
Top500超算与摩尔定律偏离渐远,谁是真正的性能强者? 原创

一周前,在2023年全球超级计算大会(SC23)上,备受关注的第62届TOP500超算排行榜正式揭晓。
彼时,来自世界各地的超算专家、企业家、学者和研究人员齐聚美国丹佛。作为世界高性能计算领域的顶级盛事之一,本次大会吸引了超过14000名参会者和438家参展商,数量创下历史新高。
在最新的榜单中,美国橡树岭国家实验室的Frontier连续第四次夺冠,并且是当前已公开唯一的百亿亿级超算(也叫E级超算)。这意味着,其一小时的计算能力,相当于全球80亿人联合计算上万年的成果。
榜首虽然没变,但前十的格局已经出现了显著变化。 美国超算占据前三甲,阿贡国家实验室的Aurora空降第二名,安装在Microsoft Azure云平台的Eagle跻身第三,而日本理化学研究所与富士通开发的“富岳”,则从第二名滑落至第四。
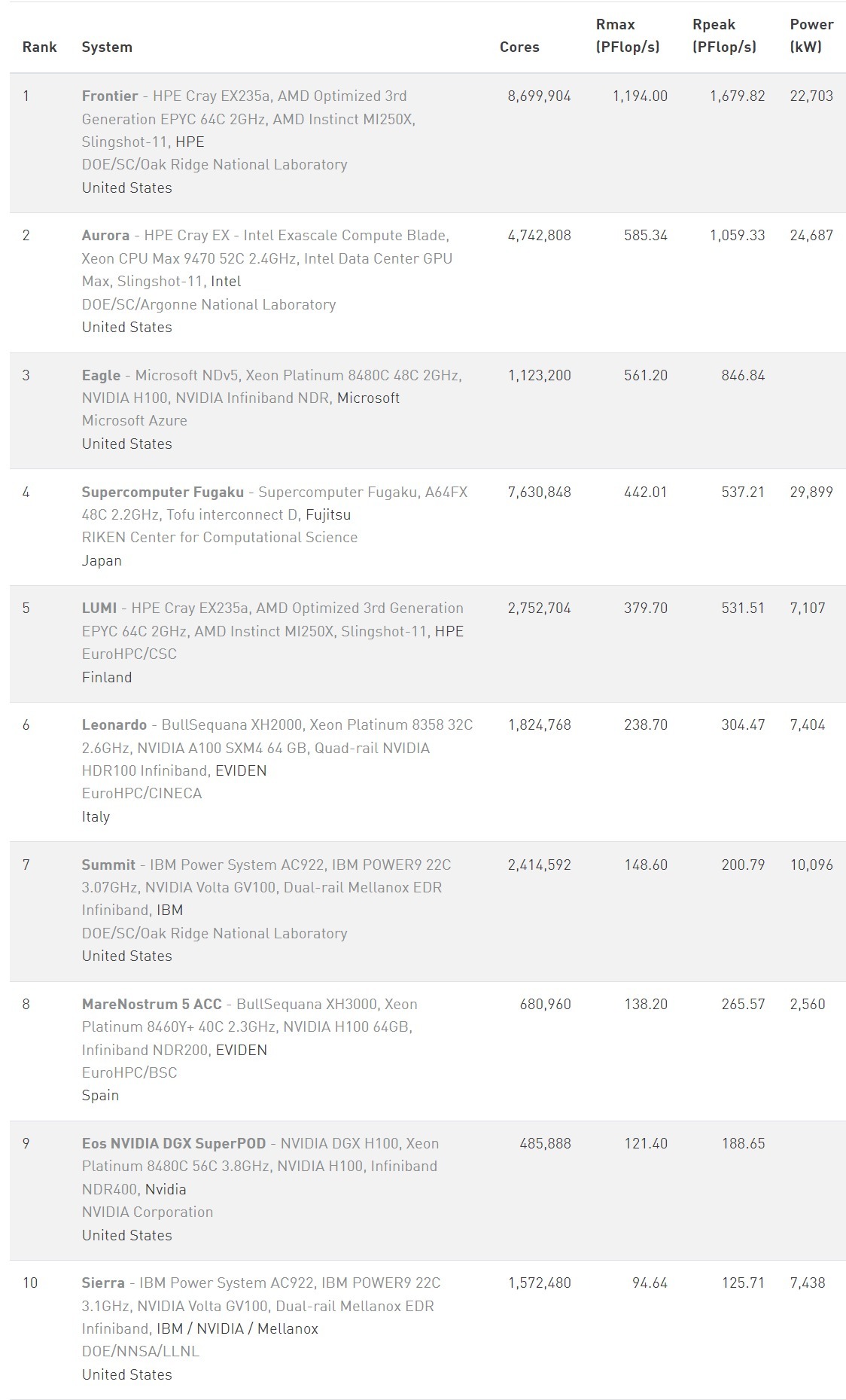
全球超算榜单TOP10
虽然榜单排名总是最吸引人眼球的,但榜单更有意义的是呈现了各种新兴系统架构的特点,让我们看到计算、内存、互连等要素如何在不同的系统中协同作用。这些上榜的超算在性能、架构和计算效率方面都值得我们深入去探究。
本文将对榜单TOP30超算的数据进行汇总分析,从而归纳出当前超算领域第一梯队的特点。
超算市场高度不平衡,技术进步集中于强者
首先,我们需要先回顾一下过去30年来,以高性能LINPACK基准测试衡量的TOP500榜单中第一名、最后一名以及总体的超算性能发展轨迹:
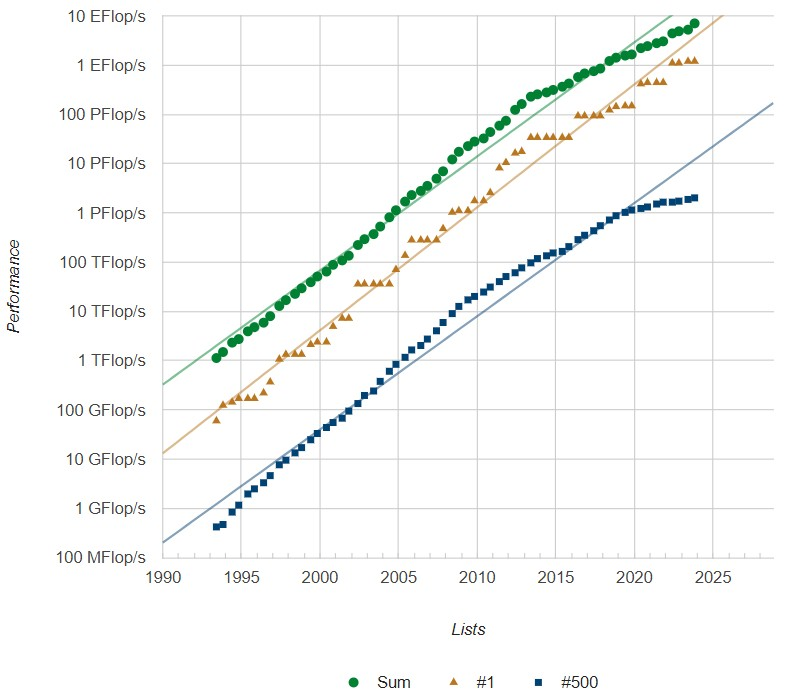
这张图表显示了从1990年到2025年超算性能的趋势。图中绿色圆点线(Sum)代表所有上榜的超算性能总和,其增长显示了整体超算性能的提升。金色三角形线(#1)代表排名第一的超算性能,蓝色方块线(#500)代表排名第500的超算性能。
可以看出,Top500的总算力与摩尔定律偏离得越来越远,摩尔定律告诉我们性能将会呈指数级增长。而事实上,我们所面对的是一个高度不平衡的市场,其中超大规模的计算机占据了总体算力的大部分,其余的部分由大量性能较低的计算机构成,两者之间差距十分明显。
下图更直观地显示了超算市场的不平衡状态,这是根据TOP500数据创建的一个上榜系统树状图,它展示了今年11月榜单中的超算系统和它们所用的不同技术架构。每个方块代表一台超级计算机,不同的颜色代表使用不同计算引擎的“阵营”。
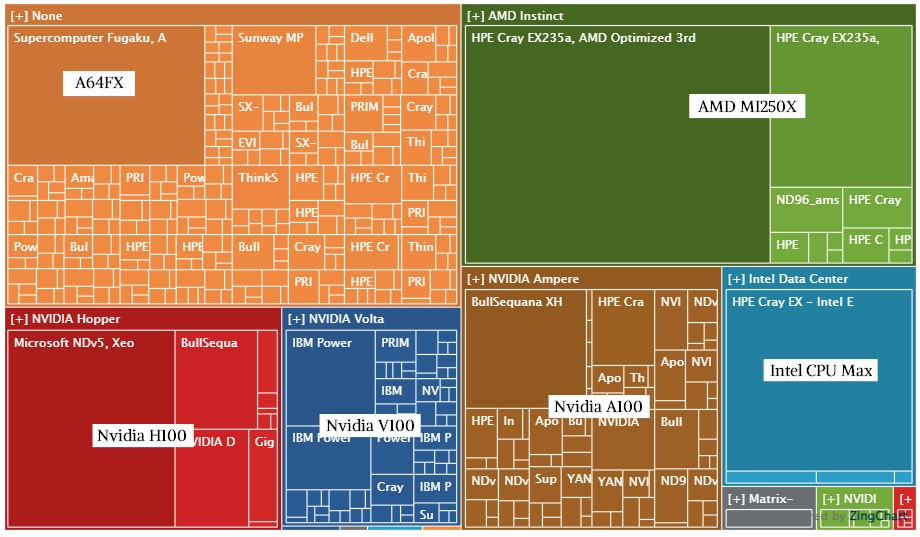
从左上角开始顺时针来看,橙色方块代表日本的富岳,采用富士通A64FX Arm芯片,拥有极强的矢量计算能力。
最大的橄榄绿方块代表美国橡树岭国家实验室的Frontier,由HPE和AMD打造。周围的浅绿色为同样采用AMD GPU的其他系统。
湖蓝色方块代表阿贡国家实验室的Aurora,Aurora是首个部署英特尔Max GPU的超算。值得注意的是,此次Aurora测试时,只大约运行了一半的CPU和GPU。
其正下方的紫色方块是2016年基于神威SW26010处理器的太湖之光(架构与A64FX类似,属于搭载大量矢量引擎的CPU),目前部署在中国无锡的国家超算中心。
向左来到棕色英伟达A100的区域,其中最大的方块是意大利CINECA研究中心的Leonardo,由法国科技公司Atos打造。
深蓝色区域包含了橡树岭国家实验室的Summit以及劳伦斯利弗莫尔国家实验室的Sierra。两台超算都采用了IBM Power 9 CPU和NVIDIA V100 GPU。
左下角是首次登场的微软Eagle,运行在微软Azure云中,搭载了英伟达Hopper H100 GPU加速器。
不难发现,排名前30的超算中涌现了不少新面孔。其中,备受关注的Aurora超级计算机由HPE制造,该系统搭载了英特尔的CPU和GPU,同时采用HPE自家的Slingshot互连技术。目前Aurora系统还在调试阶段,预期最终会远超现在的算力测试水平。
另一台世界瞩目的超算Frontier,采用了AMD定制的“Trento”Epyc CPU和“Aldebaran”MI250X GPU,且全部采用HPE Slingshot 11实现互连,目前的HPL性能稳居世界第一。
但值得注意的是中国也安装了两到三套新的超算系统,或许已经超过了Frontier,甚至有能力与充分调整后的Aurora竞争。虽然这些系统还未正式公布,这里我们也将其列入了前30名单。
计算效率:超过75%已是优秀,纯CPU系统更高
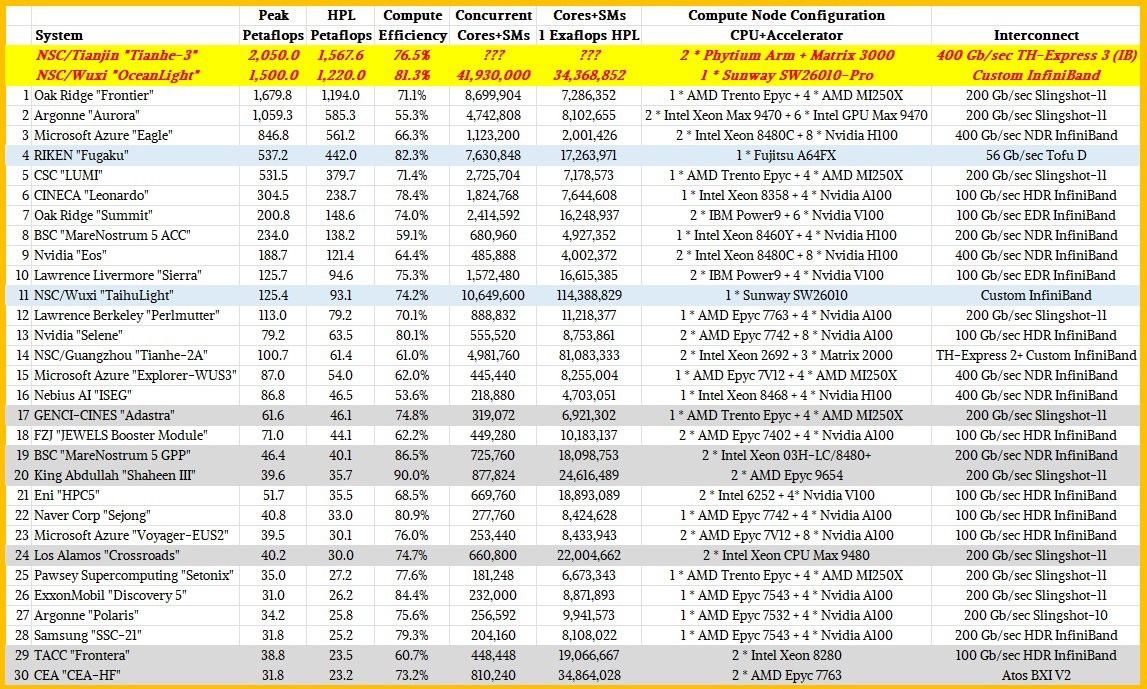
上表中,浅蓝色框的超算系统,采用搭载了大量矢量引擎的CPU,包括富岳和太湖之光(海洋之光也是)。灰色框中的超算则是仅使用CPU的系统,其余22台超算(不包括黄框内的两台中国超算)均采用CPU+加速器的混合架构组合,且大多选择了英伟达或者AMD的GPU。
而中国的两套超算系统——位于天津超算中心的天河三号系统和无锡国家超级计算中心的海洋之光系统,据传闻,天河三号的峰值性能将达到2.05百亿亿次,HPL性能约为1.57百亿亿次,这意味着也许它才是过去几年来的全球最强超算。而海洋之光的峰值性能约为1.5百亿亿次,HPL为1.22百亿亿次。
在超算领域,计算效率是衡量系统性能的重要指标,尤其是考虑到计算引擎成本的高昂。这里,我们采用HPL性能与理论峰值性能的比值来评估计算效率,理论上这个比值越高,说明系统架构越优秀。
具体来看,Frontier的计算效率为71.1%,而Aurora的计算效率仅为55.3%,约为理论峰值的一半。我们曾经估计,如果Aurora系统的63744个英特尔Max GPU都能发挥出31.5万亿次的算力,那么峰值性能就会超过2百亿亿次。但由于其计算效率低下,完全扩展后Aurora也落后于Frontier。如果Aurora能够将计算效率提升至60%,便有潜力超越Frontier。
相信随着英特尔和HPE对其开展全面测试和优化,未来Aurora的性能和效率将会进一步提高。目前我们看到的还只是采用英特尔Xe Link互连的初始版本,如今英伟达已经发布了第四代NVLink,AMD也推出第三代Infinity Fabric,升级到更高效的互连技术只是时间问题。
此次榜单前30名中,还有一些超算的计算效率低于平均值,这种情况并不稀奇。许多超算在进入榜单前,或上榜后的一段时间内,都在不断调优以提高计算效率。比如,我们当初曾听说Frontier的计算效率一度不到50%,所以它的最终亮相时间比预期要晚。其实每引入一个新技术——无论是CPU、GPU还是互连技术——都可能导致大规模的系统变动。
另外,我们观察到,纯CPU系统由于网络层次较少,计算效率通常高于混合架构系统。前30名中纯CPU系统的平均计算效率为77.1%,明显高于平均70.3%的搭载加速器的系统。但是,将并发级别与计算效率相关联时,我们没有发现明确的规律,高并发并不意味着低效率。
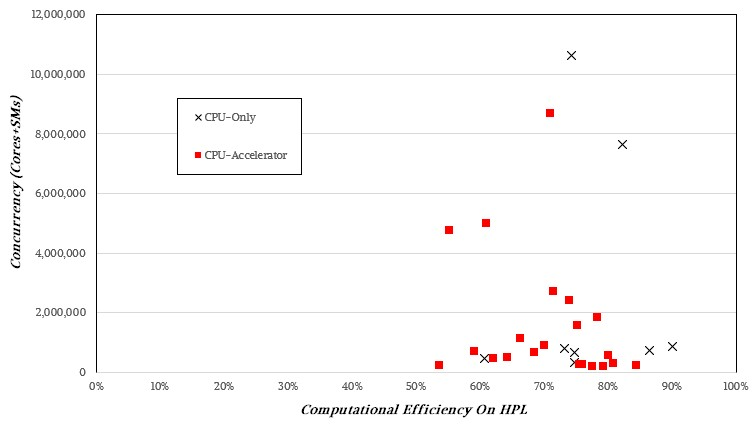
从数据上看,计算效率超过75%已属不易,达到80%到85%更是难得。令人惊叹的是,纯CPU的“Shaheen III”集群计算效率高达90%,这是自十年前日本理化学研究所推出超级计算机“京”之后无比罕见的。
其实对于大多数工作负载,HPCG基准测试或许更能反映超算的实际应用性能,它也是TOP500的重要指标之一。但通常HPCG的测试结果远低于HPL测试,只有几个百分点。两者的优劣,还有待进一步研究。
好文章,需要你的鼓励


开创电气越南基地形成80万台手持式电动工具年产能力
今天讲的出海案例是开创电气,一家金华手持式电动工具制造商,在越南基地完成首款产品验收并形成80万台年产能力。

当AI学徒“失控发疯“:中国科学院自动化研究所揭示强化学习崩溃真相,并找到了解决之道
本文介绍了中国科学院自动化所的研究,揭示了大型语言模型在多轮工具调用强化学习中崩溃的根本原因,并系统评估了五种监督信号对训练稳定性和泛化能力的影响。

一次实验室意外或将彻底改变计算领域
研究人员意外发现,标准MOSFET晶体管可同时模拟神经元和突触行为,形成"神经突触随机存取存储器"(NSRAM)。该技术仅需一至两个晶体管即可实现传统需数十乃至数百个元件才能完成的神经信号处理,且与现有硅基制造工艺完全兼容,良率达100%。未来有望应用于边缘AI及高能效神经形态芯片,长远或可挑战GPU地位。

牛津、MIT等顶尖机构联手揭露:当前最强AI智能体,在这些任务上表现堪比新手
牛津、MIT等机构联合发布GauntletBench,测试显示最强AI智能体完成率仅19%,而普通人类完成率超80%,揭示AI在时间感知、图形理解和三维推理上的真实短板。

