
【DTCC 2018】为云而生!解密华为 Cloud Native 分布式数据库
至顶网软件频道消息: 5月11日,第九届中国数据库技术大会(DTCC 2018)在北京国际会议中心如火如荼的进行。作为国内数据库领域规模最大、最受欢迎的技术交流盛会,本次大会聚集众多顶尖专家,共同探讨了互联网、金融、教育等行业领先的数据库技术与未来趋势。
经过一天发酵,大会热烈浓厚的技术讨论氛围在今日到达顶峰。金融作为当下最热行业之一,数据库在该领域的实践和应用一直备受关注。本次大会上,华为云数据库专家带来《华为 Cloud Native 分布式数据库技术》主题演讲,不但介绍了金融行业数据库技术的演进过程,而且重点剖析其技术原理,广受各方关注。
近来,Fintech(金融科技)正成为大家耳熟能详的词汇。而当金融遇上云计算,可以说将真正把 Fintech 发挥到极致。中国信息通信技术院 2018年《金融行业云计算技术调查报告》显示:
近九成金融机构已经或正计划应用云计算技术,近1/3已经使用云计算技术的金融机构部署了小规模以上的虚拟服务器。金融机构应用云计算技术最主要的目的,是缩短应用部署时间、节约成本和业务升级不中断。服务安全性和可持续性,则是金融机构对云计算技术最主要的要求。
数据库方面,金融机构主要应用 Oracle、DB2、MySQL 和 PostgreSQL。其中 Oracle占比 62.61%,DB2 占比 21.80%,MySQL 占比15.23%,PostgreSQL 占6.76%。其他占比7.88%。
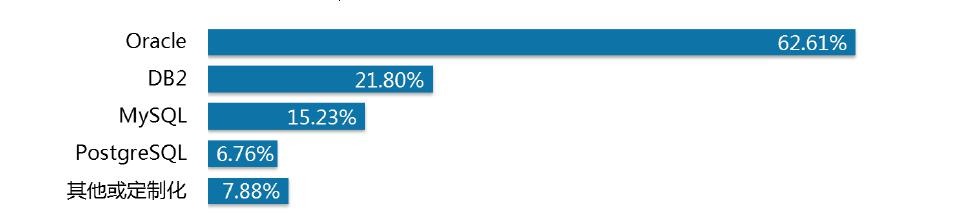
数据库技术在金融机构的应用情况(数据来源:中国信息通信技术院)
华为云数据库作为领先的云服务品牌,与金融行业的关系可谓历久弥新。早在2017年11月,招商银行就与华为成立分布式数据库联合创新实验室,实践云上金融科技变革。双方共同应对“CloudFirst”的挑战,利用云、大数据、人工智能先进技术,领先的金融业务实践和优秀资源,联接业务与技术,联合进行分布式数据库技术的研发和产品应用,解决数据库应用上云问题。
华为是招商银行最重要的 IT 合作公司之一,之前就有很多合作,而这次基于云数据库的合作,华为云更是助力招商银行加速数字化转型,成为“金融科技银行”。招商银行通过科技变革,为客户提供普惠、个性化、智能化的金融服务。

招商银行和华为公司成立分布式数据库联合创新实验室
在今天的大会上,招商银行数据库架构师周伟作了《招行 Fintech 数据开放平台之内功修炼》的主题分享,介绍了这一轮 Fintech 浪潮下,如何以数据和技术为核心驱动力,结合互联网和创业外部视角重新梳理金融行业的业务,以及在去中心化和高并发密集运算新形势下,数据架构该如何设计和应对。
几乎在同一时间的同一专场里,华为云数据库专家分享的《华为 Cloud Native 分布式数据库技术》主题演讲,也不约而同介绍了云时代下企业如何基于云场景架构设计具备跨地区分布式部署的数据库,介绍了 Cloud Native 分布式数据库高可靠、高性能、易扩展等金融级的关键特性,并深入揭开其背后的技术内幕。
Cloud Native 分布式数据库,是相较传统 RDBMS(关系型数据库管理系统)而言的一种高可用数据库。为什么说是高可用呢?这还得从传统 RDBMS 说起。过去三十多年间,计算平台基本是在一台 PC、一个服务器、或者一个手机这样独立的硬件上搭建,因此有单处理器、小内存、慢速硬盘等特点。
云时代的到来,使得无论传统行业还是互联网行业,业务越来越多样,迭代速度越来越快,使得整体数据量大幅提升。IOT设备、手机、移动互联网的蓬勃发展,终端也不再仅是传统 PC 客户端数据的接入。AI、大数据分析模型理论上的突破,让计算手段越来越多样。各式新物理设备的出现、存储成本的持续降低,使得数据库需要面对更多挑战。
传统数据库无论在高可用性、还是成本方面,都很难应对这些挑战。比如,传统数据库主备之间,通过异步或半同步方式进行数据同步。一旦主数据库实例发生故障导致不可用,该架构就很难在短时间内将服务切换到备数据库实例上。
随着业务数据量不断地增大,数据库在性能和容量方面的提升,往往只能依赖硬件的提升来解决。不但成本很高,操作复杂,而且很难做到业务不中断。因此,具备高性能、高可靠、能弹性伸缩的分布式数据库应运而生,且将成为趋势。
国际著名市场分析机构 Gartner 调查显示,到2019年,90%的云数据库管理系统架构,将支持计算和存储的分离,这与市场的需求也息息相关。
以金融行业云为代表的新时代数据库,需要整个系统的高安全性, 高可靠性、高可用性、高性能, 可扩展能力,以及运维自动化。分布式数据库如何满足这些需求呢?或许我们可以从华为 Cloud Native 分布式数据库系统中找到答案。
我们先来了解华为 Cloud Native 分布式数据库的设计原理。首先是 Near Data Process,即将与数据相关性较大的业务逻辑卸载到存储层,减轻计算负担。比如对 redo 日志的处理、配置的构建等。
华为 Cloud Native 分布式数据库利用云存储提供的特有功能,比如云存储的容错能力和快速自我修复能力,提升数据库服务的可用性和数据的可靠性。而且充分利用云存储多租户共享的能力,持续降低数据库成本。
此外,华为 Cloud Native 分布式数据库与云上各种技术垂直整合,解决了线下传统数据库的问题和痛点。例如避免随机写入 SSD 以减少磨损,利用 SSD 的超高随机读取性能,同时结合云存储的自我修复能力,既提升数据库整体性能,也让其拥有更高可靠性。
计算与存储分离以后,数据库达到高性能的关键点不再是传统的数据处理,而是网络。华为 Cloud Native 分布式数据库通过数据优化,减少通讯量,同时利用先进的网络技术(如 RDMA),降低网络的时延,提升网络吞吐。
华为 Cloud Native 分布式数据库还利用 AI 和 ML 中的先进技术实现系统自治,让数据库实现自动扩容,自我调节,从而满足用户的弹性需求。
基于以上原理,华为不但在原生DB引擎方面对开源数据库和商业数据库进行安全加固、服务化,推出云数据库 MySQL、PostgreSQL、SQL Server、文档数据库等服务;而且优化DB引擎,基于原生开源版本的 MySQL,进行了内核源码级优化,推出性能大幅提升 3倍以上,复制延迟大幅降低至20秒内的云数据库 HWSQL,并且近期将发布自研的企业级分布式数据库。

华为云数据库服务全景图
取得这样优异的成绩,是因为华为云突破了数据库引擎内核的关键技术,包括 IO 卸载技术,缓解磁盘IO压力;多个事务的日志打包提交,减少网络IO数量;请求异步并行化,有效利用多核资源。此外,华为云还在云上将数据库软件和底层硬件垂直整合,在网络领域使用用户态网络协议栈技术,在存储领域使用高性能虚拟化存储,高性能存储IO,有效隔离租户数据,保障安全。
由此可见,以华为云Cloud Native 分布式数据库为代表的新型云数据库,正是为金融级
高安全、高可靠、高可用、高性能、高可扩展以及运维自动化等需求量身定做的。
好文章,需要你的鼓励


“借道”MoP封装,AMD打破“存储墙”与“空间锁”
AMD 最近推出了第二代 AMD Versal Premium MoP(Memory on Package,封装上内存)自适应SoC。

Upstage AI研究员揭示:当AI被要求填写一张完整的表格,它究竟在哪里翻车了?
Upstage AI构建韩语宽度搜索基准KO-WIDESEARCH,测试20个AI系统填写完整结构化表格的能力,揭示AI善于找成员却难以填对每格的核心缺陷。


阿里巴巴让AI图像生成模型“自我进化“:Qwen-Image-2.0-RL是如何让机器学会审美的?
阿里Qwen团队通过引入强化学习和在线策略蒸馏,将Qwen-Image-2.0升级为Qwen-Image-2.0-RL,让图像生成模型真正学会人类审美,文生图Elo评分提升78分,图像编辑提升93分。
2018
05/11
19:39
分享
点赞

优必选万台超仿生人形机器人,要在今年进家庭?
Albertsons借助Databricks构建零售商品智能决策平台
微软正式将 Windows 11 打造为 AI 操作系统
工作中使用未授权AI工具之前,请三思
全球首座AI博物馆Dataland:用数据创造多感官视觉盛宴
ANS框架:Linux基金会为AI智能体建立DNS式信任机制
Origin PC Millennium台式机评测:构建出色但配置并非最优选择
Hirebotics推出无代码防爆协作机器人,专为工业喷涂设计
美国消费品安全委员会拟出台电动自行车电池安全新规
江波龙:建设完成mSSD月产能百万交付能力!mSSD高速存储介质赋能端侧AI规模应用
从IO500双榜第一,看国产存储的系统级突破
Rocket Lab宣布以80亿美元收购卫星运营商铱星公司
智简融媒 创新视听|华为助力传媒行业发展新质生产力
华为 Mate X6 折叠屏手机外观公布开启预定,26 日同期发布
万余款数智产品、上千场全国行动 华为联手上万家伙伴启动第三届828 B2B企业节
华为如何抓住全闪化百亿市场新机遇?
闪存普惠,一步到位 华为正式发布极简全闪数据中心暨伙伴先锋行动
华为发布园区网络“光进铜退”先锋行动 ——将投入5000万元营销资源支持新老伙伴共赢园区数智新未来
华为老将余承东,字典里没有躺平
新商机|新标配|新支持,园区网络光进铜退先锋行动发布会
华为发布星河AI网络解决方案,携手全球伙伴共同倡议加快Net5.5G产业演进发展
华为陈帮华:打造F5G-A高品质运力网,形成“全国一台计算机”
