
当心!医疗AI系统极易引发欺诈与错误状况
来自哈佛大学的研究人员们已经在arXiv上发表了一篇论文,其中展示了首例对医疗系统的操纵方法。此项研究的第一作者Sam Finlayson及其同事Andrew Beam、Isaac Kohane在图像识别模型当中使用投射梯度下降(简称PGD)攻击,旨在误导AI系统以使其得出并不存在于图像中的结论。

PGD算法能够从图像当中找出最理想的像素以创建对抗性示例,而这些示例将推动模型作出错误的对象识别结论,最终引发诊断错误。
该团队在三种数据处理方案当中测试了这一攻击手段:首先是用于检测视网膜扫描结果以诊断糖尿病视网膜病变的眼底检查模型; 另一种为扫描胸腔x光片以查看肺萎缩症状的模型; 最后则是用于检查痣中皮肤癌征兆的皮肤镜模型。
为了增加测试范围,该团队还使用了两种技术。首先是白盒攻击,即假定黑客已经拥有用于解释模型工作方式的所有资源; 接下来是黑盒攻击,即假定黑客无法理解AI模型的起效原理。
在应用PGD算法之后,所有三种模型的准确性水平都在白盒攻击之下由极高下降为零; 黑盒攻击同样能够将准确度降低超过60%。
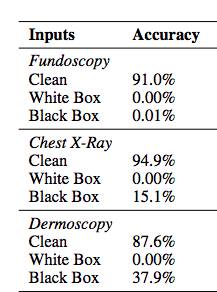
白盒与黑盒PGD攻击前后,三种不同图像分类模型的准确性水平。
Finlayson与Beam在接受采访时解释称,PGD攻击能够进行多次迭代,从而对修改过的图像作出进一步微调。虽然调整结果很难被人类所分辨,但却可以有效愚弄AI系统甚至导致其对某些对象视而不见。
“令人惊讶的是,这一过程导致的变化往往非常细微,以至于人眼根本无法识别。但在另一方面,神经网络会认为图像中包含着完全不同的内容。”
人工智能——聪明,但又令人难以置信的愚蠢
众所周知,图像识别模型极易受到愚弄。举例来说,对于一张经过精心设计的对抗性海报,这类模型会将其中极为明显的香蕉误认为为烤面包机。而在实践场景下,这意味着自动驾驶汽车可能会误读标志,或者面部识别系统无法正确判断人脸信息。
这篇论文指出,医学领域“可能会受对抗性攻击受到特殊影响,且这类恶意行为往往存在着显著的动机——包括经济刺激及技术漏洞等。”
目前,大多数效能最出色的图像分类器普遍利用ImageNet等开源模型构建而成。这意味着攻击者对于系统的工作原理可以具备良好的认知,并更有可能以此为基础成功攻击其它AI模型。
当人工智能技术被引入临床环境之后,我们无法确定未来的医学专业人员还需要掌握多少深厚的专业知识。但就目前来讲,Finlayson与Beam表示此类对抗性攻击主要属于探索性研究。
并解释称,“大家需要对数学及神经网络具备一定了解,才能正确构建起对抗性示例。然而,整个流程可以轻松实现自动化,并通过应用程序或网站进行发布,以便非专家们随时加以利用。”
另外,研究团队希望这项研究能够激励从业者们更积极地研究相关议题,进而发现一切可能的基础设施防御措施,最终以更安全的方式利用图像识别为病患以及医护人员服务。
好文章,需要你的鼓励


遭黑客入侵的Klue称犯罪分子正在删除窃取的客户数据,但新的黑客组织接连发出威胁
市场研究公司Klue本月初遭黑客入侵,大量客户数据被窃。Klue表示正与黑客组织Icarus沟通,并相信对方正在删除所盗数据。受影响客户包括Gong、LastPass、HackerOne等多家知名企业。然而事态趋于复杂——另一黑客团伙声称从Icarus处获取了Klue客户数据,并向客户发出勒索威胁。Klue提醒客户勿向第二方支付赎金,并建议索取数据样本以核实其真实性。

机械手臂终于学会“看深度“了——KAIST联合POSTECH研究团队让机器人规划与执行真正说同一种语言
KAIST等机构提出3D HAMSTER,通过为视觉语言模型加入深度编码器和几何重建损失,让机器人规划器直接输出三维轨迹,解决了分层机器人系统中规划与执行的维度不匹配问题,显著提升了操作鲁棒性。

苹果起诉OpenAI窃密:前员工利用零日漏洞下载机密文件
苹果公司对OpenAI提起诉讼,指控其窃取商业机密。据披露,前苹果系统电气工程师刘畅(Chang Liu)在离职加入OpenAI后,利用一个此前未知的身份验证零日漏洞,持续数周从苹果内部网络存储中下载大量机密文件,内容涵盖未发布产品信息、工程演示文稿及技术规格等。苹果已修复该漏洞并终止相关访问权限。此案已提交加州北区联邦法院,并要求陪审团审判。

南京大学团队打造的“轻量AI视频助理“:不用反复推理,一眼就能看懂你的过去
南京大学提出Light-Omni框架,通过全局状态与潜在状态双机制,让AI视频助理无需反复推理即可实现精准记忆检索,速度提升逾12倍,准确率同步提高。
2018
04/20
10:50
分享
点赞

Whatnot收购AI推荐公司Shaped,强化直播购物实时个性化能力
ELIZA:首个聊天机器人背后的多重人格与隐藏秘密
研究显示特斯拉LFP电池健康度表现优于镍基电池
苹果携手阿里云通义千问,Apple Intelligence获批在华上线
微软借助AI发现漏洞,单次发布破纪录的570个安全补丁
AI音乐生成器Suno遭入侵,疑从YouTube抓取训练数据
OpenAI首款品牌硬件亮相:RGB迷你键盘助力Codex智能体监控
PrivadoVPN 推出 MCP 服务器,让 AI 智能体直接管理你的 VPN 连接
Stripe与Advent据报出价约534亿美元联合收购PayPal
微软裁员背后的AI影响:你需要了解什么
Ode with Anthropic:押注AI服务成为企业级市场未来
用Gemini几分钟规划你的暑期旅行
