
Gartner最新报告:全球数据库市场首破千亿美元,阿里云蝉联领导者成亚太唯一
1月3日,国际市场研究机构Gartner日前公布2023年度全球《云数据库管理系统魔力象限》报告,预测2023年全球数据库市场规模将首次突破1000亿美元,其中云数据库占比55%。
Gartner报告显示,阿里云跻身“领导者”象限,成为亚太地区唯一一家入选魔力象限的科技公司。这是阿里云连续第4年蝉联“领导者”,并在象限评估中斩获历史最好成绩。
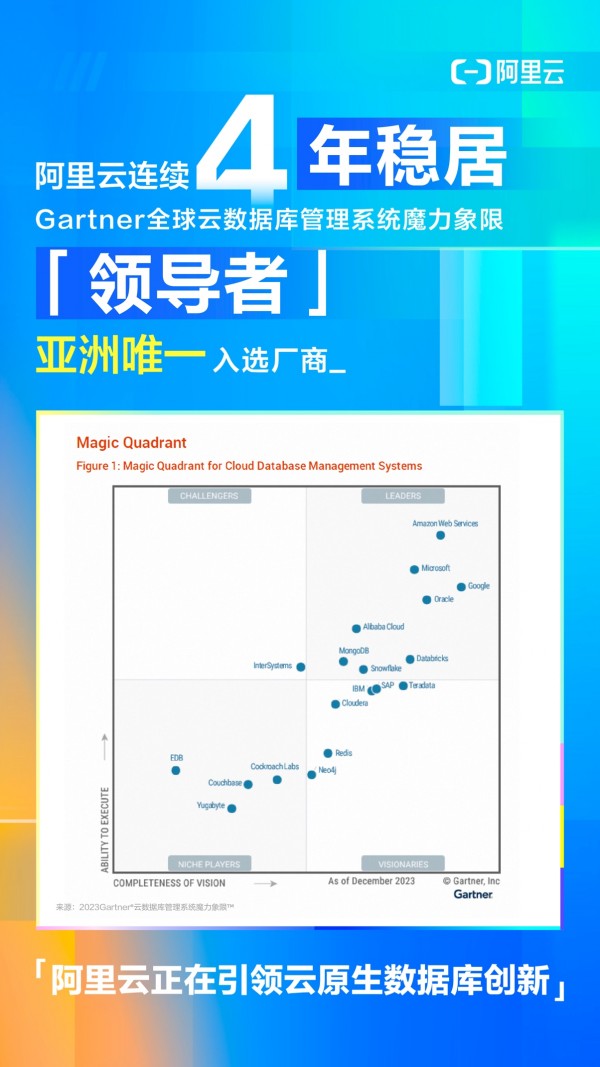
阿里云连续4年稳居Gartner®云数据库管理系统魔力象限报告领导者
数据库与芯片、操作系统并称为信息时代三大基石,是IT系统必不可少的核心技术,也是实体经济创新升级不可或缺的基础软件。Gartner云数据库魔力象限是全球业内最权威、标准最严苛的厂商综合评估报告之一,涵盖15项核心评估指标、240余项细则,2023年Gartner报告显示,数据库占全球软件市场的12.9%,2023年底将首次突破1000亿美元。
相较往年,数据库在2023年迎来“大洗牌”。根据Gartner报告,约1/3的传统数据库头部厂商跌出领导者象限,包括IBM、SAP、Teradata等;约2/3的“领导者”象限厂商综合评分下调。在此背景下,中国科技公司表现亮眼:阿里云连续第四年入选领导者象限,OceanBase、华为云、腾讯云、PingCAP均受“荣誉提及”肯定。
在Gartner魔力象限“愿景完整性”和“执行能力”两大评估维度中,阿里云均获得历史最好成绩。Gartner指出,阿里云培育了良好的数据库生态,其数据库产品也在广阔多元的场景落地,包括自动驾驶等前沿领域,在数据密集型的工业应用中独具优势。Gartner评价称,阿里云正在引领云原生数据库创新。
据了解,经过多年技术创新,以PolarDB为核心的瑶池数据库业界首创计算、内存与存储资源的“三层解耦”架构,并率先落地多主多写、基于内存池化的HTAP、Serverless、一体化分布式等全球领先的技术创新。
如今,瑶池数据库旗下涵盖关系型数据库PolarDB、数据仓库AnalyticDB、多模数据库Lindorm等多款自研云原生产品,实现全面Serverless化,给用户提供智能、一站式的数据管理平台服务,让数据管理开发像“搭积木”一样简单、好用。
最新数据显示,目前阿里云已连续多年位居中国数据库市场份额第一,服务于自然人税收管理系统、全国60%的省级医保信息平台、上海证券交易所等机构,以及中国移动、中国人寿、中国邮政、小米、丝芙兰Sephora、极氪汽车、美柚APP等企业。中国邮政引入云原生数据库PolarDB和数仓AnalyticDB,成功应对双11订单高峰;小米引入云原生多模数据库Lindorm,支持其全球最大规模的消费级AIoT平台运转。
Gartner报告还指出,除了中国,阿里云也在亚太以及中东、欧洲和北美等地区展开业务。以阿里云瑶池为代表的中国数据库技术产品,正走出国门,广泛落地于政务、金融科技、保险、零售、物流、制造等领域场景,受到全球各行业企业及用户的认可。
印尼大型流媒体公司RCTI+,基于PolarDB处理线上流量,能经济有效地自动扩缩容,为用户提供更流畅的观看体验;马来西亚最大的电商积分兑换APP Presto,通过采用PolarDB节省成本超30%;日本游戏公司Enish Inc,基于PolarDB与AnalyticDB,10天内就打造出一款新游戏的测试环境,大幅缩短开发周期。
好文章,需要你的鼓励


雷克萨斯LFA电动超跑2027年量产,将搭载固态电池
丰田旗下豪华品牌雷克萨斯正以纯电动版本复活经典跑车LFA。新车已在古德伍德速度节亮相,预计2027年量产,将采用丰田期待已久的固态电池技术。该技术承诺更高能量密度与更快充电速度,但丰田已多次推迟相关计划。新款LFA搭载电动动力系统,内饰配备Yoke方向盘与沉浸式数字座舱,车身尺寸与阿斯顿马丁DB12相近。面对比亚迪腾势Z等1500马力级竞品,雷克萨斯能否追上电动超跑赛道,值得关注。

慧眼难辨“何时何处“——慕课里AI通才的专业盲区,庆应义塾大学新出的这套考卷让15个顶级模型集体翻车
庆应义塾大学与英伟达推出AnyGroundBench,测试15个顶级视觉语言模型在手术、工业等五大专业领域的时空定位能力,揭示当前AI在专业场景下的系统性空间定位瓶颈。

科学家研究证明:我们并非生活在模拟现实中
加拿大不列颠哥伦比亚大学奥卡纳根分校的研究人员通过数学方法,对"模拟现实"理论给出了否定答案。研究人员米尔·法扎尔在《物理全息应用期刊》上指出,基于不完备性与不可判定性数学定理,现实无法仅通过计算来完整描述,它需要非算法性的理解,而这超出了算法计算的范畴,因此无法被模拟。尽管如此,"模拟宇宙"的观念短期内仍难以从公众讨论中消失。

清华大学与蚂蚁集团联合打造“数据科学AI考官“:AgenticDataBench如何给数据智能体打出一张精准成绩单?
清华大学与蚂蚁集团联合推出AgenticDataBench,含344道真实数据科学任务和433个精细技能标签,系统评测12种主流数据智能体配置的能力边界与短板。
2024
01/03
11:46
分享
点赞

科学家研究证明:我们并非生活在模拟现实中
苹果与博通签署高达300亿美元芯片采购协议
零信任网络访问如何从根本上消除隐性信任
Crusoe扩展AI平台:推出无服务器微调与自助推理部署
Oratomic完成3亿美元融资,仅需2万个量子比特造出实用量子计算机
Anthropic将Claude Cowork智能体扩展至网页端与移动端
OpenAI发布延迟模型,美国AI监管混乱引发企业隐忧
微软押注企业AI需要工程师而非庞大销售团队
Anthropic揭开Claude AI黑箱:J-space技术带来模型内部可见性突破
英格兰银行获授权监管亚马逊、谷歌等科技巨头
酷睿Ultra战力Plus,英特尔携九大合作伙伴亮相Bilibili World 2026
iOS 26.5.2正式发布,包含逾20项安全修复,Claude协助发现漏洞
