
如何利用机器学习了解人体免疫系统?
至顶网软件频道消息:把你的免疫反应看作是一个巨大的机器学习问题,你的身体就是计算机。
免疫细胞在你的身体中移动,对它们接触到的各种物质进行取样,从你自己的细胞,到绝对不应该存在的有机体细胞。如果免疫细胞遇到的东西不应该是你身体的一部分——例如细菌或病毒——那么身体会出动哪些知道如何对付这些闯入者的细胞。
如果有细胞之前曾经见过这个入侵者,知道如何处理它的话,那么你的身体会迅速繁殖这个细胞数千次——多到足以让它可以在有时间驻扎到你全身之前压制住细菌或病毒。一旦入侵者被驱逐,免疫系统就会再次减少这些细胞的数量,保持足够的储备——万一细菌卷土重来——有足够的免疫步兵再次击溃这些入侵者。
这个过程可以帮助你保持健康,也可能是让医生更早地发现患者疾病的关键——借助以云计算为动力的人工智能。
今年早些时候,微软宣布与位于西雅图的健康技术和基因测序公司Adaptive Biotechnologies达成合作,Adaptive Biotechnologies的基因测序仪目前用于检测残余骨髓瘤——也就是说,细胞会显示已经接受血癌治疗的人的细胞并非完全没有这种疾病。
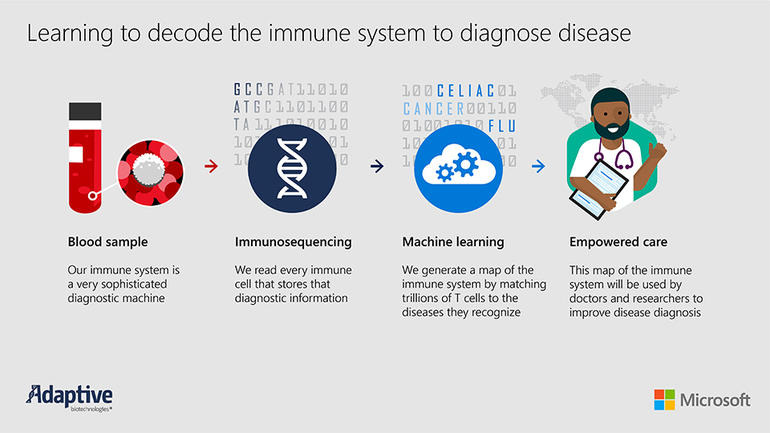
现在,该公司正在考虑的不仅仅是追踪一种疾病,目标是确定检测任何可能让你免疫系统遭受重创的东西,从感染到癌症,而且依靠微软的机器学习功能来帮助它达到这一目标的。
人体免疫系统的功能非常强大,人体体内有二十亿个淋巴细胞,其中称为‘辅助’T细胞,其他是‘细胞毒素’或者‘杀伤性’T细胞。
每个T细胞都可以识别抗原——也就是免疫系统的触发因素——这些抗原显示进入人体的细菌、病毒、真菌或其他入侵者。每个T细胞可以结合数百种不同的抗原,每种抗原对于不同的细菌或病毒都是独有的。
一旦T细胞受到打击,(取决于T细胞的类型)它可能会杀死入侵者,或者向数百万其他免疫细胞发出信号,让这些细胞过来攻击入侵者。当T细胞被激活时,对免疫系统进行快照,通过注意到哪些T细胞受体被激活以及哪些抗原与其结合,可以确定哪种疾病已经侵入了人体。而且,一旦确定了疾病,医生就可以更清楚地知道如何进行治疗。
Adaptive Biotechnologies 成立于2009年,致力于读取和扫描免疫系统和免疫细胞上的受体。随着时间的推移,该公司不仅追踪免疫受体,而且也开始研究受体与其结合的抗原之间的联系。通过研究这种约束关系,Adaptive Biotechnologies开始朝着能够诊断来自免疫受体的特定疾病的方向努力着。
但随后,根据Adaptive Biotechnologies首席执行官、联合创始人Chad Robins的说法,他们意识到“我们需要非常复杂的机器学习和计算能力才能真正解决问题——这是Web体量的一个大问题。”
微软人工智能与研究副总裁Peter Lee指出,每个人的基因组大约有200GB:“这仅仅是基因组数据——用于提取的元数据,以及来自成像、可穿戴设备、(与人口规模的基因组数据关联的)患者纵向健康记录的数据来源,是非常巨大的。信息内容远远超出了人类的理解,因此对人工智能和数据分析的需求确实变得至关重要。”
单个血液样本通常会提取约一百万个T细胞,这些T细胞中的每一个在基因上都是与特定抗原受体绑定的。将这些T细胞受体DNA序列的读数翻译成一组抗原,然后将这些抗原翻译成疾病状态。这是一个非常大的机器学习问题。”Lee补充说。
这时候就需要使用微软的机器学习技术。微软使用的算法是目前用于自然语言翻译的算法。“这与我们在Bing搜索引擎中所谓的主题识别技术有一些相似之处,”Lee说。微软使用Adaptive Biotechnologies的MIRA系统生成训练数据——这些训练数据被用于创建从T细胞受体到抗原的“翻译图”,然后尽可能准确地将这些抗原映射回疾病。
这听起来有点抽象,这种做法可能会带来一些具体的好处:如果映射如Adaptive和微软预想的那样起作用了,那么这可能意味着患者在他们知道他们生病了之前就可能被诊断出患有疾病。例如,卵巢癌的症状非常隐蔽,直到晚期才会被发现。通过对患有基因突变(如BRCA1,会让患者患卵巢癌的风险更高)的患者进行先发性检测,这项检测可以提取关于早期癌症的指示性免疫信号。你越早发现疾病,治愈的可能性就越高。
Adaptive现在正在研究两种“未满足医疗需求的疾病,要么非常非常难以诊断以及/或者诊断需要治疗干预,而这可能显着影响对患者的护理,” Robins这样表示。
Adaptive首先瞄准了一些疾病,一旦模型得到验证,它希望使用相同的系统来累积越来越多的条件。“如果我们真的能够从中得出诊断结果,那么随后几年我们就会在接下来的两年、五年以及未来二十年继续推进,”微软的Lee说。
一旦一种疾病被破解,机器学习能够是否可以更容易或更快地破解下一种疾病?
“让我给你一个既乐观又悲观的答案。乐观的是,隐藏层中的深层神经网络天生地学习了一些关于免疫系统工作方式的隐藏结构,然后了解了6种、60种、100种甚至更多疾病之后的某个时候,你只是实现了这种能力的爆炸。”从某种程度上说,神经网络可能仅仅能够了解和解码每种新疾病而不需要再训练。
当然,存在一种悲观的看法。“你也会碰壁。在某些时候,新增训练数据的价值和新增计算能力的价值开始消失。有时候,我们会在机器翻译等领域看到这一点:几个月前,我们宣布我们在翻译英文和普通话方面达到了人类的水平。我们获得了90%的准确率,但为了获得最后10%,我们需要2倍的计算能力和2倍的数据......目前我真的不知道我们在试图将T细胞受体序列映射到抗原到疾病状态方面处于什么样的状态,我们希望是前者,但也可能是后者,或者某种形式上两者兼有。”
虽然没有人知道这个悲观或者乐观的观点是否正确,但Adaptive预计第一个单一疾病诊断测试将在三年的时间进行,更全面的多病筛查测试将在八到十年的时间。
“随着我们开始分层次地进行[每项单一疾病测试],一个接一个地进行,在某个时刻,一次性完成所有操作的成本效益、易用性和效率能够达到足够的水平。这将成为一个生物系统的视图,这就是我们将要努力的目标,”Robins说。
就像你会定期去医生那里进行检查,或者在你到一定岁数的时候被要求进行乳房癌或肠癌筛查,未来你可能会被要求进行一次抽血,经过分析告诉你要注意哪些疾病,甚至告诉你以前从来没怀疑有过的症状。
Lee说,这个系统甚至有可能诊断出只有十亿分之一可能性的症状,或者是一种全新的疾病。
“看起来我们将会发现那些我们还没有弄清楚、不常见甚至是从没见过的症状。这些观察对于医学研究和科学进步的价值问题是我们想知道的问题。这也是推动着我们针对那些刚开始生成、可能有助于科学发现的开放式探索。”
好文章,需要你的鼓励



牛津大学让AI学会“物理直觉“:一个无需看视频就能预测物体运动的神经网络
牛津大学提出PHYSIFORMER,一种扩散变换器模型,通过三维网格顶点轨迹直接在世界坐标空间预测刚性与弹性物体的物理运动,一次性生成全序列轨迹,超越自回归基线。

美国多源电子患者数据采集方法研究综述
随着医疗数据数字化与互操作性的进步,跨机构纵向患者数据的研究应用成为可能。本研究通过对20位领域专家的访谈,识别出8种数据收集方法,涵盖智能手机应用、结构化数据导出、区域/全国研究查询及聚合数据源等。研究发现,各方法均有其优缺点,无单一最优方案。参与者中介交换方式可绕过复杂治理安排,但存在数据缺口;全国性网络尚不支持研究查询。公共政策的持续推进将对该领域发展起关键作用。

奖励模型的“选择困难症“:卡内基梅隆大学与Meta联手发现AI训练中被忽视的隐患
研究发现主流奖励模型对同等质量答案给出差异悬殊的分数,并提出"奖励聚类"算法通过蒙特卡洛随机失活将连续分数离散化,在不重训模型的前提下有效减少AI训练中的奖励作弊现象。
2018
07/02
21:19
分享
点赞

最热门的 AI 模型:它们的功能和使用方法
这款古怪的 AI 智能手机可以创建你的数字分身
Faireez 获 750 万美元融资,为租赁市场提供 AI 驱动的酒店式管家服务
Broadcom 大获全胜:70% 大型 VMware 客户购买其最全面解决方案
Peer 获得1050万美元元宇宙引擎投资,推出3D个人星球功能
获 3000 万美元融资,Crogl 发布面向安全分析师的全新 AI "钢铁侠战衣"
Turing 获得 1.11 亿美元融资,估值达到 22 亿美元,为 OpenAI 等大语言模型公司提供关键代码支持
Tavus 推出系列 AI 模型,实现实时人脸交互技术突破
Welevel 获得 570 万美元融资,革新程序化游戏开发
AI 驱动的卓越运营:企业如何通过人人可及的流程智能提升成功
