
微软首次推出27亿参数的Phi-2模型,性能超过许多大型语言模型
微软发布了一款名为Phi-2的人工智能模型,该模型表现出了不凡的能力,其性能可媲美甚至超越规模是其25倍的、更大、更成熟的模型。
微软在近日的一篇博文中宣布,Phi-2是一个拥有27亿参数的语言模型,与其他基础模型相比,它在复杂的基准测试中表现出了 "先进的性能",这些测试评估了推理、语言理解、数学、编码和常识能力。Phi-2现在通过微软Azure人工智能工作室的模型目录发布,这意味着研究人员和开发人员现在就可以将其集成到第三方应用程序中。
Phi-2由微软首席执行官Satya Nadella(如图)于11月在Ignite大会上首次发布,其强大的功能得益于该公司所称的“教科书质量”数据(专门针对知识),以及学习其他模型传递的洞见的技术。
Phi-2 的有趣之处在于,传统上,大型语言模型的能力总是与其总体规模密切相关,而总体规模是以参数来衡量的。参数越大的模型通常能力越强,但 Phi-2 的出现改变了这种状况。
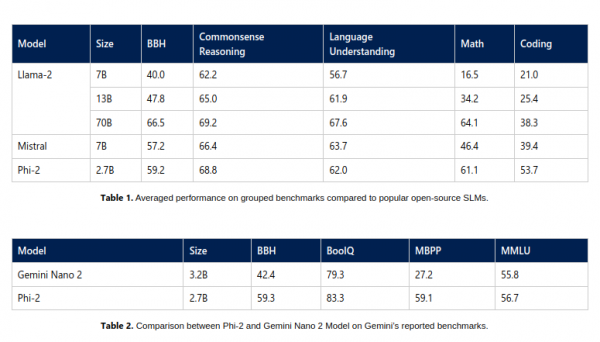
微软表示,Phi-2在某些基准测试中显示出与更大型的基础模型相匹敌甚至超越它们的能力,包括Mistral AI 70亿参数的Mistral、Meta Platforms公司130亿参数的Llama 2,甚至在某些基准测试中超过了700亿参数的Llama-2。
最令人惊讶的说法可能是,它的性能甚至超过了谷歌的 Gemini Nano,后者是上周发布的 Gemini系列LLM中效率最高的一款。Gemini Nano 专为设备上的任务而设计,可以在智能手机上运行,实现文本摘要、高级校对、语法修正以及上下文智能回复等功能。
微软的研究人员说,Phi-2涉及的测试非常广泛,包括语言理解、推理、数学、编码挑战等。
该公司表示,Phi-2之所以能取得如此优异的成绩,是因为它是用精心挑选的教科书级数据训练而成,这些数据旨在教授推理、知识和常识,这意味着它可以从更少的信息中学到更多的东西。微软的研究人员还使用了一些技术,允许从更小的模型中获取知识。
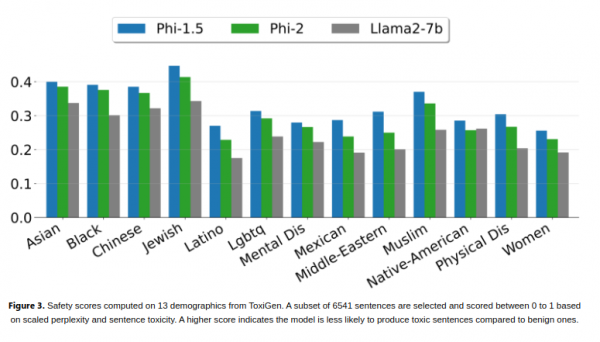
研究人员表示,值得注意的是,Phi-2可以不使用基于人类反馈的强化学习或者教学性微调等技术就实现强劲的性能,这些技术通常用于改善人工智能模型行为。尽管没有使用这些技术,但是与其他使用了这些技术的开源模型相比,Phi-2在减少偏见和有毒内容方面依然表现卓越。该公司认为这是量身定制的数据整理的功劳。
Phi-2是微软研究人员所称的“小型语言模型(SLM)”系列的最新版本。该系列第一个模型是 Phi-1,于今年早些时候首次发布,拥有13亿参数,针对基本的Python编码任务进行了微调。今年9月,该公司又推出了拥有13亿参数的Phi-1.5,使用新的数据源进行训练,其中包括用自然语言编程生成的各种合成文本。
微软表示,Phi-2的高效性使其成为研究人员探索增强人工智能安全性、可解释性和语言模型道德发展等领域的理想平台。
好文章,需要你的鼓励


Claude Sonnet 5 发布:编码、推理与工具使用能力全面提升
Anthropic于6月30日发布Claude Sonnet 5,相较前代Claude Sonnet 4.6在编程、推理、工具使用及知识工作方面均有显著提升。该模型可自主制定计划、使用浏览器和终端等工具,达到数月前需更大更贵模型才能实现的水平。安全评估显示其不良行为率更低。Sonnet 5默认开启自适应思维,采用更新的分词器,性能接近Opus 4.8但价格更低,现已面向所有订阅计划开放。

复旦大学、上海交大联手攻克机器人“眼手协调“难题:让AI真正理解动作背后的物理世界
复旦大学联合多机构提出A2World框架,通过210万条真实机器人轨迹进行动作条件化预训练,将学到的物理动力学先验同时迁移到仿真模拟和策略控制两个方向,在LIBERO和真实机器人任务上均取得当前最优表现。

AI高速扩张正悄然考验电网承载极限
人工智能基础设施的快速扩张不仅带来总用电量激增,更在改变电网的运行特性。AI训练任务高度同步、计算密集,推理任务则分散且难以预测,两者均可在极短时间内造成电力需求骤变。数据中心的地理集中分布进一步加剧局部电网压力。现有监管框架多基于稳定工业负荷设计,难以适应这类新型需求。专家指出,电网规划需从关注总能耗转向关注需求波动性与同步效应。

同济大学研发的“地空协作机器人“:如何让无人车和无人机在黑暗隧道里默契配合?
同济大学研发的FLISP系统,让无人车与无人机在水电隧道中无需建图、仅靠激光雷达实时协作导航,规划延迟仅7毫秒,成功率100%。
2023
12/13
10:32
分享
点赞

AI高速扩张正悄然考验电网承载极限
福特对AI失望,重新雇用350名经验丰富的工程师
首批四家云服务商加入CISPE欧盟云主权认证计划
2026 Eurobike 展会:最值得关注的电动自行车与新奇产品盘点
联想Legion 7i Gen 10游戏本评测:颜值在线,性价比存疑
杀毒软件已不够用?全面了解现代网络安全防护
大语言模型助力机器人理解模糊指令并聚焦关键细节
MIT AI与社会论坛:探讨AI对就业、民主等领域的深远影响
麻省理工学院新芯片助力微型机器人穿越复杂环境
扎克伯格承认Meta智能体AI进展未达预期
Rust 1.96 正式发布:引入全新 Range 类型体系
AI驱动的内存危机:苹果的困境也是所有人的困境
