
双十一过后,阿里云崩了 原创
11月12日,就在“双十一”后的第二天,“阿里云盘崩了”的消息一度冲上微博热搜,连同冲上热搜的还有诸如淘宝、闲鱼、钉钉等阿里云支持下的其他阿里官方产品。

据阿里云官方公告显示,此次阿里云故障发生在11月12日下午17:44左右,受到影响的产品包括OSS、OTS、SLS、MNS等多款产品,波及地区涵盖北京、上海、深圳等国内众多一二线城市,以及日韩、美国、德国等海外地区。

经过阿里云工程师紧急抢修,在经历了一个多小时的异常后,杭州、北京等地控制台和API服务陆续回复;经过三个多小时的抢修后,官方表示,受到影响的云产品在21:11均已恢复。

就在阿里云相关业务故障后不久,这一事件一度冲上了微博热搜,而这次业务故障,或将成为阿里云至今波及面最广的云服务故障。
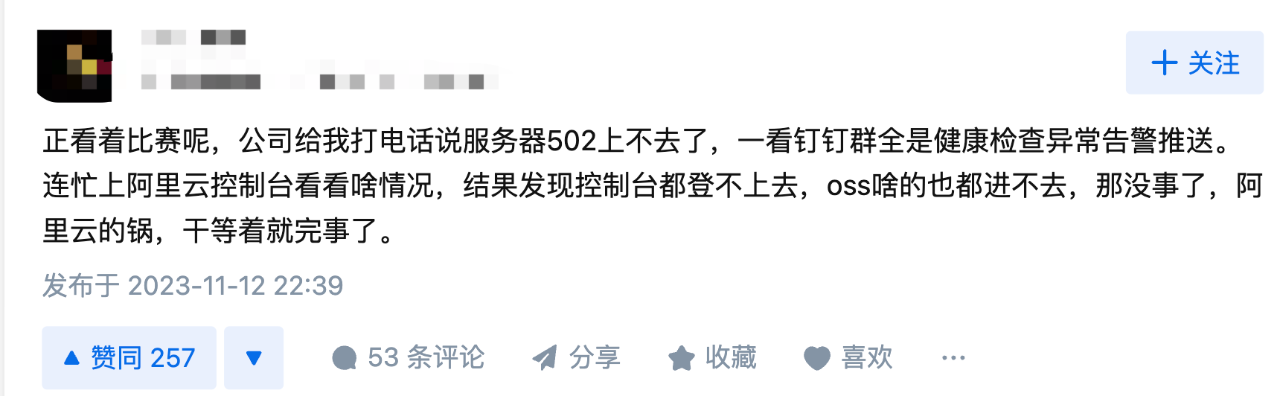
有知乎网友表示,“自己正看着比赛,公司给我打电话说服务器502上不去了,一看钉钉群全是健康检查异常告警推送,连忙上阿里云控制台看看啥情况,结果发现控制台都登不上去,oss啥的也都进不去。”
也有知乎网友认为,这可能是受到了大公司“降本增效的影响”。

至于这次阿里云故障更深层次的影响,有业内人士指出,“由于DNS控制台也发生了故障,用户连切换流量的机会都没有了,用户只能等阿里云自己修复。”
也有业内人士告诉至顶网,”这个事件确实给了我们一个教训是‘鸡蛋不要放到一个篮子里’,关键业务还是要多云、多数据中心部署,“不过,他也指出,”如此一来,成本肯定会提升,同时备案也是个比较麻烦的事情,所以还是需要企业根据自己情况来抉择。“
实际上,这样的云服务全球故障在今年并非首例,就在上周OpenAI DevDay发布会后,OpenAI也发生了大规模宕机。
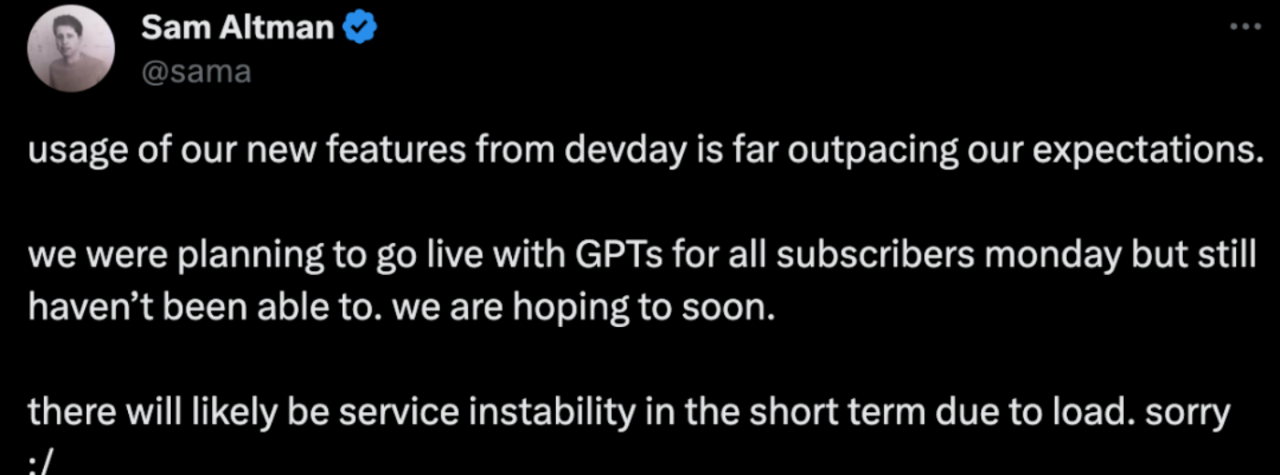
彼时,OpenAI CEO奥特曼亲自出面道歉称:
“大家对新功能的热情远超我们预期,我们原计划本周一为所有订阅者提供GPTs,但现在(周二)仍然没能实现,我们希望这个进度可以加快。
由于负载的原因,短期内我们的服务可能出现不稳定的情况,对不起。”
与此同时,海外云厂商在今年也接连宕机,外加互联网厂商对云服务成本的长期考量,让整个行业逆流迎来了一波“下云潮“。
Ruby on Rails之父David Heinemeier Hansson在今年9月发布的一篇名为《Our cloud exit has already yielded m/year in savings》的文章中就曾指出,“‘下云’为我们节省的费用已经一路攀升到了每年200万美元左右,五年内将达到1000万美元。”

而像David Heinemeier Hansson一样,通过购买服务器,自己在本地搭建私有云的方式取代以往购买公有云服务的方案,在国外已经形成了一股新的潮流。
数字化是当代企业转型的大势所趋,然而,在接下来企业数字化转型过程中,基于对安全性和成本的双重考量,私有云、多云、混合云也将成为更多企业需要认真考虑的数字化方案。
好文章,需要你的鼓励



明尼苏达大学最新研究颠覆认知:训练AI大模型,只需动其中一层就够了?
这项来自明尼苏达大学等机构的研究发现,大语言模型在强化学习后训练中,只需训练中间少数几层即可匹配甚至超越全参数训练效果,且这一规律跨模型、跨任务高度稳定,为更高效的AI训练策略提供了新思路。


台湾大学与NVIDIA揭秘:你的声音正在悄悄改变AI对你的判断
本文介绍VIBE框架,一套通过开放式任务评估大型音频语言模型声音诱发偏见的系统,测试12个模型后发现每个模型均存在显著性别或口音偏见。
2023
11/13
13:00
分享
点赞

机器人管家系统上线!傅利叶携多款康养陪伴新品方案亮相WAIC 2026
赛那德“ 自主作业机器人天团” 登陆 WAIC:iLoabot-X+模型双升级,秀出具身场景落地硬实力
西门子Eigen工程智能体中国首发首展,荣获2026 WAIC SAIL之星奖
NVIDIA Cosmos 推动物理 AI 前沿发展
PPIO亮相WAIC 2026:发布智能模型网关,打造面向Agent时代的智能Token工厂
端侧感知、私有闭环、量子协同, NVIDIA全栈异构计算范式“接管”实体产业底座
边缘智算筑基、全栈软硬协同,研华科技将AI带进产业闭环
千问AI眼镜将升级为智能体眼镜:能灵活调用Skill和Agent,能全天候感知
对话Moonix郭于晨:先让用户戴上“眼镜”,再让“AI”记录世界
亮相WAIC 2026,临床实证赋能康养升级 无芯科技定义AI疗愈新范式
生态覆盖持续扩散,一文看懂各行业企业鸿蒙化转型进度
WAIC亮出集群协作真功夫,优艾智合领跑工业具身智能规模化
