
腾讯混元发布并开源图像模型2.1,支持原生2K生图
9月9日深夜,腾讯发布并开源混元最新的生图模型“混元图像2.1(HunyuanImage 2.1)” 。该模型综合能力业界领先,支持原生2K高清生图。
混元图像2.1模型在开源后,在Hugging Face模型热度榜热度迅速攀升,一跃而成全球第三热门模型。在该榜单前八名中,腾讯混元模型家族包揽三席。
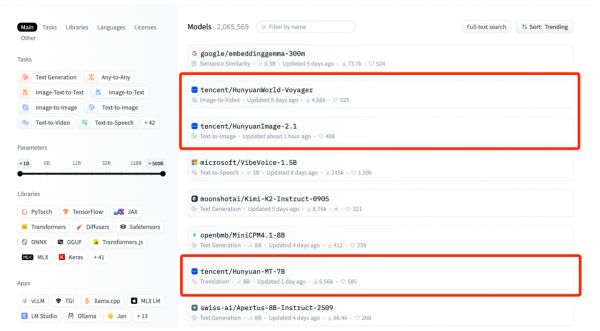
同时,腾讯混元团队透露,即将发布原生多模态图像生成模型。
混元图像2.1在2.0架构的基础上全面升级,更加注重生成效果与性能之间的平衡。新版本不仅支持中英文的原生输入,还能够实现中英文文本与复杂语义的高质量生成。同时,在生成图片的整体美学表现和适用场景的多样性方面,都有了显著提升。
这意味着,设计师、插画师等视觉创作者能够更加高效、便捷地将自己的创意转化为画面。无论是生成高保真的创意插画,还是制作包含中英文宣传语的海报和包装设计,亦或是复杂的四格漫画与连环画,混元图像2.1都能为创作者提供快速、高质量的支持。
混元图像2.1是一款全面开源的基座模型,不仅具备业界领先的生成效果,还能够灵活适配社区多样化的衍生需求。目前,混元图像2.1的模型权重和代码已在Hugging Face、GitHub等开源社区正式发布,个人和企业开发者均可基于这一基础模型开展研究,或开发各类衍生模型与插件。
得益于更大规模的图文对齐数据集,混元图像2.1在复杂语义理解和跨领域泛化能力上有了显著提升。它支持最长达1000个tokens的提示词,可精准生成场景细节、人物表情和动作,实现多物体的分别描述与控制。此外,混元图像2.1还能够对图像中的文字进行精细控制,使文字信息与画面自然融合。

(混元图像2.1亮点1:模型对复杂语义理解能力强,支持多主体分别描述与精确生成。)

(混元图像2.1亮点2:对图像中的文字和场景细节的把控更为稳定。)

(混元图像2.1亮点3:支持风格丰富,如真人、漫画与搪胶手办等,并具备较高美感。)
腾讯混元图像模型2.1处于开源模型中的SOTA水平。
从 SSAE(Structured Semantic Alignment Evaluation) 的评估结果上看,腾讯混元图像模型2.1在语义对齐上目前达到了开源模型上最优的效果,并且非常接近闭源商业模型 (GPT-Image) 的效果。

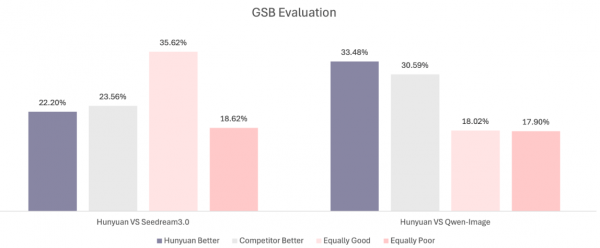
同时,GSB(Good Same Bad) 评测结果表明,HunyuanImage 2.1的图像生成质量与闭源商业模型Seedream3.0相当,同时相较于同类开源模型Qwen-Image略优。
混元图像2.1模型不仅采用了海量训练数据,还利用结构化、不同长度、内容多样的caption,极大提升了对文本描述的理解能力。在caption模型中,引入了OCR和IP RAG专家模型,有效增强了对复杂文字识别和世界知识的响应能力。
为大幅降低计算量、提升训练和推理效率,模型采用了32倍超高压缩倍率的VAE, 并使用dinov2对齐和repa loss来降低训练难度。因此,模型能高效原生生成2K图。
在文本编码方面,混元图像2.1配备了双文本编码器:一个MLLM模块用于进一步提升图文对齐能力,另一个ByT5模型则增强了文字生成表现力。整体架构为17B参数的单/双流DiT模型。
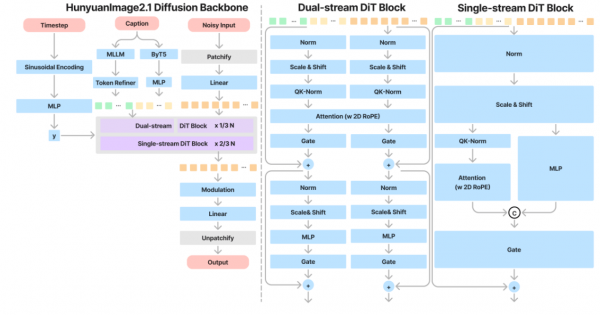
此外,混元图像2.1还在17B参数量级的模型上解决了平均流模型(meanflow)的训练稳定性问题,将模型推理步数由100步蒸馏到8 步,显著提升推理速度的同时保证了模型原有的效果。
同步开源的混元文本改写模型(PromptEnhancer)是业内首个系统化、工业级的中英文改写模型,能够对用户的文本指令进行结构化优化,丰富视觉表达,使改写后的文本生成图像的语义表现得到大幅提升。
腾讯混元在图像生成领域持续深耕,曾发布首个开源的中文原生DiT架构图像大模型——混元DiT,以及业界首个商用级实时生图模型——混元图像2.0。此次推出的原生2K模型混元图像2.1则在效果与性能之间实现了更好的平衡,能够满足用户和企业在多样化视觉场景下的多种需求。
同时,腾讯混元坚定拥抱开源,陆续开放了多种尺寸语言模型,图像、视频、3D等完整多模态生成能力和工具集插件,提供接近商业模型性能的开源基座。图像、视频衍生模型数量总数达到3000个,混元3D系列模型社区下载量超过230万,已成为全球最受欢迎的3D开源模型。
来源:至顶网软件与服务频道
好文章,需要你的鼓励


专为Mac优化的27英寸生产力显示器——MSI PRO MAX 271UPXW12G评测
MSI PRO MAX 271UPXW12G是一款专为macOS用户设计的27英寸4K QD-OLED显示器,像素密度达166 ppi,支持98W USB-C充电,兼容三路KVM切换。内置M-Color色彩同步与M-Sync亮度控制功能,无缝融入Mac工作流。支持120Hz刷新率,兼顾创意生产与游戏需求。简洁外观与多向可调支架,完美契合苹果美学。

东北大学联合佐治亚大学等机构:让机器人“快想快动“,一步到位的世界动作模型加速新方案
Flash-WAM针对机器人世界动作模型推理速度慢的问题,提出模态感知蒸馏框架,将推理压缩至单步,实现23倍加速并保持高任务成功率。

HeyPolo:Surfshark团队推出的隐私优先家庭安全位置共享应用
由知名VPN服务商Surfshark团队开发的HeyPolo,是一款以隐私保护为核心的家庭安全位置共享应用。与传统位置共享应用不同,HeyPolo采用限时共享机制,用户可自定义共享时段或一次性共享,避免全程追踪。应用支持精确位置、大致区域或隐私模式等多级共享选项,并提供SOS警报、电量提醒、驾驶行为监测等功能。所有数据加密存储,不对外出售。订阅费为每月3.99美元,支持7天免费试用。

神经网络如何“悟出“群论密码?来自耶鲁大学的研究揭开了深度学习的隐秘数学骨架
耶鲁大学研究团队证明两层神经网络在学习有限群运算时,梯度下降自发驱动每个神经元收敛到单一不可约群表示,并在傅里叶域实现秩一旋转对齐,揭示了特征学习的表示论机制。
2025
09/10
11:24
分享
点赞

HeyPolo:Surfshark团队推出的隐私优先家庭安全位置共享应用
比亚迪海豚G DM-i插混版纯电续航105公里,承诺大幅降低燃油成本
比亚迪将5分钟"闪充"电动车充电网络引入加拿大
Google TV Streamer最新更新:成为更强大的智慧家庭中枢
iOS 27 正式发布:Apple Music 迎来全面功能升级
英国政府邀请专家与行业团体为数字身份证计划提供建议
Pegasystems CTO:如何控制企业AI成本飙升问题
Apple在WWDC 2026发布四项AI新功能,值得期待
OpenAI拟租赁俄亥俄州10GW数据中心园区,Nvidia或提供资金支持
美国能源部批准Xcimer Energy聚变电站设计方案
DJI Avata 360与Avata 2对比:哪款无人机更适合你?
Swift学生挑战赛获奖者:如何向库克和特纳斯展示他们的应用
