
Gartner发布2023年十大数据和分析趋势
2023年5月18日 - Gartner发布了2023年十大数据和分析(D&A)趋势。这些趋势可以指导数据和分析领导者预测变化,将巨大的变数转化为新的商机,从而为他们的企业机构开辟新的价值来源。
Gartner研究副总裁Gareth Herschel表示:“企业机构需要大规模地获得可证实的价值,这一需求成为了推动这些数据和分析趋势的驱动力。首席数据和分析官(CDAO)及数据和分析领导者必须向他们企业机构中的相关方了解能够推动数据和分析应用的最佳方法。这意味着他们需要更多将人类心理和价值观考虑在内的高质量分析与洞察。”
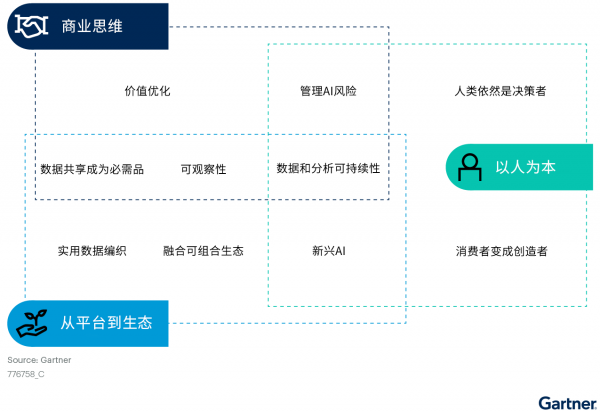
Gartner分析师在Gartner数据和分析峰会上提出了企业和IT领导者必须参与并纳入其数据和分析战略的十大数据和分析趋势(见图一)。
图一、2023年十大数据和分析趋势
来源:Gartner(2023年5月)
趋势1:价值优化
大多数数据和分析领导者都在努力使用商业术语阐述他们为企业机构创造的价值。为了使用企业机构的数据、分析和人工智能(AI)组合来优化价值,他们需要运用价值故事叙述、价值流分析、投资排名和优先性排序、业务成果衡量等一整套综合全面的价值管理能力确保预期价值的实现。
Herschel表示:“数据和分析领导者必须通过建立价值故事来优化价值,在数据和分析倡议和组织的关键任务优先事项之间建立明确的联系。”
趋势2: AI风险管理
随着人工智能(AI)的使用日益增加,企业正面临着道德风险、训练数据中毒、欺诈检测规避等种种必须缓解的新风险。管理AI风险不止是为了遵守法规,有效的AI治理和负责任的AI实践对于取得相关方的信任及推动AI的采纳与使用同样至关重要。
趋势3:可观察性
可观察性是一种帮助理解数据和分析系统的行为并提出有关其行为的问题的特性。
Herschel表示:“可观察性使企业机构能够减少发现性能问题根源所需的时间,并利用可靠、准确的数据做出及时且经济有效的业务决策。数据和分析领导者需要评估数据可观察性工具,以便了解主要用户的需求并确定如何将这些工具融入到整个企业生态中。”
趋势4:数据共享成为必要
数据共享分为内部(部门之间或子公司之间)和外部(非您的企业机构所有和不受您的企业机构控制的各方之间)数据共享。企业机构可以将数据“产品化”,把数据和分析资产作为一种可交付或共享的产品。
Gartner高级研究总监Kevin Gabbard表示:“包含对外数据共享协作在内的数据共享协作通过增加以前创建的可重复使用的数据资产提高数据共享价值。可以采用数据编织设计,实现跨内部和外部异质数据源的单一数据共享架构。”
趋势5:数据和分析可持续性
为了提高可持续性,数据和分析领导者不但要为企业环境、社会和治理(ESG)项目提供分析和洞察,还必须努力优化他们的流程,而这可能会给他们带来巨大的收益。数据和分析及AI从业者日益意识到自己不断增长的能源足迹。因此,他们开始采取各种新的做法,例如在(云)数据中心使用可再生能源、使用更节能的硬件、使用小数据和其他机器学习(ML)技术等。
趋势6:实用数据编织
数据编织是一种运用各种类型的元数据来观察、分析和推荐数据管理解决方案的数据管理设计方式。通过汇集和丰富底层数据的语义,并对元数据进行持续不断的分析,数据编织能够产生人类和系统可以执行的警报和建议。它使商业用户能够放心地消费数据,并帮助技能较弱的公民开发者掌握更加全面的流程整合和建模能力。
趋势7:新兴AI
ChatGPT和生成式AI是即将到来的新兴AI趋势的“先锋”。新兴AI将从可扩展性、多功能性和适应性的角度改变大多数企业的运作方式。下一轮AI浪潮将使企业机构能够将AI应用于目前不可行的情况,使AI变得更加普遍和有价值。
趋势8:融合与可组合生态系统
融合数据和分析生态所设计和部署的数据和分析平台通过无缝集成、治理和技术互操作性实现运行和功能的一致性。生态通过构建、组装和部署可配置的应用和服务实现可组合性。
合适的架构可提高数据和分析系统的模块化程度、适应性和灵活性,使其具有动态扩展能力并变得更加精简高效,从而满足不断增长和变化的业务需求,并伴随不可避免的业务和运营环境变化而演变。
趋势9:消费者成为创造者
用户花在预定义仪表板上的时间将被满足特定内容消费者即时需求的对话式、动态和嵌入式用户体验所取代。
企业机构可通过向内容消费者提供他们成为内容创作者所需要的易于使用的自动化和嵌入式洞察与对话式体验,扩大分析的采用和影响。
趋势10: 人类仍然是关键决策者
并非每项决策都可以或应该实现自动化。数据和分析团队正在强调决策支持以及人类在自动化和增强决策中的作用。
Herschel表示:“如果企业机构只顾着推动决策自动化而忽略人类在决策中的作用,就会变成一家没有良知、人心涣散的数据驱动型组织。企业机构需要在数据素养计划中强调将数据和分析与人的决策相结合。”
来源:业界供稿
好文章,需要你的鼓励


星际之门AI数据中心建设雄心遭遇现实挑战
2025年1月,OpenAI、软银、甲骨文和MGX联合宣布"星际之门"计划,承诺投资5000亿美元,部署高达10GW算力基础设施。如今,该项目已从白宫发布会上的宏大承诺,演变为一场前所未有规模的基础设施建设实验。项目已扩展至德克萨斯、威斯康星、俄亥俄等多地,并延伸至阿布扎比和挪威。然而,融资争议、合作伙伴摩擦、能源压力及政策监管收紧,正考验着这一"AI工业园"模式能否真正落地。

阿里巴巴让AI图像生成模型“自我进化“:Qwen-Image-2.0-RL是如何让机器学会审美的?
阿里Qwen团队通过引入强化学习和在线策略蒸馏,将Qwen-Image-2.0升级为Qwen-Image-2.0-RL,让图像生成模型真正学会人类审美,文生图Elo评分提升78分,图像编辑提升93分。

OKX推出AI智能体招聘与支付市场平台
加密货币交易所OKX正式推出AI智能体交易市场OKX AI,允许AI代理相互雇佣、自主结算,并建立基于区块链的可携带信誉档案。该平台经过50家早期服务商封测后向开发者开放,依托稳定币和链上支付基础设施,支持全天候微支付。OKX创始人徐明星表示,传统金融基础设施为人类而建,智能体经济需要为自主软件专门设计的基础设施。

港科大联手快手,让AI画图“减减肥“:一个让图像生成更真实的小技巧
港科大与快手联合提出NormGuard,针对流匹配模型强化学习训练中速度范数膨胀问题,通过训练时单向惩罚约束,在保留奖励的同时改善图像真实感。
2023
05/18
16:01
分享
点赞

星际之门AI数据中心建设雄心遭遇现实挑战
OKX推出AI智能体招聘与支付市场平台
AI编程Token成本将与开发者薪资持平,企业如何应对?
机器学习项目全生命周期管理的成功实践
SVT Robotics的Softbot平台交易量突破40亿笔
Agibot第15000台人形机器人下线,具身AI量产加速
杜尔为大众汽车建设跨工厂集成CO?高效涂装车间
AI对就业的影响:大规模裁员背后的真相与数据
AI重复申请问题推动电网转向"承诺优先"规划
美国消费品安全委员会拟出台电动自行车电池安全新规
江波龙:建设完成mSSD月产能百万交付能力!mSSD高速存储介质赋能端侧AI规模应用
从IO500双榜第一,看国产存储的系统级突破
