
Marvell与AWS达成合作,推动芯片EDA全面上云
Marvell公司日前宣布,计划将电子设计自动化(EDA)工作流程由本地迁移至亚马逊云科技(AWS)。Marvell同时强调,他们是AWS的“电光材料、网络、安全、存储及定制设计等解决方案”供应商。这项新消息相信对两家公司都有积极的推进意义。
EDA是工程师日常使用的IP块、芯片与SoC设计/模拟/调试/验证软件工具,主要由Cadence和Synopsis提供。过去十年以来,这类工具已经整合了AI技术,能够自动处理特定程序以改善产品上市时间。Cadence最近还推出了其Verisium平台,据称能够将调试生产率提升10倍。
凭借愈发强大的EDA工具,工程师们能够利用种种资源加快工作流程。但从另一个角度看,这也意味着EDA本身需要大量计算和存储资源作为支持。要想快速获取提示和答案,丰富的算力和内存必不可少。相较于本地设施,以AWS为代表的公有云显然特别适合这类工作负载。
Marvell公司产品和技术总裁Raghib Hussain也对公有云赞许有加,表示“将EDA工作负载迁往云端,将改变半导体的整个开发方式。通过在AWS云服务中运行EDA,Marvell将得以优化我们的芯片开发项目,加快我们的产品上市时间。”
Marvell并未具体说明其使用的AWS EC2实例、存储、内存、工具或文件系统,但我们可以在AWS网站上找到关于Marvell的信息(https://aws.amazon.com/solutions/semiconductor-electronics/electronic-design-automation/?solutions-all.sort-by=item.additionalFields.sortDate&solutions-all.sort-order=desc&marketplace-ppa-and-quickstart.sort-by=item.additionalFields.sortDate&marketplace-ppa-and-quickstart.sort-order=desc&solutions-whitepapers.sort-by=item.additionalFields.sortDate&solutions-whitepapers.sort-order=desc)。
Marvell还公开透露,他们本身也是AWS的重要半导体供应商。这也很正常,毕竟Marvell在云存储、电学材料、DPU(数据处理单元)、网络和HSM(硬件安全模块)等领域均处于市场领先地位。
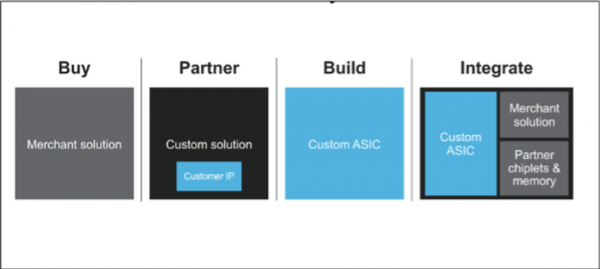
Marvell的“灵活研发模型”
Marvell公司拥有先进的技术、IP、封装与互连储备。在芯片制造端,Marvell已经能够匹配台积电的最新3纳米顶级制程,掌握多种加速器,具备高速混合信号专家,也是多芯片模块(MCM)、共封装光学元件和封装内内存设计的领导者。Marvell的最终产品对应灵活的交付方式,客户可以直接购买、以伙伴身份参与合作(自定义IP)、通过自定义ASIC构建,或者与复杂的SoC集成。这些能力贯穿超大规模数据中心的计算、安全和存储等层面,并通过交换机连接各机架、通过光纤互连对接各处数据中心。尽管AWS没有阐明,但我个人相信Marvell应该是使用了AWS的Nitro SSD。身为云服务领域的绝对领导者,AWS也有必要积极采用Marvell的硬件安全模块。
AWS Amazon EC2副总裁David Brown在评论Marvell芯片能力的新闻稿中提到,“我们的客户通过与Marvell的合作而受益,他们将芯片创新推向了广泛而深入的云服务体系。”David Brown亲自发言,无疑是对Marvell的支持和肯定。
那么,两家运营良好的公司突然“互诉衷肠”,到底是想干什么?
虽然AWS拥有多种原研芯片(包括Nitro System、Graviton Compute、Inferentia Inference,以及即将推出的机器学习训练专用Trainium),但这类重大课题显然不是单一厂商就能解决的,所以也需要商业芯片供应商的扶持。Marvell的意义正在于此。我很期待AWS是否以及如何使用Marvell提出的所谓“灵活研发模型”中的自定义功能。对于AWS,这代表其云EDA服务已经取得重大胜利——40年来,第一次将这类负载从本地设施推上云端。同时,Marvell方面也能借此为客户提供更多新功能,为迎接半导体产业的未来做好准备。
好文章,需要你的鼓励



明尼苏达大学最新研究颠覆认知:训练AI大模型,只需动其中一层就够了?
这项来自明尼苏达大学等机构的研究发现,大语言模型在强化学习后训练中,只需训练中间少数几层即可匹配甚至超越全参数训练效果,且这一规律跨模型、跨任务高度稳定,为更高效的AI训练策略提供了新思路。


台湾大学与NVIDIA揭秘:你的声音正在悄悄改变AI对你的判断
本文介绍VIBE框架,一套通过开放式任务评估大型音频语言模型声音诱发偏见的系统,测试12个模型后发现每个模型均存在显著性别或口音偏见。
2023
02/28
10:27
分享
点赞

边缘智算筑基、全栈软硬协同,研华科技将AI带进产业闭环
千问AI眼镜将升级为智能体眼镜:能灵活调用Skill和Agent,能全天候感知
对话Moonix郭于晨:先让用户戴上“眼镜”,再让“AI”记录世界
亮相WAIC 2026,临床实证赋能康养升级 无芯科技定义AI疗愈新范式
生态覆盖持续扩散,一文看懂各行业企业鸿蒙化转型进度
WAIC亮出集群协作真功夫,优艾智合领跑工业具身智能规模化
脑部植入物助瘫痪男子重获进食与饮水能力
能源公司IPO融资创21世纪新高,押注AI基础设施热潮
Apple Intelligence获中国监管批准,携手阿里巴巴与百度正式进入中国市场
Moonshot即将发布的Kimi K3有望赶超Anthropic Opus 4.8
OpenAI 为何开始卖 ChatGPT 品牌篮球?
DoorDash推出命令行工具,开发者可借助AI智能体直接下单
