
微软人工智能又一里程碑:微软中-英机器翻译水平可“与人类媲美”
至顶网软件频道消息: 继在语音识别和机器阅读领域取得的“过人”成绩,由微软亚洲研究院与雷德蒙研究院的研究人员组成的团队今天宣布,其研发的机器翻译系统在通用新闻报道测试集newstest2017的中-英测试集上,达到了可与人工翻译媲美的水平。这是首个在新闻报道的翻译质量和准确率上可以比肩人工翻译的翻译系统。
newstest2017新闻报道测试集由产业界和学术界的合作伙伴共同开发,并于去年秋天在WMT17大会上发布。为了确保翻译结果准确且达到人类的翻译水平,微软研究团队邀请了双语语言顾问将微软的翻译结果与两个独立的人工翻译结果进行了比较评估。
微软技术院士,负责微软语音、自然语言和机器翻译工作的黄学东称,这是对自然语言处理领域最具挑战性任务的一项重大突破。“在机器翻译方面达到与人类相同的水平是所有人的梦想,我们没有想到这么快就能实现。”他表示,“消除语言障碍,帮助人们更好地沟通,这非常有意义,值得我们多年来为此付出的努力。”

微软技术院士黄学东
机器翻译是科研人员攻坚了数十年的研究领域,曾经很多人都认为机器翻译根本不可能达到人类翻译的水平。虽然此次突破意义非凡,但研究人员也提醒大家,这并不代表人类已经完全解决了机器翻译的问题,只能说明我们离终极目标又更近了一步。微软亚洲研究院副院长、自然语言计算组负责人周明表示,在WMT17测试集上的翻译结果达到人类水平很鼓舞人心,但仍有很多挑战需要我们解决,比如在实时的新闻报道上测试系统等。
微软机器翻译团队研究经理Arul Menezes表示,团队想要证明的是:当一种语言对(比如中-英)拥有较多的训练数据,且测试集中包含的是常见的大众类新闻词汇时,那么在人工智能技术的加持下机器翻译系统的表现可以与人类媲美。
跨时区跨领域合作,四大技术为创新加持
虽然学术界和产业界的科研人员致力于机器翻译研究很多年,但近两年深度神经网络的使用让机器翻译的表现取得了很多实质性突破,翻译结果相较于以往的统计机器翻译结果更加自然流畅。为了能够取得中-英翻译的里程碑式突破,来自微软亚洲研究院和雷德蒙研究院的三个研究组,进行了跨越中美时区、跨越研究领域的联合创新。
其中,微软亚洲研究院机器学习组将他们的最新研究成果——对偶学习(Dual Learning)和推敲网络(Deliberation Networks)应用在了此次取得突破的机器翻译系统中。微软亚洲研究院副院长、机器学习组负责人刘铁岩介绍道,“这两个技术的研究灵感其实都来自于我们人类的做事方式。”对偶学习利用的是人工智能任务的天然对称性。当我们将其应用在机器翻译上时,效果就好像是通过自动校对来进行学习——当我们把训练集中的一个中文句子翻译成英文之后,系统会将相应的英文结果再翻译回中文,并与原始的中文句子进行比对,进而从这个比对结果中学习有用的反馈信息,对机器翻译模型进行修正。而推敲网络则类似于人们写文章时不断推敲、修改的过程。通过多轮翻译,不断地检查、完善翻译的结果,从而使翻译的质量得到大幅提升。对偶学习和推敲网络的工作发表在NIPS、ICML、AAAI、IJCAI等人工智能的全球顶级会议上,并且已被其他学者推广到机器翻译以外的研究领域。

微软亚洲研究院副院长、机器学习组负责人刘铁岩
周明带领的自然语言计算组多年来一直致力于攻克机器翻译,这一自然语言处理领域最具挑战性的研究任务。周明表示,“由于翻译没有唯一的标准答案,它更像是一种艺术,因此需要更加复杂的算法和系统去应对。”自然语言计算组基于之前的研究积累,在此次的系统模型中增加了另外两项新技术:联合训练(Joint Training)和一致性规范(Agreement Regularization),以提高翻译的准确性。联合训练可以理解为用迭代的方式去改进翻译系统,用中英翻译的句子对去补充反向翻译系统的训练数据集,同样的过程也可以反向进行。一致性规范则让翻译可以从左到右进行,也可以从右到左进行,最终让两个过程生成一致的翻译结果。

微软亚洲研究院副院长、自然语言计算组负责人周明
可以说,两个研究组分别将各自所在领域的积累与最新发现应用在了此次的机器翻译系统中,从不同角度切入,让翻译质量大幅提升。在项目合作过程中,他们每周都会与雷德蒙总部的团队开会讨论,确保技术可以无缝融合,系统可以快速迭代。
没有“正确的”翻译结果
newstest2017新闻报道测试集包括约2000个句子,由专业人员从在线报纸样本翻译而来。微软团队对测试集进行了多轮评估,每次评估会随机挑选数百个句子翻译。为了验证微软的机器翻译是否与人类的翻译同样出色,微软没有停留在测试集本身的要求,而是从外部聘请了一群双语语言顾问,将微软的翻译结果与人工翻译进行比较。
验证过程之复杂也从另一个侧面体现了机器翻译要做到准确所面临的复杂性。对于语音识别等其它人工智能任务来说,判断系统的表现是否可与人类媲美相当简单,因为理想结果对人和机器来说完全相同,研究人员也将这种任务称为模式识别任务。
然而,机器翻译却是另一种类型的人工智能任务,即使是两位专业的翻译人员对于完全相同的句子也会有略微不同的翻译,而且两个人的翻译都不是错的。那是因为表达同一个句子的“正确的”方法不止一种。 周明表示:“这也是为什么机器翻译比纯粹的模式识别任务复杂得多,人们可能用不同的词语来表达完全相同的意思,但未必能准确判断哪一个更好。”
复杂性让机器翻译成为一个极有挑战性的问题,但也是一个极有意义的问题。刘铁岩认为,我们不知道哪一天机器翻译系统才能在翻译任何语言、任何类型的文本时,都能在“信、达、雅”等多个维度上达到专业翻译人员的水准。不过,他对技术的进展表示乐观,因为每年微软的研究团队以及整个学术界都会发明大量的新技术、新模型和新算法,“我们可以预测的是,新技术的应用一定会让机器翻译的结果日臻完善。”
研究团队还表示,此次技术突破将被应用到微软的商用多语言翻译系统产品中,从而帮助其它语言或词汇更复杂、更专业的文本实现更准确、更地道的翻译。此外,这些新技术还可以被应用在机器翻译之外的其他领域,催生更多人工智能技术和应用的突破。
延伸阅读:
对偶学习(Dual Learning):对偶学习的发现是由于现实中有意义、有实用价值的人工智能任务往往会成对出现,两个任务可以互相反馈,从而训练出更好的深度学习模型。例如,在翻译领域,我们关心从英文翻译到中文,也同样关心从中文翻译回英文;在语音领域,我们既关心语音识别的问题,也关心语音合成的问题;在图像领域,图像识别与图像生成也是成对出现。此外,在对话引擎、搜索引擎等场景中都有对偶任务。
一方面,由于存在特殊的对偶结构,两个任务可以互相提供反馈信息,而这些反馈信息可以用来训练深度学习模型。也就是说,即便没有人为标注的数据,有了对偶结构也可以做深度学习。另一方面,两个对偶任务可以互相充当对方的环境,这样就不必与真实的环境做交互,两个对偶任务之间的交互就可以产生有效的反馈信号。因此,充分地利用对偶结构,就有望解决深度学习和增强学习的瓶颈——训练数据从哪里来、与环境的交互怎么持续进行等问题。
论文地址:https://papers.nips.cc/paper/6469-dual-learning-for-machine-translation.pdf
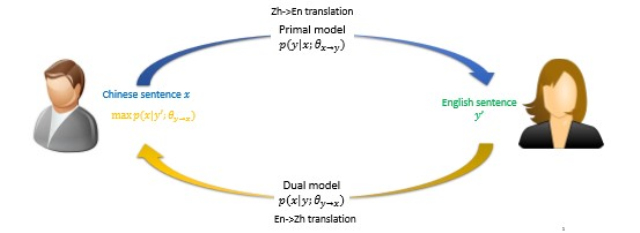
对偶无监督学习框架
推敲网络(Deliberation Networks):“推敲”二字可以认为是来源于人类阅读、写文章以及做其他任务时候的一种行为方式,即任务完成之后,并不当即终止,而是会反复推敲。微软亚洲研究院机器学习组将这个过程沿用到了机器学习中。推敲网络具有两段解码器,其中第一阶段解码器用于解码生成原始序列,第二阶段解码器通过推敲的过程打磨和润色原始语句。后者了解全局信息,在机器翻译中看,它可以基于第一阶段生成的语句,产生更好的翻译结果。
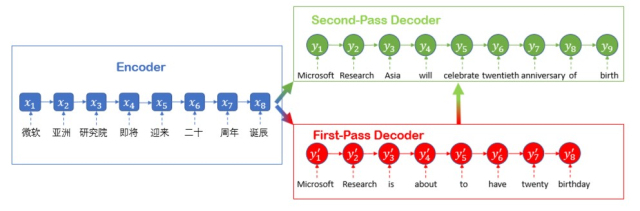
推敲网络的解码过程
联合训练(Joint Training):这个方法可以认为是从源语言到目标语言翻译(Source to Target)的学习与从目标语言到源语言翻译(Target to Source)的学习的结合。中英翻译和英中翻译都使用初始并行数据来训练,在每次训练的迭代过程中,中英翻译系统将中文句子翻译成英文句子,从而获得新的句对,而该句对又可以反过来补充到英中翻译系统的数据集中。同理,这个过程也可以反向进行。这样双向融合不仅使得两个系统的训练数据集大大增加,而且准确率也大幅提高。
论文地址:https://arxiv.org/pdf/1803.00353.pdf
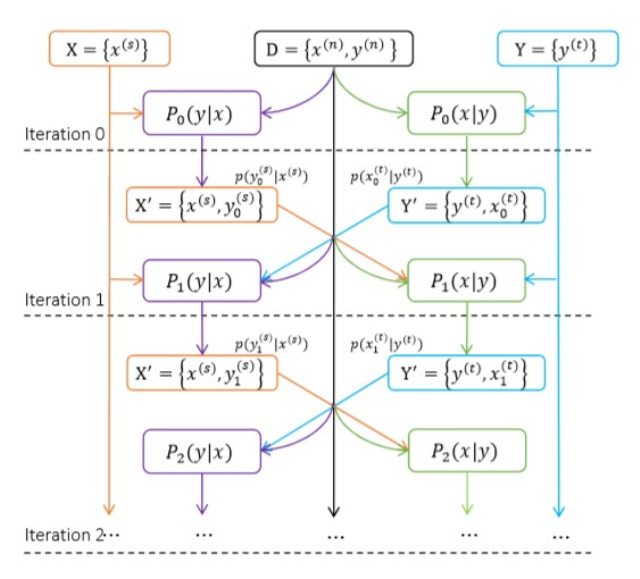
联合训练:从源语言到目标语言翻译(Source to Target)P(y|x) 与从目标语言到源语言翻译(Target to Source)P(x|y)
一致性规范(Agreement Regularization):翻译结果可以从左到右按顺序产生,也可以从右到左进行生成。该规范对从左到右和从右到左的翻译结果进行约束。如果这两个过程生成的翻译结果一样,一般而言比结果不一样的翻译更加可信。这个约束,应用于神经机器翻译训练过程中,以鼓励系统基于这两个相反的过程生成一致的翻译结果。

一致性规范:从左到右 和从右到左
好文章,需要你的鼓励


苹果在印度恢复银行卡支付功能,距暂停已逾四年
苹果已开始在印度分阶段恢复Apple账户的信用卡支付功能,用户可绑定Visa和Mastercard信用卡及借记卡,用于购买iCloud+、Apple Music订阅及App Store应用。此前,由于印度储备银行于2021年推出新的周期性支付监管框架,苹果于2022年5月暂停了该支付方式。此次恢复标志着苹果在适应各国本地化监管要求方面的持续努力,同时也引发外界对苹果是否将在印度推出Apple Pay的新猜测。

腾讯混元团队打破AI“记忆瓶颈“:让大模型像人一样拥有超长记忆的新突破
腾讯混元等机构提出HiLS-Attention,通过端到端可学习的分层稀疏注意力机制,让大模型在超长上下文推理中比全量注意力快14倍,同时检索准确率更高。

Bookshop.org确认今年将推出Kobo电子书阅读器支持
Bookshop.org创始人Andy Hunter证实,与Kobo的合作集成将于今年落地。此前该计划历经多次推迟,网页措辞一度从"2026年"改为"未来某时"。Hunter表示,双方已就商业条款达成一致,工程团队正将资源重新投入Kobo支持开发,但尚无具体上线日期。该集成将支持数字版权管理要求,让用户通过Bookshop.org购买电子书,同时支持独立书店。

DeepSeek-AI与北京大学联手破局:AI聊天机器人“慢速打字“的终极解决方案
DSpark是DeepSeek与北京大学提出的投机解码框架,通过半自回归生成和置信度调度验证两项创新,将DeepSeek-V4用户生成速度提升60%至85%。
2018
03/15
09:29
分享
点赞

苹果在印度恢复银行卡支付功能,距暂停已逾四年
Bookshop.org确认今年将推出Kobo电子书阅读器支持
WeWard新增"步行模式":走够步数才能解锁应用
X将通过私信通知用户其互动帖子被社区笔记纠错
"慢社交"应用Roost:让消息像真鸟一样飞行
Truecaller与印度电信监管机构就反垃圾电话规则展开公开交锋
Block与46州达成4500万美元和解,涉Cash App欺诈纠纷
欧盟威胁对Meta开出罚款,剑指Facebook和Instagram上瘾性设计
Disney+考虑推出免费流媒体内容层级
HyperTexting:将开放网络变成类社交媒体信息流的新应用
TV Time关闭之际,创始人打造新追剧应用Bingers
Telegram短链域名t.me因制裁合规问题短暂下线后已恢复
最热门的 AI 模型:它们的功能和使用方法
这款古怪的 AI 智能手机可以创建你的数字分身
Faireez 获 750 万美元融资,为租赁市场提供 AI 驱动的酒店式管家服务
Broadcom 大获全胜:70% 大型 VMware 客户购买其最全面解决方案
Peer 获得1050万美元元宇宙引擎投资,推出3D个人星球功能
获 3000 万美元融资,Crogl 发布面向安全分析师的全新 AI "钢铁侠战衣"
Turing 获得 1.11 亿美元融资,估值达到 22 亿美元,为 OpenAI 等大语言模型公司提供关键代码支持
Tavus 推出系列 AI 模型,实现实时人脸交互技术突破
Welevel 获得 570 万美元融资,革新程序化游戏开发
AI 驱动的卓越运营:企业如何通过人人可及的流程智能提升成功
