
OpenAI及DeepMind两团队令未来的AI机器更安全 原创
OpenAI和DeepMind的研究人员使用的新算法从人类反馈中学习,他们希望这样做能使人工智能更安全。
两家公司均为强化学习的专家,强化学习是机器学习的一个领域,其基本思想是,如果代理在特定的环境里采取正确的行动完成了任务就给予奖励。该目标是通过一种算法来指定的,代理经过程序后就会追逐奖励,例如游戏中的获胜点。
强化学习在训练机器如何玩如Doom或Pong等游戏或通过模拟驾驶自主驾驶汽车等案例中取得了成功。强化学习是探索代理行为的一个有效的方法,但如果硬编码算法错了或产生不良影响的话,这种方法可能也有危险。
arXiv上发表的一篇论文描述了一种有助于防止此类问题的新方法。首先,代理在其环境中执行随机动作。预测的奖励则是基于人类的判断,而且奖励被反馈到强化学习算法中,以改变代理的行为。
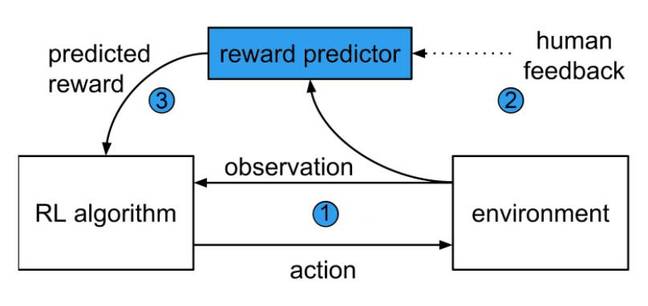
系统在人类指导下制定最佳行动及学习目标
研究人员将这种算法用于训练一个弯曲的灯柱往后仰。代理的两个视频然后再交给人观看,观看者选择哪一个的后仰动作更佳一些。
经过一段时间后,代理就逐渐学习了如何根据奖励函数最有效地解释人类的判断来学习目标。强化学习算法用于指导代理的行为,并可以持续在人类的批准下进行改进。
网上可找到相关的视频。(https://www.youtube.com/watch?v=oC7Cw3fu3gU)
人类评估者花掉的时间不足一个小时。但要完成做饭或发送电子邮件等更复杂的任务就会需要更多的人类反馈,从财务的角度来看则是昂贵的。
文章的作者之一达里奥·阿莫德(Dario Amodei)是OpenAI的一名研究人员,他表示,未来研究的重点会放在减少监督方面。
他告诉记者,“泛泛而言,名为半监督学习的技术在这一块可能有帮助。另一种可能性是提供更信息密集的反馈形式,如语言,或是让人类在屏幕上具体指出表示良好行为的部分。更多的信息密集反馈可能会让人类在更短的时间内更多地与算法进行沟通。“
上述研究人员在其他模拟机器人任务和Atari游戏里测试了他们的算法,结果显示机器有时可以实现超人式的性能。但这在很大程度上取决于人类评估者的判断。
OpenAI在一篇博文里表示,“我们算法的性能只能和人类评估者对于什么是正确行为的直觉一样好,所以,如果人类对一个任务没有很好的把握,那他们可能提供不了太多有用的反馈。”
阿莫德表示,目前的结果仅局限于非常简单的环境。但这种方法大有可能对有些很难学习的任务有用,这些任务的奖励功能很难量化,例如驾驶、组织事件、写作或技术支持的提供。
好文章,需要你的鼓励


全球数据中心电力需求暴涨,超越电网建设速度
国际能源署发布的2025年世界能源展望报告显示,全球AI竞赛推动创纪录的石油、天然气、煤炭和核能消耗,加剧地缘政治紧张局势和气候危机。数据中心用电量预计到2035年将增长三倍,全球数据中心投资预计2025年达5800亿美元,超过全球石油供应投资的5400亿美元。报告呼吁采取新方法实现2050年净零排放目标。

破解AI代码“指纹“:阿布扎比科技创新研究院首次揭示大语言模型JavaScript代码独有“DNA“
阿布扎比科技创新研究院团队首次发现大语言模型生成的JavaScript代码具有独特"指纹"特征,开发出能够准确识别代码AI来源的系统。研究创建了包含25万代码样本的大规模数据集,涵盖20个不同AI模型,识别准确率在5类任务中达到95.8%,即使代码经过混淆处理仍保持85%以上准确率,为网络安全、教育评估和软件取证提供重要技术支持。

AMD双轮驱动:路线图与资金互促,收入持续提升
AMD首席执行官苏姿丰在纽约金融分析师日活动中表示,公司已准备好迎接AI浪潮并获得传统企业计算市场更多份额。AMD预计未来3-5年数据中心AI收入复合年增长率将超过80%,服务器CPU收入份额超过50%。公司2025年预期收入约340亿美元,其中数据中心业务160亿美元。MI400系列GPU采用2纳米工艺,Helios机架系统将提供强劲算力支持。

斯坦福大学惊人发现:AI比人类更懂语言?还是人类判断更准确?
斯坦福大学研究团队首次系统比较了人类与AI在文本理解任务中的表现。通过HUME评估框架测试16个任务发现:人类平均77.6%,最佳AI为80.1%,排名第4。人类在非英语文化理解任务中显著优于AI,而AI在信息处理任务中更出色。研究揭示了当前AI评估体系的缺陷,指出AI的高分往往出现在任务标准模糊的情况下。
2017
06/14
17:00
分享
点赞

AMD 锐龙AI MAX+ 395问鼎“技术王座”"春雨计划"润泽智慧万象
青云AI Infra 3.0,为企业搭建一条通向AI能力落地的桥梁
百分点科技发布业内首个数据治理大模型,开启“智理”新范式
全球数据中心电力需求暴涨,超越电网建设速度
AMD双轮驱动:路线图与资金互促,收入持续提升
FMC获得FERAM资金以终结Optane的阴霾
AI驱动垂直市场的商业变革与未来机遇
谷歌计划在德州投资400亿美元建设数据中心
AI推动KubeCon NA 2025平台工程复兴浪潮
DeepL CEO:专业翻译服务如何在ChatGPT时代保持竞争优势
提示工程迎来协作提示新技术,让AI成为你的合作伙伴
益博睿的悄然转型:从信用评级到云端AI
