
Runway的AI视频魔法:唤起脑海深处的原力
你可曾记得20 世纪 80 年代每当麦当娜在她的巡回演唱会中每次奏响热门歌曲“La Isla Bonita”时,她身后的巨大舞台屏幕上就会播放出超现实的“夕阳下云彩”的移动图像?
如今,如果也想“只需输入文字”就能将你脑海中的景象转变成视频,其最简单的方法是通过Runway发布的从文本到视频模型工具来制作视频。
Runway AI 是来自纽约一家名为 Runway 的初创公司的基于人工智能的工具集合。在这些工具中,Runway Gen-1 是一个 AI 视频到视频的 AI 生成器,通过现有视频,将 AI 效果应用于已有媒体。因此,需要提供一个基础视频供模型执行其后续工作。而 Runway Gen-2 是一个 AI 文本/图像到视频的生成器。不需提供任何视频,它可以接受图像或文本作为提示,并按照这些提示生成视频。
凭空创作视频最简单的方式就是用Gen-2通过提供一段文字,就可以为你生成一段视频。
可以访问:https://runwayml.com/来体验这两个模型,选择相应的模型输入提示词就可以根据需要修改的设置并生成你想要的视频。
Runway提供了很多基于人工智能的编辑工具,包括:视频到视频(Gen-1)、文本/图像转视频(Gen-2)、删除背景、文字转图像、图像到图像、训练你自己的生成器、无限影像、展开图片、帧插值、擦除和替换、背景混音、图像变化、3D捕捉、3D纹理、修复、颜色等级 (LUT)、超慢动作、模糊脸部、景深、场景检测、提取深度、干净的音频、消除沉默等
今天,我们就用最简单的方式体验生成视频这个功能。就拿我喜欢的一首歌做为示例,这首歌就是《You Raise Me Up》它鼓舞了许多暂时深处困境并无法自拔人。其旋律从舒缓到振奋,层层递进,让人逐渐摆脱出当前的悲伤与孤单,勇敢迎接必将光明的明天!
首先我们把要把这首歌词变成Gen-2模型能理解的提示。如果你觉得这一步可能比较费脑子的话,我们也可让GPT-4来帮忙。GPT根据歌词给出的提示词是:
视频开始于一位疲惫、失落的人物独自坐在宁静的自然环境中,四周被蔚蓝的山峦和宽广的海洋包围。镜头慢慢拉近,捕捉到他的眼神中流露出的孤独与忧郁。
画面转换,出现一个亲切的人物静静地走到他身边坐下,温暖的手臂环绕着他的肩膀。这一举动带来安慰和力量,他的眼神开始显露出希望和决心。
随着音乐的升华,画面展示这位人物站立起来,在他的亲友的支持下,他开始攀爬高山,勇敢地面对暴风雨中的惊涛骇浪。镜头中,他从山顶望向远方,面对风暴的海面,彰显出内心的力量和勇气。
画面再次转变,展示他在亲友的肩膀上看向更远的地方,似乎触及了生命的极限。此时,画面捕捉到他们共同的笑容,体现出相互支持和无私的爱。
最终画面,随着夕阳的落下,他们一起在海边行走,每个人的心中都有着不同的饥渴,但共同的体验让他们感受到生活的完整和奇迹。随着镜头的拉远,音乐缓缓降低,留下一种宁静而充满希望的氛围。
其英文:
The video begins with a weary, despondent individual sitting alone in a tranquil natural setting, surrounded by azure mountains and expansive seas. The camera slowly zooms in, capturing the loneliness and melancholy in his eyes.
The scene transitions to a kind figure quietly walking over and sitting beside him, with warm arms wrapping around his shoulders. This gesture brings comfort and strength, and hope and determination start to shine in his eyes.
As the music swells, the scene shows the individual standing up, with the support of his loved one, he begins to climb mountains and bravely faces the stormy seas. From the mountaintop, he looks into the distance, confronting the tempestuous ocean, demonstrating inner strength and courage.
The scene shifts again, showing him on the shoulders of his friend, looking toward even greater distances, seemingly reaching beyond the limits of life. At this moment, the camera captures their shared smiles, reflecting mutual support and selfless love.
In the final scene, as the sun sets, they walk together along the seaside, each with different yearnings in their heart, but the shared experience brings a sense of completeness and wonder to their lives. As the camera pulls away and the music slowly fades, a serene and hopeful atmosphere lingers.
这有5段文字,也就是需要用5个场景来呈现。所以我们需要一个场景一个场景的去生成。
注册好进入主页面:
进入Gen2模型页面:
我们可以看到,它既可以根据你有的视频资产生成视频也可以通过文字,我们这次采用文字生成视频。
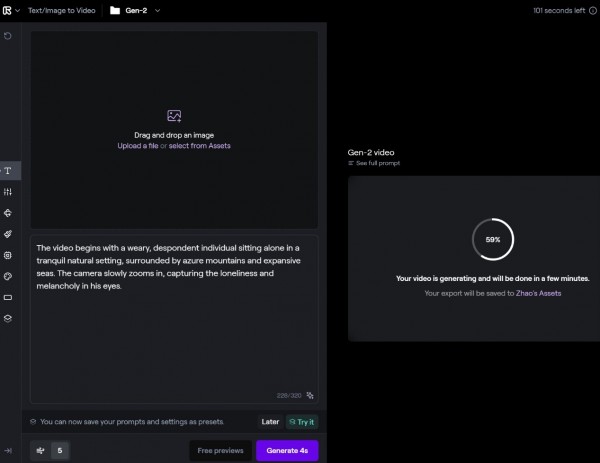
插入第一段文字后就会生成第一个场景。模型会为你产生一段4S 的视频。视频会呈现在右侧,生成好的视频就可以下载并保存。
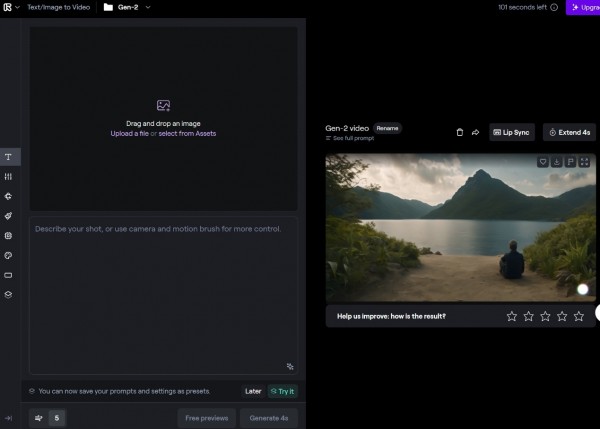
最后可以将5段生成好的视频进行拼接,或者再用Gen1模型继续AI拓展、丰富,希望有兴趣的读者朋友们能继续探索……
今天,生成视频已十分简单、便捷,但人工智能生成的最长视频仍然是以秒计,经常会出现抖动动作和明显的缺陷:如扭曲的手和面部。相信随着技术的不断进步,这些问题会得到很好的改善。
好文章,需要你的鼓励


Ode with Anthropic:押注AI服务成为企业级市场未来
Ode是由Anthropic、黑石、高盛等机构支持的合资企业,专注于向大型企业派驻前沿工程师,以少数工程师取代大批顾问。TechCrunch播客《Equity》采访了Ode联合创始人Chris Taylor和Eddie Siegel,探讨为何众多企业AI试点项目无法落地投产,以及AI原生服务为何有望成为科技领域最重要的赛道之一。

南加州大学团队揭示:AI抑郁症检测中藏着一个让准确率虚高23%的“致命漏洞“
南加州大学团队发现语音抑郁检测领域存在数据漏洞,并提出CLeaD跨语言对比对齐框架,揭示模型规模越大跨语言性能越差的反直觉规律。

用Gemini几分钟规划你的暑期旅行
本文介绍如何利用Gemini AI助手快速规划暑期旅行。ZDNET撰稿人Elyse Betters Picaro通过向Gemini输入详细提示词,成功生成迪士尼世界家庭旅行的初步行程文档,内容涵盖航班信息、Airbnb住宿建议及景点安排。测试表明,Gemini能自动创建Google文档并汇总关键信息,但在优先推荐谷歌自有平台方面存在一定偏向。ChatGPT也可完成类似任务,但不支持直接生成Google文档。

机械手臂终于学会“看深度“了——KAIST联合POSTECH研究团队让机器人规划与执行真正说同一种语言
KAIST等机构提出3D HAMSTER,通过为视觉语言模型加入深度编码器和几何重建损失,让机器人规划器直接输出三维轨迹,解决了分层机器人系统中规划与执行的维度不匹配问题,显著提升了操作鲁棒性。
2024
04/30
13:45
分享
点赞

AGI融资7000万美元,收购保险公司并将其改造为AI原生运营
Creatio推出对话式开发工具与AI Studio,打破无代码平台边界
Emergent Labs完成1.3亿美元C轮融资,成为最新AI独角兽
量子计算融入数据中心:混合架构时代正式开启
苹果起诉OpenAI:AI竞争新战场正转向人才争夺
OpenAI首款消费设备曝光:便携式智能音箱即将亮相
波多黎各用清洁氢能升级偏远微电网,提升灾后供电韧性
Whatnot收购AI推荐公司Shaped,强化直播购物实时个性化能力
ELIZA:首个聊天机器人背后的多重人格与隐藏秘密
研究显示特斯拉LFP电池健康度表现优于镍基电池
苹果携手阿里云通义千问,Apple Intelligence获批在华上线
微软借助AI发现漏洞,单次发布破纪录的570个安全补丁
最热门的 AI 模型:它们的功能和使用方法
这款古怪的 AI 智能手机可以创建你的数字分身
Faireez 获 750 万美元融资,为租赁市场提供 AI 驱动的酒店式管家服务
Broadcom 大获全胜:70% 大型 VMware 客户购买其最全面解决方案
Peer 获得1050万美元元宇宙引擎投资,推出3D个人星球功能
获 3000 万美元融资,Crogl 发布面向安全分析师的全新 AI "钢铁侠战衣"
Turing 获得 1.11 亿美元融资,估值达到 22 亿美元,为 OpenAI 等大语言模型公司提供关键代码支持
Tavus 推出系列 AI 模型,实现实时人脸交互技术突破
Welevel 获得 570 万美元融资,革新程序化游戏开发
AI 驱动的卓越运营:企业如何通过人人可及的流程智能提升成功
