
IBM宣布在watsonx.ai平台上托管Meta Llama 2
IBM近日宣布将在今年5月推出的watsonx.ai企业人工智能开发平台上,托管Meta Platforms的Llama 2。现在,部分客户已经可以抢先体验。

watsonx.ai可用于训练生成式AI模型和其他类型的神经网络,无需从头开始构建自己的模型,平台中包括了预先打包的AI模型目录以及用于训练这些模型的数据集。
今年2月Meta宣布开源Llama的举动震惊了人工智能界。像Llama这样的基础模型通常是在大量未标记数据上进行训练的,这使其能够针对各种任务进行微调。Meta上个月又开源了Llama 2(正式名称为Large Language Model Meta AI 2-chat),并表示将允许企业使用专有数据和工具定制他们自己的AI模型。
持续合作
IBM和Meta过去曾合作开发多个开源项目,包括PyTorch机器学习框架和watsonx.data中使用的Presto查询引擎。watsonx.data是一个基于开放Lakehouse架构构建的专用数据存储。
IBM的战略是提供第三方和自己的AI模型。目前,IBM提供自己的模型以及由Hugging Face支持的社区所托管的模型,这些模型经过预训练,可以支持一系列自然语言处理任务,例如问答、内容生成、内容摘要、文本分类和提取。IBM公司表示,计划很快就会发布AI调优工作室、watsonx.ai模型的情况说明书、以及IBM自己的生成式AI模型。
IBM表示,为了满足企业对安全和数据隐私的担忧,通过watsonx.ai中的提示实验室运行Llama-2模型的用户可以切换护栏功能,自动删除输入和输出文本中的有害语言,Meta还提供了文档用于构建负责任的AI模型。
IBM正在努力成为企业AI开发的首选技术提供商。Upwork Global最近的一项研究发现,有73%的CEO表示,他们的企业正在拥抱生成式AI。IBM表示,IBM的21000名数据、人工智能和自动化顾问已经与40000多家企业客户展开合作,作为IBM咨询部门一部分的Center of Excellence for Generative AI也聘请了1000多名顾问。
好文章,需要你的鼓励

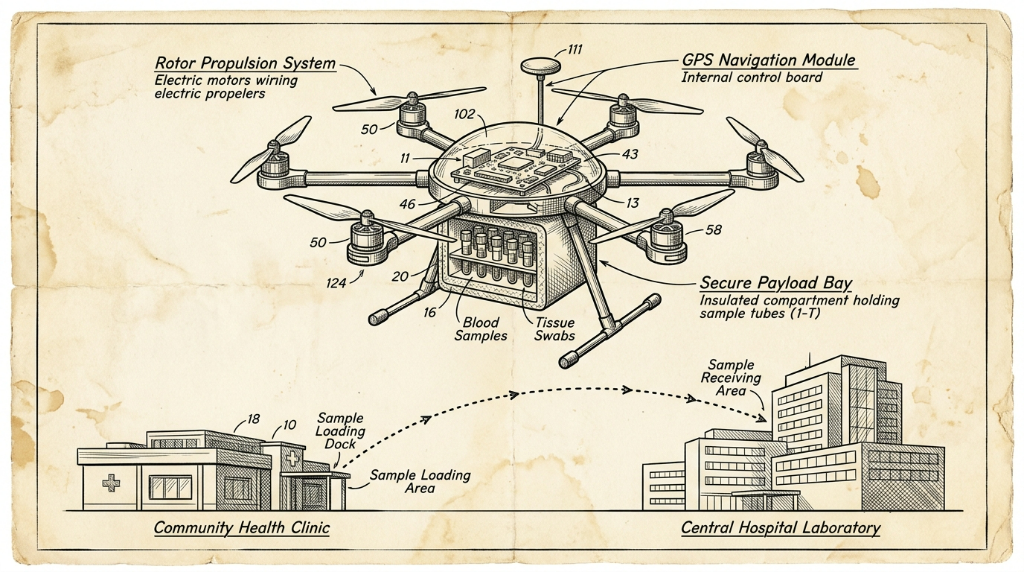
英国NHS无人机快递医疗样本服务正式落地伦敦
英国国家医疗服务(NHS)正将无人机纳入常规医疗物流体系。自今年2月起,无人机每天在雷恩斯公园和圣乔治医院之间运送血液等诊断样本,飞行仅需3分钟,比公路运输快约85%,且碳排放减少高达98%。目前已有逾2000名患者受益。NHS计划将该服务扩展至圣赫利尔、克罗伊登等多家医院,最终惠及约180万名患者。该网络由英国医疗初创公司Apian与谷歌旗下Wing合作运营。

Explyt团队打造的代码智能体评测新标准:光靠“通过/失败“根本不够用
AgentLens是Explyt公司联合俄罗斯学术机构开发的AI编程助手评测基准,通过分析完整人机交互轨迹而非仅看最终结果,从五个维度评估代码智能体的真实表现。

Aetina宣布支持英伟达Jetson T3000和T2000 AI模块
边缘AI计算厂商Aetina宣布,将在其DeviceEdge AIE-KT风冷系列和新款AIE-PT无风扇平台上支持英伟达全新Jetson T3000和T2000模块。T3000基于Blackwell GPU,最高提供865 FP4 TFLOPS算力,功耗70W;T2000则提供400 FP4 TFLOPS,面向视觉AI代理和自主移动机器人等场景。两款模块预计2027年第一季度上市,支持Nemotron、Cosmos 3等英伟达AI软件生态。

机器人的“触觉觉醒“:韩国梨花女子大学如何让小型AI模型在不忘记视觉的前提下学会“感受“材质
韩国梨花女子大学提出Splash框架,通过识别AI模型中的"休眠参数"并只在其中训练触觉能力,让小型多模态AI在学会感知材质触感的同时,完整保留原有视觉语言推理能力。
2023
08/13
16:13
分享
点赞

WAIC2026 现场直击:开普勒顶流人气王,麒麟系列火爆出圈
面壁智能将密度定律带入具身智能
龙磁科技拟投3.58亿元扩建越南永磁铁氧体基地
首创一层Scale-up网络256卡全互联,摩尔线程MTT C256超节点为万卡及十万卡级集群夯实底座
从高血压诊疗入手,北京安贞医院让医疗大模型走出聊天框
西门子肖松:以场景为牵引,推动工业AI从单点实效迈向生产力跃迁
打造Token极致性价比 新华三震撼亮相2026世界人工智能大会
机器人管家系统上线!傅利叶携多款康养陪伴新品方案亮相WAIC 2026
赛那德“ 自主作业机器人天团” 登陆 WAIC:iLoabot-X+模型双升级,秀出具身场景落地硬实力
西门子Eigen工程智能体中国首发首展,荣获2026 WAIC SAIL之星奖
NVIDIA Cosmos 推动物理 AI 前沿发展
PPIO亮相WAIC 2026:发布智能模型网关,打造面向Agent时代的智能Token工厂
最热门的 AI 模型:它们的功能和使用方法
这款古怪的 AI 智能手机可以创建你的数字分身
Faireez 获 750 万美元融资,为租赁市场提供 AI 驱动的酒店式管家服务
Broadcom 大获全胜:70% 大型 VMware 客户购买其最全面解决方案
Peer 获得1050万美元元宇宙引擎投资,推出3D个人星球功能
获 3000 万美元融资,Crogl 发布面向安全分析师的全新 AI "钢铁侠战衣"
Turing 获得 1.11 亿美元融资,估值达到 22 亿美元,为 OpenAI 等大语言模型公司提供关键代码支持
Tavus 推出系列 AI 模型,实现实时人脸交互技术突破
Welevel 获得 570 万美元融资,革新程序化游戏开发
AI 驱动的卓越运营:企业如何通过人人可及的流程智能提升成功
