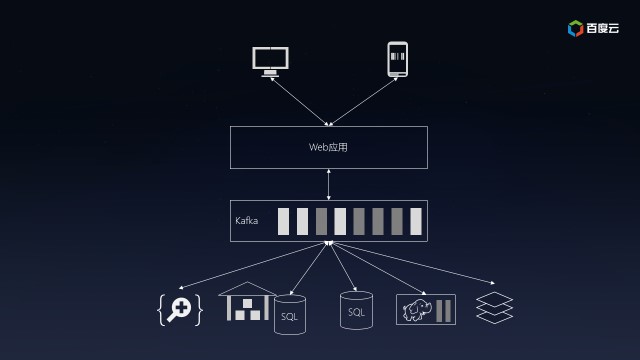
在Kafka的帮助下,你的互联网应用终于能够支撑飞速增长的业务,成为下一个BAT指日可待。
2、Apache Kafka
Kafka最早由LinkedIn开发,如今已经成为Apache基金会顶级项目,被Walmart、Netflix、PayPal、Uber、eBay等采用。
在国内互联网圈子中Kafka也是大数据圈子中必备的社交货币,茶余饭后指点江山说起卡夫卡,联想到Franz Kafka是文青,联想到Apache Kafka的才是大数据工程师。
本质上Kafka是分布式的流数据平台,因为以下特性而著名:
- 提供Pub/Sub方式的海量消息处理。
- 以高容错的方式存储海量数据流。
- 保证数据流的顺序。
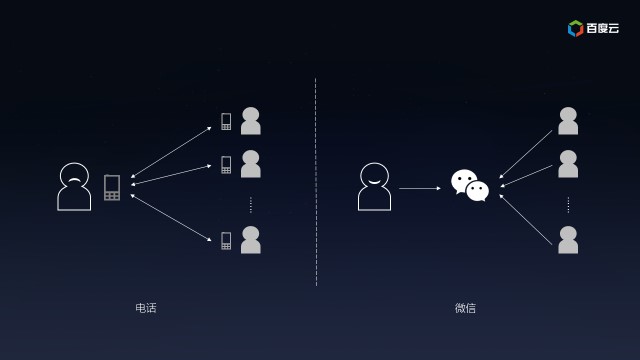
说起Pub/Sub,熟悉企业应用集成(Enterprise Application Integration,EAI)的朋友不会陌生,它是一种处理消息的范式,消息的发布者(Pub)只需要指定消息的类别,而不需要与订阅者(Sub)打交道。订阅者对一个或多个类别表达兴趣,于是只接收感兴趣的消息,而不需要知道什么样的发布者发布的消息。这种发布者和订阅者的解耦可以给应用带来更好的可扩展性。
打个比方,你的公司业务蓬勃发展,前后开发了多个互联网应用都需要做市场推广。一种方法是通过电话向客户推广产品新特性,不但需要找到每个互联网应用所对应的客户名单,还要挨个电话联系,可是,客户不一定有空接电话或者已经在通讯中了,长长的客户名单也会让你头疼不已;另一种方法是为每个互联网应用创建一个微信公众号(用公众号分割推广信息),让客户订阅后推送产品新特性的信息(客户不用关心到底谁发的),客户有空的时候看一下(客户不用立等答复你),信息量太大的话就再加个同事订阅(水平扩展客户处理能力),有机会还可以介绍给其他潜在用户订阅(你也不必特意通知新客户)。很明显,电话这种同步消息交换的方式很容易产生瓶颈,而微信公众号这类异步消息交换的方式客户再多也不用担心。
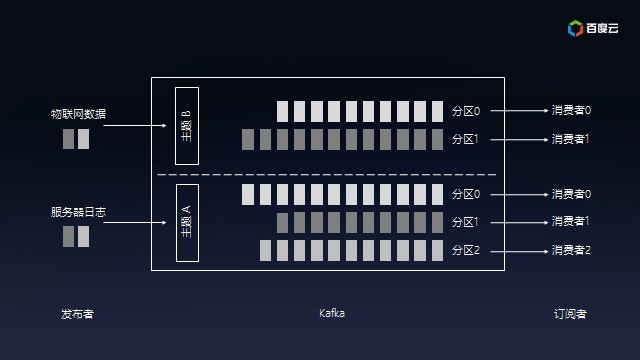
Kafka提供的Pub/Sub就是典型的异步消息交换,用户可以为服务器日志或者物联网设备创建不同主题(Topic),之后数据可以源源不断地发送到各个主题,后端数据仓库、流式分析或者全文检索等对接特定主题,服务器或者物联网设备是无需关心的。
同时,Kafka可以将主题划分为多个分区(Partition),会根据分区规则选择把消息存储到哪个分区中,只要如果分区规则设置的合理,那么所有的消息将会被均匀的分布到不同的分区中,这样就实现了负载均衡和水平扩展。另外,多个订阅者可以从一个或者多个分区中同时消费数据,以支撑海量数据处理能力:
Kafka的设计也是源自生活,好比是为公路运输,不同的起始点和目的地需要修不同高速公路(主题),高速公路上可以提供多条车道(分区),流量大的公路多修几条车道保证畅通,流量小的公路少修几条车道避免浪费。收费站好比消费者,车多的时候多开几个一起收费避免堵在路上,车少的时候开几个让汽车并道就好了,嗯……
顺便说一句,由于消息是以追加到分区中的,顺序写磁盘的效率要比随机写内存还要高,是Kafka高吞吐率的重要保证之一。
为了保证数据的可靠性,Kafka会给每个分区找一个节点当带头大哥(Leader),以及若干个节点当随从(Follower)。消息写入分区时,带头大哥除了自己复制一份外还会复制到多个随从。如果随从挂了,Kafka会再找一个随从从带头大哥那里同步历史消息;如果带头大哥挂了,随从中会选举出新一任的带头大哥,继续笑傲江湖。

最后,每个发布者发送到Kafka分区中的消息是确保顺序的,订阅者可以依赖这个承诺进行后续处理。
3、百度Kafka
Kafka优点种种,但是要把Kafka用好并不容易。开源免费是好事情,但是如何能够保证24x7的运维保障业务稳定运行是个大问题。同时,初期业务量小的时候,闲置Kafka集群又能造成很大的浪费。
针对以上问题,百度云天算大数据平台推出了百度Kafka服务。大体上,百度Kafka是社区版本的多租户全托管服务,与自行运维Kafka集群相比,有以下增强:
- 开箱即用:可以直接创建主题并使用Kafka服务,专注业务而不用花费精力去安装、部署、配置、调试和维护集群。
- 低廉价格:只需为使用的资源而不是虚拟主机付费,同时支持动态扩容。
- 数据安全:支持SSL加密,保证数据在传输的过程中不被窃听或者篡改。
- 可靠耐用:独特的服务高可用性以及数据高可靠性设计。
秉承开源开放的宗旨,百度Kafka与社区的Kafka高度兼容,迁移成本极低且不用担心被供应商绑定。
附靓照一张:

点击百度Kafka了解更多,具体玩法请看下集。
好文章,需要你的鼓励



京东氧气AI商品中台:用千亿规模的AI大脑,让每一件商品都被精准理解
京东氧气AI商品中台(Oxygen AIIC)通过大语言模型与视觉语言模型,构建了覆盖千亿级商品知识资产的全链路生产与服务系统,将商品信息丰富度提升至3.35倍。


当AI变成“家教“:KAIST团队如何让强化学习训练突破“无聊题目“的瓶颈
KAIST等机构提出LLM-as-a-Tutor框架,通过动态追加题目条件,让AI强化学习训练中的难度随模型能力自动升级,解决题目过易导致学习信号失效的问题。
2017
01/05
17:50
分享
点赞

机器人管家系统上线!傅利叶携多款康养陪伴新品方案亮相WAIC 2026
赛那德“ 自主作业机器人天团” 登陆 WAIC:iLoabot-X+模型双升级,秀出具身场景落地硬实力
西门子Eigen工程智能体中国首发首展,荣获2026 WAIC SAIL之星奖
NVIDIA Cosmos 推动物理 AI 前沿发展
PPIO亮相WAIC 2026:发布智能模型网关,打造面向Agent时代的智能Token工厂
端侧感知、私有闭环、量子协同, NVIDIA全栈异构计算范式“接管”实体产业底座
边缘智算筑基、全栈软硬协同,研华科技将AI带进产业闭环
千问AI眼镜将升级为智能体眼镜:能灵活调用Skill和Agent,能全天候感知
对话Moonix郭于晨:先让用户戴上“眼镜”,再让“AI”记录世界
亮相WAIC 2026,临床实证赋能康养升级 无芯科技定义AI疗愈新范式
生态覆盖持续扩散,一文看懂各行业企业鸿蒙化转型进度
WAIC亮出集群协作真功夫,优艾智合领跑工业具身智能规模化
