
亚马逊云科技将托管Slurm引入Amazon ParallelCluster云超级计算机
不知不觉之间,亚马逊云科技的计算、存储与网络容量租赁业务已经运营了近二十年时间。时至今日,很多朋友仍然有个误解,认为亚马逊云科技只是亚马逊旗下的一家子公司,专以硬件资源租赁为核心业务。但如今,出租第三方软件(包括操作系统、中间件、数据库以及应用程序)已经在亚马逊云科技的收入中占据半壁江山,该公司的托管服务业务也一直在保持增长。
事实上,当下我们已经很难在硬件、软件和服务之间划分出明确的边界。可能也正因为如此,亚马逊才没有在其云业务的季度财报当中给出清晰分类。亚马逊云科技最近公布的一项全新超级计算托管服务,则进一步模糊了这条边界。唯一可以肯定的,就是亚马逊云科技将继续为客户承担起越来越多的IT复杂性要素,并借此换取可观的经济回报。
新的并行计算服务属于亚马逊云科技于2016年公布的AWS ParallelCluster云超级计算机项目的扩展版本,而这距离当时全球最大的在线书店发布EC2计算加S3对象存储、并掀起第三波务实主义计算浪潮(且最终取得成功)仅仅过去了十年时间。
凭借上周公布的这项并行计算服务,亚马逊云科技的技术人员和自动化工具可以借助其基础设施之上的高性能计算(HPC)及AI客户设置并管理由亚马逊计算、存储和网络资源所构成的集群,同时配合开源Slurm工作负载管理器及集群调度程序进行控制。
Slurm的全称为单一Linux资源管理实用程序(Single Linux Utility for Resource Management),最初是由劳伦斯利弗莫尔国家实验室开发而成,旨在为高性能计算集群的管理工作提供开源工具,也是目前得到广泛应用的集群管理器及工作负载控制器之一。全球约有半数超级计算机集群,都在使用Slurm管理运行在超算设施之上的应用程序。自2010年以来,Slurm的开发工作一直由SchedMD牵头,这家公司还为这款工作负载管理器提供商业级支持。除此之外,包括全球多处超大规模高性能计算中心在内的其他组织也在为Slurm的项目发展做出贡献。
根据亚马逊云科技高级计算及模拟业务总经理、前Inktank Ceph块存储系统工程总监Ian Colle介绍,亚马逊云科技正在将所有高性能计算工作负载管理器以插件形式引入这项新服务。Altair PBS Pro及Altair Grid Engine(来自2020年9月对Univa的收购)可以根据需求插入该并行计算服务,IBM的Spectrum LSF(2011年10月通过收购Platform Computing获得)、Bright Cluster Manager(由英伟达于2022年1月收购获得)以及Adaptive Computing的Moab(此前一直没有得到云服务商或者超大规模基础设施运营商的广泛采用)也均可顺畅接入。
Colle在采访中解释称,“我们正与各方积极讨论,思考如何做出有意义的探索。这项服务的基本思路,就是帮助那些已经围绕特定工作负载管理器构建起单体脚本库及完整工作流程的客户减少业务摩擦。他们则在交流中表示,如果想要将他们的工作负载迁移到云端,我们就必须拿出更加简便易行的解决方案。”
亚马逊云科技已经有数千家客户将传统高性能计算的模拟和建模类工作负载迁移到云端,因此我们有理由怀疑其中不少客户已经在使用预配置的AWS ParallelCluster高性能计算系统。AWS ParallelCluster采用AMD/英特尔X86计算实例,以及亚马逊原研的Graviton Arm CPU作为其计算引擎。AWS ParallelCluster实例还可以通过英伟达和AMD GPU加速器,以及亚马逊自家的Trainium加速器实现增强,从而在AI训练场景下拥有更强的性能表现。
AWS ParallelCluster中使用的亚马逊云科技实例,将通过由云巨头开发的以太网Elastic Fabric Adapter实现互连,其中还包括对网络上ROMA内存寻址的支持。AWS ParallelCluster包含一套基于开源Lustre技术栈的托管并行文件系统,名为FSx。
下图所示,为用于计算流体动力学的Simcenter Star-CCM+应用程序在AWS ParallelCluster上的设置方式:
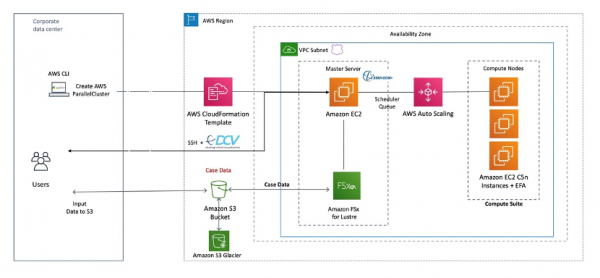
问题的关键也就在这里。这些ParallelCluster多云HPC系统还搭配有AWS Batch——属于运行在Kubernetes容器之内的容器化高性能计算与AI工作负载之上的一层,负责管理AWS ParallelCluster上各pod应用程序的具体部署方式。虽然一部分高性能计算客户已经转向Kubernetes容器,但仍有相当数量的客户继续在集群上以裸机模式运行这类负载,且明确表示不愿为了云迁移而额外将Kubernetes引入其工作流程。也就是说,相当一部分客户只接受在集群之上使用SLurm进行应用程序调度,而不打算把自己的应用程序强行塞进AWS Batch。他们对于Slurm的认可和坚持,也迫使亚马逊云科技不得不同时支持Slurm和AWS Batch——我们猜测在多数情况下,客户还是会优先选择Slurm而非后者。
HPC集群的设置流程相对简单,但后续升级却往往非常麻烦。根据Colle的介绍,这也是Slurm如今以服务形式向客户交付的一大理由。
Colle解释道,“高性能计算用户面临的核心挑战之一,就是每次升级时都必须关闭整个集群,再修复所有版本的软件才能全面完成内容升级,之后再重新启动。而如今,凭借我们提供的托管Slurm服务,亚马逊云科技将为客户们承担起所有这些问题,并且能够在后台以极短的停机时间完成升级。我们进一步消除了长久以来所强调的所谓「无差别繁重工作」,将这部分负担从客户肩头卸下,并转手交由服务来打理。”
另外一个好处,在于客户可以继续保持当前本地高性能计算集群的使用习惯,以完全相同的命令来运行自己在亚马逊云科技设施上租用的云集群。他们还能在云端实现一系列根本不可能在本地实现的操作,例如:同时启动大量节点、以更快速度运行自己的作业,甚至是保存模拟数据后关闭、而后在需要时再次启动。而且只要他们针对Slurm进行了特殊调整以设置并跟踪资源分配,那么在未来启动AWS ParallelCluster容量时,所有这些也都将随之转移。
这项并行计算服务现已在美国东部(俄亥俄州)、美国东部(北弗吉尼亚州)、美国西部(俄勒冈州)、欧洲(法兰克福)、欧洲(斯德哥尔摩)、欧洲(爱尔兰)、亚太地区(悉尼)、亚太地区(新加坡)以及亚太地区(东京)等区域正式上线。
Slurm服务要求客户始终运行相应的Slurm管理节点,该节点能够根据容量需求进行扩展和收缩,借此限制节点的运营成本。对于被放入AWS ParallelCluster的EC2实例,客户需要额外付费才能使用Slurm。Colle表示根据用例和实例的具体情况,客户可能需要为该集群额外承担5%到10%之间的成本。Colle同时强调,从目前的情况看,早期采用客户并没有被Slurm方案的这份额外成本所阻碍,反而乐于享受这份增值服务。
来源:至顶网软件与服务频道
好文章,需要你的鼓励


苹果在印度恢复银行卡支付功能,距暂停已逾四年
苹果已开始在印度分阶段恢复Apple账户的信用卡支付功能,用户可绑定Visa和Mastercard信用卡及借记卡,用于购买iCloud+、Apple Music订阅及App Store应用。此前,由于印度储备银行于2021年推出新的周期性支付监管框架,苹果于2022年5月暂停了该支付方式。此次恢复标志着苹果在适应各国本地化监管要求方面的持续努力,同时也引发外界对苹果是否将在印度推出Apple Pay的新猜测。

腾讯混元团队打破AI“记忆瓶颈“:让大模型像人一样拥有超长记忆的新突破
腾讯混元等机构提出HiLS-Attention,通过端到端可学习的分层稀疏注意力机制,让大模型在超长上下文推理中比全量注意力快14倍,同时检索准确率更高。

Bookshop.org确认今年将推出Kobo电子书阅读器支持
Bookshop.org创始人Andy Hunter证实,与Kobo的合作集成将于今年落地。此前该计划历经多次推迟,网页措辞一度从"2026年"改为"未来某时"。Hunter表示,双方已就商业条款达成一致,工程团队正将资源重新投入Kobo支持开发,但尚无具体上线日期。该集成将支持数字版权管理要求,让用户通过Bookshop.org购买电子书,同时支持独立书店。

DeepSeek-AI与北京大学联手破局:AI聊天机器人“慢速打字“的终极解决方案
DSpark是DeepSeek与北京大学提出的投机解码框架,通过半自回归生成和置信度调度验证两项创新,将DeepSeek-V4用户生成速度提升60%至85%。
2024
09/11
10:42
分享
点赞

苹果在印度恢复银行卡支付功能,距暂停已逾四年
Bookshop.org确认今年将推出Kobo电子书阅读器支持
WeWard新增"步行模式":走够步数才能解锁应用
X将通过私信通知用户其互动帖子被社区笔记纠错
"慢社交"应用Roost:让消息像真鸟一样飞行
Truecaller与印度电信监管机构就反垃圾电话规则展开公开交锋
Block与46州达成4500万美元和解,涉Cash App欺诈纠纷
欧盟威胁对Meta开出罚款,剑指Facebook和Instagram上瘾性设计
Disney+考虑推出免费流媒体内容层级
HyperTexting:将开放网络变成类社交媒体信息流的新应用
TV Time关闭之际,创始人打造新追剧应用Bingers
Telegram短链域名t.me因制裁合规问题短暂下线后已恢复
“专业服务产品”,亚马逊云科技Marketplace(中国区)来了
DeepSeek狂飙,别让安全隐患成为“定时炸弹”
用MFA替代“password”,防御值加99%
DeepSeek登场,企业级AI构建路径解析
2025年企业领导者必知的生成式AI技能与教育趋势
AWS选择Iceberg联合分析平台
亚马逊云科技携手SAP助力BBC经济高效迈向云端 简化IT系统
亚马逊云科技携手Adobe为品牌提供Adobe Experience Platform解决方案,以深刻洞察提升客户体验
亚马逊云科技re:Invent 2024大会回顾:AI创新扎根各细分市场
亚马逊云科技CEO在re:Invent大会主题演讲中强调的九项创新
