
定义新一代云原生向量数据库,Milvus 2.0 GA
近日,获得 AI 开发者广泛关注(Github star 数 9000+)的“AI 神鸟项目” Milvus 向量数据库(Milvus 在英文中指鸢),正式宣布2.0 版本的 GA。全新的 Milvus 向量数据库具备支持大规模生产环境的能力,帮助开发者在构建深度学习、机器视觉、语义学习等大规模系统时,能够快速构建起高可靠、高性能、高检索效率、运维管理友好的向量数据(embedding vector)处理平台。
“这不是一次简单的版本升级,而是一次全面重构,也是我们过去三年在向量数据库领域探索之后的集大成之作。在经过对架构进行全面重新设计,及 9 个 RC 版本的迭代后,我们正式宣布 Milvus 2.0 的 GA。 Milvus 的用户将由此能够获得生产级可用的开源向量数据库系统,它可以部署在任意云基础设施上,使用更加便利,性能更加强大,整体成本也更为优化。”Milvus 工程总监栾小凡如此描述此次 GA 对 Milvus 项目的意义。
“我们在迭代了 19 个版本后发布了 Milvus 的 1.0 版本,并获得了全球近 1000 家用户的实践验证。但我们依然看到了它的很多局限性,比如实时性与效率的冲突,成本的高昂,可扩展性和弹性的不足。于是我们开始了 2.0 版本的重构。” 栾小凡提及的这些局限,充分说明目前 AI 系统开发者在面对生产落地时,在算法和模型之外,也同样面临更为切实的权衡:
- 非结构化数据相比传统结构化数据,已经占据压倒性地位;
- 数据新鲜度非常重要,数据科学家们更希望能够拥有实时处理能力,而非忍受对 T+1 的妥协;
- 面对生产实践环境,数据处理的成本和性能更加重要,但现有的方案却仍然与需求存在距离;
- 数据平台能够自如的部署在各种云基础设施之上,全面云原生化势在必行。
的确,随着 AI 应用的大规模快速普及,一套 AI 系统需要应对的业务数据量呈几何级数增长。这其中以图形、视频、音频为代表的非结构化数据为主。目前业务处理这类非结构化数据的主流的做法是将数据通过算法先转化成向量(embedding vector),之后通过向量数据库平台进行向量近似性搜索,以实现对这些数据的搜索查询等需求。在最近的人工智能顶会 NeurIPS 上,Google、Facebook 及 Microsoft 的 AI 团队向业界公开了数个全新的 10 亿级向量数据包,而这些数据全部基于真实的业务场景产生。面对这些这些真正意义上的“大规模”并且仍在高速增长的海量数据,是否有更好的向量数据库解决方案,能在更高的效率、更好的成本收益比,更稳定可靠的平台支持,更方便的运维管理之间取得取舍均衡,是业界的焦点所在。
Milvus 2.0 正是为应对这种大规模生产级场景而设计的向量数据库系统,综合考虑了架构稳定性、工程可靠性、性能、成本、功能、用户体验等多种因素,并全面拥抱云原生技术。
Milvus 2.0 围绕三个理念,重新定义了新一代云原生向量数据库:
- 云原生优先:存储计算分离的架构更能发挥云的弹性,以实现按需扩容的模式。 而 Milvus 2.0 采取了读写分离、实时离线分离、计算瓶颈/内存瓶颈/IO瓶颈分离的微服务化设计模式,这有助于面对复杂的工作负载选择最佳的资源配比。
- 日志即数据:Milvus 2.0 引入消息存储作为系统的骨架,数据的插入修改只通过消息存储交互,执行节点通过订阅消息流来执行数据库的增删改查操作。这一设计的优势在于降低了系统的复杂度,将数据库关键的持久化和闪回等能力都下钻到存储层;另一方面,日志订阅机制提供了极大的灵活性,为系统未来的拓展奠定了基础。
- 批流一体:Milvus 2.0 实现了 unified Lambda 流式处理架构,增量数据和离线数据一体化处理。相比 Kappa 架构,Milvus 引入对日志流的批量计算将日志快照和构建索引存入对象存储,这大大提高了故障恢复速度和查询效率。为了将无界的流式数据拆分成有界的窗口,Milvus 采用 watermark 机制,通过写入时间(也可以是事件发生时间)将数据切分为多个小的处理单元,并维护了一条时间轴便于用户基于某个时间点进行查询。
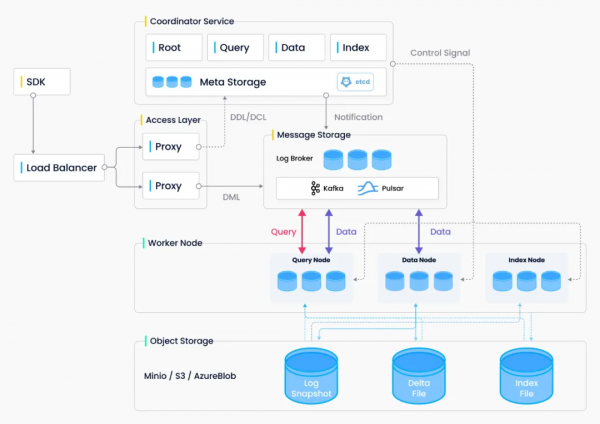
Milvus 2.0 架构概览
基于上述的理念及架构设计,Milvus 2.0 可以支持: 百亿规模的向量数据扩展能力,增量数据毫秒级实时可见的数据可见性,存储计算的秒级扩缩容能力,10 毫秒级查询延时性能,分钟级的故障恢复能力,动态负载均衡能力;提供完善的面向向量数据的增删改查功能,数据压缩压缩功能,动态加载索引功能,及图形化 GUI 及命令行管理工具,提供 PyMilvus、Node.js、Java and Go 等多语言语言 SDK。目前,Milvus 2.0 无论在性能、功能、稳定性、可扩展性及易用性方面,均到达业绩领先水平,重新定义了向量数据库的标杆。
“基于大数据 + AI 的应用架构依然过于复杂,简化非结构化数据处理一直是 Milvus 社区努力的方向。” 谈及 Milvus 项目未来的发展路线图时,栾小凡这样表示。接下来的 Milvus 项目会重点关注以下几个方向:
- DB for AI:作为一款数据库,除了基本的 CRUD 功能之外,Milvus 必然还需要更强大的数据查询能力、更智能的查询优化器、更全的数据管理功能等。下一阶段将重点补齐 Milvus 2.0 目前还不支持的 DML 功能和数据类型,比如删除、更新操作和支持 string 数据类型。
- AI for DB:向量索引类型、索引参数、用户工作负载、硬件类型、成本性能等的约束构成了一个非常庞大的 tradeoff,尽可能避免手动调优有助于降低使用复杂度。我们已经着手分析系统负载,收集访问热度的数据,后续将引入自动参数调优工作以降低用户的理解成本。
- 成本优化:向量召回的最大挑战是需要在限定时间内处理海量数据,这项工作既是计算密集型,也是访存密集型。在物理执行层引入 GPU、FPGA 等异构硬件加速可以大幅降低 CPU 开销。我们正在开发磁盘内存混合的 ANN 索引算法,可以在有限的内存下实现海量向量的高性能查询。于此同时,我们也在评估开源的 ScaNN、NGT 等向量索引算法的性能。
- 易用性:Milvus 易用性的提升体现在集群管理工具、多语言 SDK、部署工具、运维工具等许多方面,Milvus 将在这些方向持续迭代完善。同时,Milvus 的设计理念是可以在任何平台运行,在接下来的几个版本更新中, Milvus 将支持 MacOS 系统(M1 芯片及x86 芯片)以及 ARM 架构。
来源:业界供稿
好文章,需要你的鼓励


Albertsons借助Databricks构建零售商品智能决策平台
美国连锁超市巨头Albertsons正在基于Databricks构建商品智能平台,整合产品、定价、促销与陈列等决策功能,目标是在2026年底前全面向门店运营商落地。该平台以Databricks Lakehouse存储零售数据,通过Unity Catalog与AI Gateway实现数据治理,并借助AI智能体Genie支持自然语言查询,帮助商家洞察销售趋势,提升决策效率。此举是Albertsons今年四项AI核心战略投资之一。

阿里巴巴让AI图像生成模型“自我进化“:Qwen-Image-2.0-RL是如何让机器学会审美的?
阿里Qwen团队通过引入强化学习和在线策略蒸馏,将Qwen-Image-2.0升级为Qwen-Image-2.0-RL,让图像生成模型真正学会人类审美,文生图Elo评分提升78分,图像编辑提升93分。

微软正式将 Windows 11 打造为 AI 操作系统
微软正将Windows 11打造成真正的AI操作系统。在Build大会上,微软展示了AI模型与智能代理如何深度融合进Windows 11,让用户通过自然语言完成系统操作。借助Windows ML框架,超过5亿台PC已可在本地离线运行AI任务,无需联网、无token费用、数据不离设备。Office、Photos、Teams等应用已支持本地AI能力,Adobe、WhatsApp、Canva等第三方也在积极跟进,企业级AI PC采购需求有望加速。

港科大联手快手,让AI画图“减减肥“:一个让图像生成更真实的小技巧
港科大与快手联合提出NormGuard,针对流匹配模型强化学习训练中速度范数膨胀问题,通过训练时单向惩罚约束,在保留奖励的同时改善图像真实感。
2022
02/10
10:20
分享
点赞

Albertsons借助Databricks构建零售商品智能决策平台
微软正式将 Windows 11 打造为 AI 操作系统
工作中使用未授权AI工具之前,请三思
全球首座AI博物馆Dataland:用数据创造多感官视觉盛宴
ANS框架:Linux基金会为AI智能体建立DNS式信任机制
Hirebotics推出无代码防爆协作机器人,专为工业喷涂设计
美国消费品安全委员会拟出台电动自行车电池安全新规
江波龙:建设完成mSSD月产能百万交付能力!mSSD高速存储介质赋能端侧AI规模应用
从IO500双榜第一,看国产存储的系统级突破
Rocket Lab宣布以80亿美元收购卫星运营商铱星公司
OpenAI携手Trail of Bits发起"Patch the Planet"开源安全修复计划
公共电力性价比优势面临多年来最严峻考验
