
把两款主力大模型免费,百度是怎么想的? 原创
在互联网企业的竞技场上,价格战早已司空见惯。通常,价格战会出现在行业发展的中后期,那时技术和市场都趋于成熟、竞争格局明朗,厂商通过降价策略抢夺蛋糕。但在大模型行业,情况却不尽相同,这场价格战打得异常激烈且提前到来,企业们尚未收回前期烧掉的钱,竞争的火焰就已熊熊燃起。
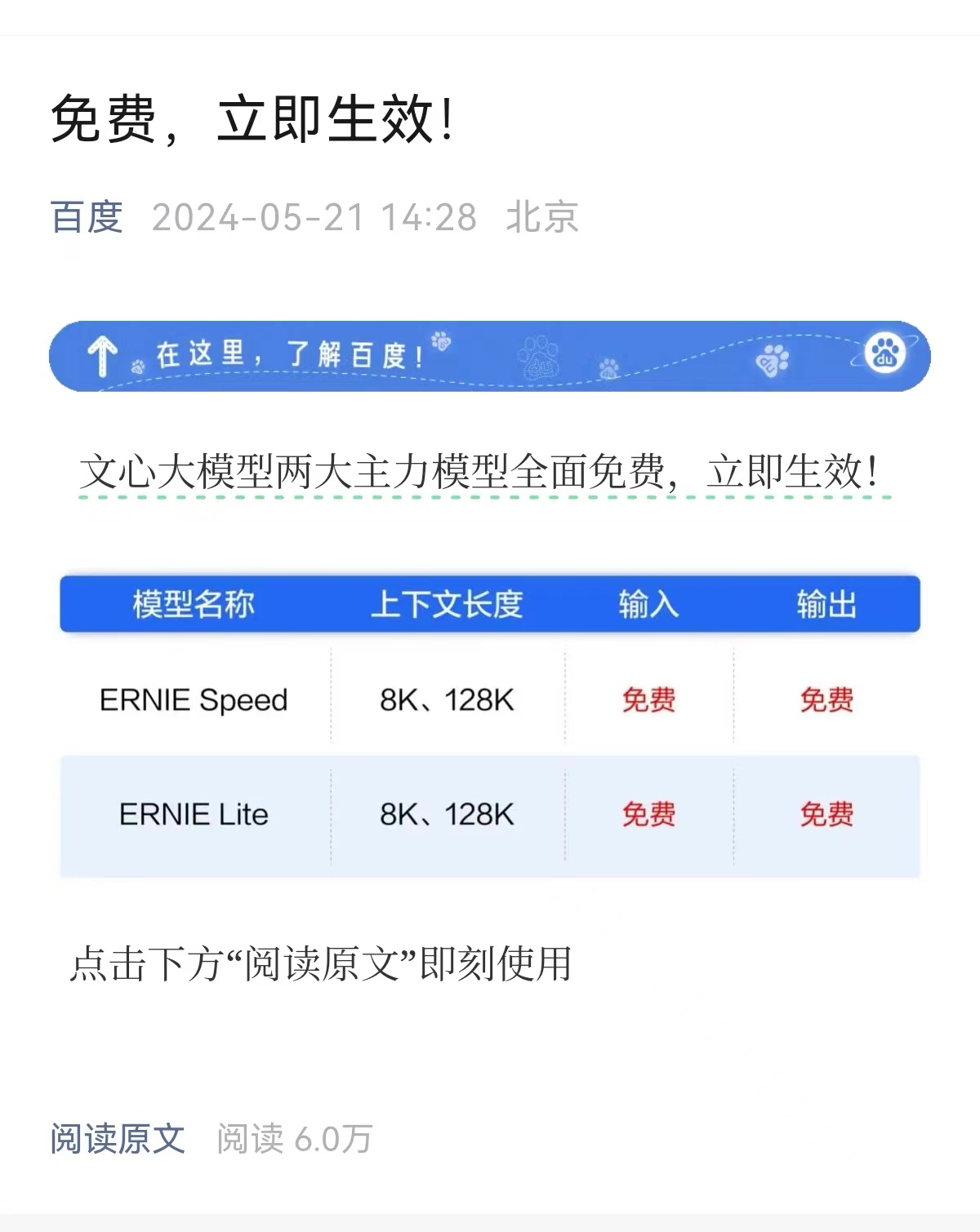
从上个月初开始,国内的大模型企业纷纷调降产品和服务的价格。在一连串“全线降价”和“远低于行业均价”的营销声浪中,百度智能云直接宣布两款主力模型免费,且立即生效,此举无疑撼动了整个大模型市场的价格体系。
那么,百度云为什么要采取这样激进的策略?
大模型厂商集体“赔钱赚吆喝”?
事实上,国内这场大模型价格战是从AI公司DeepSeek开始的。5月6日,DeepSeek率先将旗下对标GPT-4的大模型DeepSeek-V2价格大幅下调至GPT-4-Turbo的1%,每百万tokens仅需1元。紧接着,智谱AI和字节跳动也相继调整价格,形成了一股降价潮。
面对这一趋势,其他模型厂商不得不加入价格战。阿里云将通义千问主力模型Qwen-Long价格直降97%,声称“击穿全球底价”。而仅过了数小时,百度智能云便宣布其文心大模型的ENIRE Speed和ENIRE Lite模型全面免费。据了解,该两款模型免费开放半个月内,日调用量翻了10倍。
当前的价格战主要体现在token降价的层面上。从商业模式的角度看,大模型厂商把经过训练的模型以API形式销售,计费法则一般按token所对应的汉字、字母的使用量来计算,有些类似于我们熟悉的手机流量套餐,只不过变了计算单位。
不过要注意的是,大模型行业尚未成熟,核心依然是提升技术和拓展应用。当前的价格战不仅是厂商们对市场焦虑的反应,也显示了在用户增长停滞和缺乏市场爆款应用的背景下,降价成为吸引开发者和用户的首选策略。大模型厂商试图以价格上的“退”,换取用户增长上的“进”。
而对于兼具大模型厂商和云服务商双重身份的百度云、阿里云、腾讯云来说,这场价格战可能不只是单纯的价格竞争,更是一种通过低价大模型吸引用户,进而拉动背后云消费的战略。
当然,这并非是盲目降价,随着大模型技术的不断发展和优化,大模型推理成本已经大幅下降,模型训练所需的边际时间和资源也逐渐减少,因此大模型厂商们有了更多底气来调整价格。
百度创始人、董事长兼首席执行官李彦宏就曾透露,相比一年前,文心大模型的训练效率提升到了原来的5.1倍,周均训练有效率达到98.8%,推理性能提升了105倍,推理成本则降到了原来的1%。换言之,客户原来一天调用1万次,同样成本之下,现在一天可以调用100万次。
百度智能云事业群总裁沈抖强调,“价格只是消费者选择大模型的一个考量因素。比起价格,更重要的是模型效果、应用场景、已落地案例。这几年,百度一直在用技术手段降低企业使用大模型的成本,尤其是业界最高效的AI异构算力管理平台和‘一云多芯’。我们希望通过降价让大家创新的胆子更大一些、步子更快一些,快速探索并复制更多大模型可能的应用场景。”
不论怎样,大模型价格下降对市场和消费者都是利好,AI应用门槛降下来,企业创新试错的成本在很大程度上减小了,就会有更多的人使用,而大的使用量,才能打磨出好模型。
AI大模型给百度带来了什么?
作为中国首个发布大模型的平台,百度在这一领域拥有明显的先发优势,AI产品体系相对完备。百度的文心大模型系列涵盖了旗舰版的ERNIE 3.5和4.0,和轻量版的ERNIE Speed、Lite、Tiny等多个版本。这次百度免费开放的便是ENIRE Speed和ENIRE Lite这两款小尺寸模型,这两款产品都在今年3月推出,支持8K和128k的上下文长度。

根据官方介绍,百度自研的大语言模型ENIRE Speed,通用能力优异,适合作为基座模型进行精调,更好地处理特定场景问题,并具备优秀的推理性能。而ENIRE Lite作为百度自研的轻量级大语言模型,兼顾优异的模型效果与推理性能,适合低算力AI加速卡推理使用。
尽管这两款模型的规模不大,但对于初创企业和开发者来说或许已经足够。百度创始人、董事长兼首席执行官李彦宏在2024百度AI开发者大会上表示:“小模型推理成本低,响应速度快,在一些特定场景中,经过SFT(监督)精调后的小模型,它的使用效果可以媲美大模型。这就是我们发布ERNIE Speed、Lite、Tiny三个轻量模型的原因。”
从文心大模型的实际应用情况看,据了解,其每日处理的Tokens文本数量约为2500亿,日均API调用量超过2亿次,服务的客户或企业数量达到8.5万,可以看出市场对百度AI技术的需求强劲。
AI大模型也为百度云带来了新的收入来源。反映在财务数据上,百度2024年Q1财报显示,百度总营收315亿元,同比增长1%,智能云业务部分营收47亿元,同比增长12%,其中有6.9%来自外部客户使用大模型及生成式AI相关服务。以此计算,当季生成式AI给百度云带来的收入约为3.24亿元。
在当前激烈价格战的背景下,厂商们急需在持续的技术创新和成本控制之间找到平衡点,百度亦是如此。而这场提前开始的价格战,大概率会加速大模型行业的“大浪淘沙”,但这似乎也是行业发展过程中的必经阶段。
好文章,需要你的鼓励


三星Galaxy S26 Ultra最高优惠435美元,多款智能家居产品同步特惠
本轮优惠涵盖多款热门科技产品:Galaxy S26 Ultra捆绑Galaxy Buds 4 Pro可享325美元折扣,翻新开箱版最高优惠435美元;Galaxy Z Flip 7全新机型立减200美元,翻新版最低仅需701.99美元;谷歌最新款Nest门铃翻新版近百美元优惠;TCL TAB 10 Gen 4安卓平板降至150美元历史低位。三星旗舰产品翻新开箱版正成为当前最具性价比的选择。

AI助手越权了?南加州大学等机构揭示大模型代理的“权限失控“问题
FORTIS是专门测量AI代理"越权行为"的基准测试,研究发现十款顶尖模型普遍选择远超任务需要的高权限技能,端到端成功率最高仅14.3%。


荷兰Nebius团队:给AI“起草员“瘦身,大模型推理速度最高提升5倍的秘密
荷兰Nebius团队提出SlimSpec,通过低秩分解压缩草稿模型LM-Head的内部表示而非裁剪词汇,在保留完整词汇表的同时将LM-Head计算时间压缩至原来的五分之一,端到端推理速度超越现有方法最高达9%。
2024
06/29
09:00
分享
点赞

OpenAI为ChatGPT Pro推出个人财务管理新功能
赛格威全新Xaber 300电动越野摩托车正式开售,最高时速达96公里
OpenAI再度重组高管架构,全力押注AI智能体战场
出门在外也能用!OpenAI 将 Codex 接入 ChatGPT 移动端
Google Gemini应用图标迎来细微配色调整
Synetic在2026嵌入式视觉峰会上发布LYNX计算机视觉SDK
生数科技发布世界动作模型Motubrain,为机器人智能带来"无限可能"
xAI推出编程智能体Grok Build,加入竞争激烈的AI编程赛道
硅谷度假胜地湖太浩面临能源危机,AI热潮推高电价
三星Galaxy S26 Ultra最高优惠435美元,多款智能家居产品同步特惠
华为坤灵三年实践,智能化如何普惠中小企业?
谷歌向"AI优先"智能手机迈出关键一步
DeepSeek之后,中国人形机器人以“群体智能”再次掀起技术浪潮
QwQ-32B模型成本地部署福音,通义App可第一时间体验
入局智驾的印奇,看到了怎样的未来?
成本打到6万以下,手把手教你用4路锐炫显卡+至强W跑DeepSeek
千里科技亮相吉利AI智能科技发布会,共启“AI+车”新纪元
天翼云CPU实例部署DeepSeek-R1模型最佳实践
京东云与宝德计算战略签约,共绘分布式存储与智算新未来
全球AI顶会AAAI 2025 在美开幕,产学研联手的“中国队”表现亮眼
蚂蚁数科提出创新跨域微调框架ScaleOT入选全球AI顶会AAAI 2025
国产软件再破记录!阿里云PolarDB数据库登顶TPC-C双榜第一
