
谷歌大脑主管:人工智能计算机视觉超越人类 医疗保健必将改观 原创
仅仅在五年前,人工智能计算机还基本上识别不了图像,更别说像人类一样分析图像。但突然之间,人工智能计算机已经超越了人类。
谷歌大脑(Google Brain)项目负责人Jeff Dean表示,“2011年,计算机识别图像的错误率为26%。”谷歌大脑与其他科技巨头一起在引领近期的图像识别以及语音识别及自驾车领域的革命中作出了自己的贡献。他表示,而现在,电脑查看和分析图像的能力超出了人眼所能做的事情。
Dean在德国海德堡举行的一次研究活动中表示,“如果你几年前告诉我能做得到这一步,我一定不会相信你。但由于人工智能(AI)计算机视觉的发展,电脑现在‘可以看了’……这也打开了我们的视野,让我们看到了更多可能性。”
在本周第五届海德堡获奖人论坛(HLF2017)上,探究AI和机器学习更多应用可能性是一个主要课题。HLF为世界上最有希望的年轻科学研究人员及经验丰富的计算机科学家和数学家提供了融合交流的机会,他们都是在自己领域里赢得了最高荣誉的研究人员。这些获奖人是计算ACM奖、图灵奖、Fields奖,亚伯奖和Nevanlinna奖的得主。

Google Brain负责人Jeff Dean
Dean因其在分布式系统方面的工作曾获2012年ACM计算奖。他是谷歌的奇人。Dean在HLF 2017上深刻综述了AI使能技术应用在改善医疗保健和医学研究上的成果。
AI用于医疗保健和医学研究是有其道理的。据最近的埃森哲报告资料显示,至2021年,AI医疗保健行业年增长率将达40%,预计2021年的医疗保健市场将达66亿美元。目前的医疗保健市场徘徊在6亿美元左右。
Dean在本周的HLF上概述了一系列有关AI医疗成果的信息:
癌症诊断
病理学家要负责阅读检测乳腺癌、前列腺癌和其他癌症的幻灯片和测试结果。尽管这些人是经过训练的,研究却表明,几个病理学家只能在大约42%的时间内在乳腺癌的诊断上取得一致。
Dean表示,有个深入学习研究项目用了谷歌现存的Inception深度学习工具和康奈尔大学的一些定制机制,该研究项目显示,这样得到的结果要好得多。
该研究结果是在2017年3月发布的。其研究报告称,Google Brain的AI医学研究小组用了数百种病理图像训练计算机的癌症检测,准确度水平达到接近90%。
X射线成像
瑞典两个月前的一项研究显示了类似的结果,颇令人鼓舞。该研究利用X射线诊断骨折。
在这项研究中,瑞典Karolinska研究所、皇家理工学院和丹德里德医院的研究人员发现,深度学习计算机视觉可以和骨科医生一样准确地发现骨折。领导这项研究的Karolinska研究所的Max Gordon写道,这证明AI网络的评估能力与人类专家相若,而且,我们希望能够通过高分辨率X射线图像获得更好的结果。“
Dean在谈到这项工作时表示,“计算机视觉和AI技术即将从根本上改变”医疗诊断。他表示,这对病人的影响几乎是即时的。
计算机视觉与糖尿病视网膜病变
糖尿病视网膜病变(DR)是一个很好的例子。糖尿病视网膜病变如果能及早发现就可以很好地得到治疗。但如果错过及早发现的时机,此疾病可导致视力丧失甚至失明。根据亚特兰大疾病控制中心的数据,全球有4亿人面临DR风险。
研究表明,问题的症结在于,即便是训练有素的眼科医生要诊断出DR都有困难。Dean表示,“如果找两位经专业认证的眼科医生对健康的眼睛和患DR眼睛的图像进行诊断(见下图),四轮下来,只有60%的时间里他们的诊断是一致的。而两个小时后, 65%的时间里他们的诊断是一致的。“
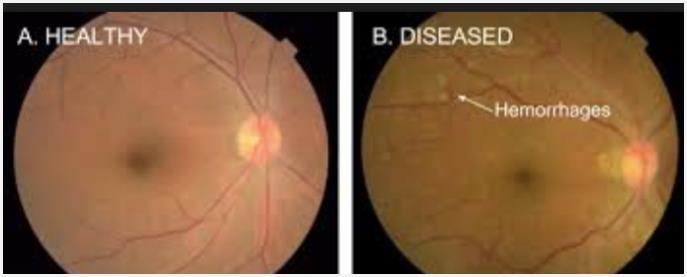
糖尿病性视网膜病变诊断的图像比对(左:健康;右:患DR病)图片来自谷歌
Dean补充表示,“有点恐怖”, 但却适合用AI方法迎接挑战。他表示,“假若这些新的计算机视觉系统可以在认别猫狗差异时达到人类的准确度,那么这些计算机视觉系统应该在识别”各种与医疗有关的东西时派上用场。
研究人员为AI系统提供了15万张眼睛图像,研究结果显示,AI系统的AI软件最终的诊断准确度水平超过人类。
展望未来
AI应用在医疗保健领域的其可能性可以列一个很长的表。Dean表示,从发现药物、整体患者护理到绘制人脑的突触连接等等,AI将很快改变数百万计人的医疗保健和治疗。谷歌并不是该领域的唯一玩家。 IBM公司Watson团队、微软的AI研究人员以及Facebook公司都在研发AI健康算法和解决方案。
许多诸如特斯拉公司首席执行官埃伦·穆斯克(Elon Musk)的科技领军人物曾对人工智能可能失控而威胁到人类表示担心。有关的辩论短时间内还要热闹一阵,至少会持续到科技奇点(Singularity,参看https://en.wikipedia.org/wiki/Technological_singularity)到达之前。但对于那些更加关心生活质量的人来说,很显然,他们从Dean本周带来的信息里看到了更多的希望。
来源:siliconANGLE
好文章,需要你的鼓励


豪声电子泰国电声工厂初步投产:2500万泰铢项目进入产能爬坡
今天讲的出海案例是生产微型扬声器、受话器和音响产品的豪声电子,其计划投资2500万泰铢的泰国音响类电声工厂已经进入初步投产阶段。

马萨诸塞大学的研究者们证明了:搜索引擎的“比较策略“在数学上优于传统方法
马萨诸塞大学从数学角度证明,MaxSim评分策略在理论能力上超越传统单向量内积方法,并提出Signed MaxSim扩展,显著改善否定查询性能。


新加坡国立大学与英伟达研究院联手打破视频生成的“非此即彼“困局:一个模型,两种能力,任意切换
新加坡国立大学与英伟达联合提出Flex-Forcing框架,通过时间帧和去噪步骤两个维度的灵活分块,将双向扩散和自回归视频生成统一到单一模型中,实现质量与效率的自由权衡。
2017
09/29
17:15
分享
点赞

“驯服”千亿模型,鏖战“黑猴打瓦”,龙虾“一键接管” ,锐龙AI Max+ 395开启全能桌面AI主机“王炸”时刻
豪声电子泰国电声工厂初步投产:2500万泰铢项目进入产能爬坡
地瓜机器人将560TOPS端侧算力,加载到了20+头部团队机器人中
WAIC 2026主论坛(下午场)重磅揭晓!
AI评测初创公司Braintrust遭入侵,敦促所有客户轮换API密钥
牙科诊所软件漏洞修复:患者医疗记录曾遭泄露
关键基础设施巨头Itron确认遭遇网络攻击
Vercel数据泄露范围扩大,黑客早于已知时间节点已入侵
苹果与博通签署300亿美元协议,共同生产美国本土无线芯片
摩托罗拉领投BRINC 1.25亿美元,推动紧急救援无人机大规模扩张
AI赋能芯片设计:前景广阔,疑问犹存
Arm今夏将推出自研芯片,Meta成首批客户
