
确保视频顺畅播放 麻省理工实验室研发了新的人工智能Pensieve 原创
至顶网软件频道消息:麻省理工学院计算机科学与人工智能实验室的一个研究人员团队开发了一种名为Pensieve的人工智能,可以使缓慢或模糊的网络视频成为过去。
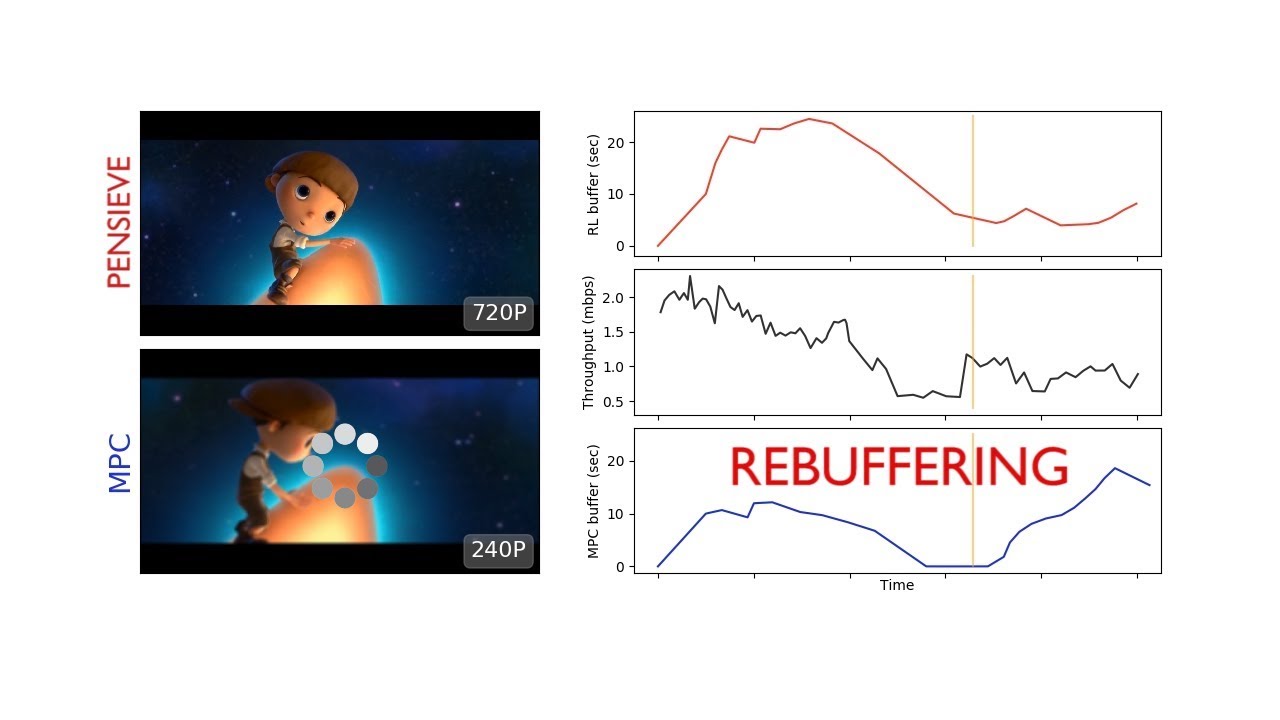
流媒体视频内容近年来一直在跨越式发展,但不幸的是它的带宽要求也呈现出跨越式的跃升。为了克服这个挑战,像YouTube或Netflix这样的视频平台使用了将视频分成更容易处理的块的算法。如果他们的系统检测到您的互联网速度减慢,下一个视频片段将以较低的分辨率播放,用这种方式努力追上播放进度。
该系统背后的思路是确保顺畅的视频播放,但有时即使是质量下降,视频仍然会暂停几秒钟,因为它试图缓冲下一个块。这是因为算法并不总是准确地预测下一个块应该使用什么分辨率。
这正是Pensieve的用武之地。麻省理工学院的研究人员使用一种奖励和惩罚系统来开发它,训练它来识别有效的缓冲技术。例如,只要成功播放完整的视频而不必重新缓存,Pensieve就可以得到奖励,如果视频质量低于某个阈值,它则可能会受到惩罚。
博士生Hongzi Mao是这篇描述了Pensieve流程和功能论文的主要作者,他表示,“通过查看过去实际的表现,它学习到不同的策略如何影响性能,它可以以更加强硬的方式改进其决策策略。”
根据研究小组的论文,Pensieve可以将视频流量比其他系统多减少10%至30%,用户将其“体验质量”评价为提高了10%至20%。
Mao表示,Pensieve具有足够的灵活性以适应不同的要求。例如,可以对其进行培训,可以以牺牲分辨率为代价保障视频连续播放,或者也可以进行相反的训练,让质量的优先级高于顺畅。
研究团队的下一个项目将是测试Pensieve在流媒体虚拟现实内容中的有效性,它需要高得多的带宽,并且对低质量的容忍度要低得多。
麻省理工学院的教授Mohammad Alizadeh(Mohammad Alizadeh)是Pensieve上这篇论文的一位合著者,他表示:“你需要的4K质量的VR可以轻松地达到每秒数百兆比特的速度,今天的网络根本无法支持”。他表示,“我们很高兴看到像Pensieve这样的系统能够为VR等技术所做的一切。这还只是第一步。”
好文章,需要你的鼓励


苹果在印度恢复银行卡支付功能,距暂停已逾四年
苹果已开始在印度分阶段恢复Apple账户的信用卡支付功能,用户可绑定Visa和Mastercard信用卡及借记卡,用于购买iCloud+、Apple Music订阅及App Store应用。此前,由于印度储备银行于2021年推出新的周期性支付监管框架,苹果于2022年5月暂停了该支付方式。此次恢复标志着苹果在适应各国本地化监管要求方面的持续努力,同时也引发外界对苹果是否将在印度推出Apple Pay的新猜测。

腾讯混元团队打破AI“记忆瓶颈“:让大模型像人一样拥有超长记忆的新突破
腾讯混元等机构提出HiLS-Attention,通过端到端可学习的分层稀疏注意力机制,让大模型在超长上下文推理中比全量注意力快14倍,同时检索准确率更高。

Bookshop.org确认今年将推出Kobo电子书阅读器支持
Bookshop.org创始人Andy Hunter证实,与Kobo的合作集成将于今年落地。此前该计划历经多次推迟,网页措辞一度从"2026年"改为"未来某时"。Hunter表示,双方已就商业条款达成一致,工程团队正将资源重新投入Kobo支持开发,但尚无具体上线日期。该集成将支持数字版权管理要求,让用户通过Bookshop.org购买电子书,同时支持独立书店。

DeepSeek-AI与北京大学联手破局:AI聊天机器人“慢速打字“的终极解决方案
DSpark是DeepSeek与北京大学提出的投机解码框架,通过半自回归生成和置信度调度验证两项创新,将DeepSeek-V4用户生成速度提升60%至85%。
2017
08/15
17:29
分享
点赞

苹果在印度恢复银行卡支付功能,距暂停已逾四年
Bookshop.org确认今年将推出Kobo电子书阅读器支持
WeWard新增"步行模式":走够步数才能解锁应用
X将通过私信通知用户其互动帖子被社区笔记纠错
"慢社交"应用Roost:让消息像真鸟一样飞行
Truecaller与印度电信监管机构就反垃圾电话规则展开公开交锋
Block与46州达成4500万美元和解,涉Cash App欺诈纠纷
欧盟威胁对Meta开出罚款,剑指Facebook和Instagram上瘾性设计
Disney+考虑推出免费流媒体内容层级
HyperTexting:将开放网络变成类社交媒体信息流的新应用
TV Time关闭之际,创始人打造新追剧应用Bingers
Telegram短链域名t.me因制裁合规问题短暂下线后已恢复
