
世界上第一块人工智能加速器四核芯片,可以提高性能,但不会提高电费
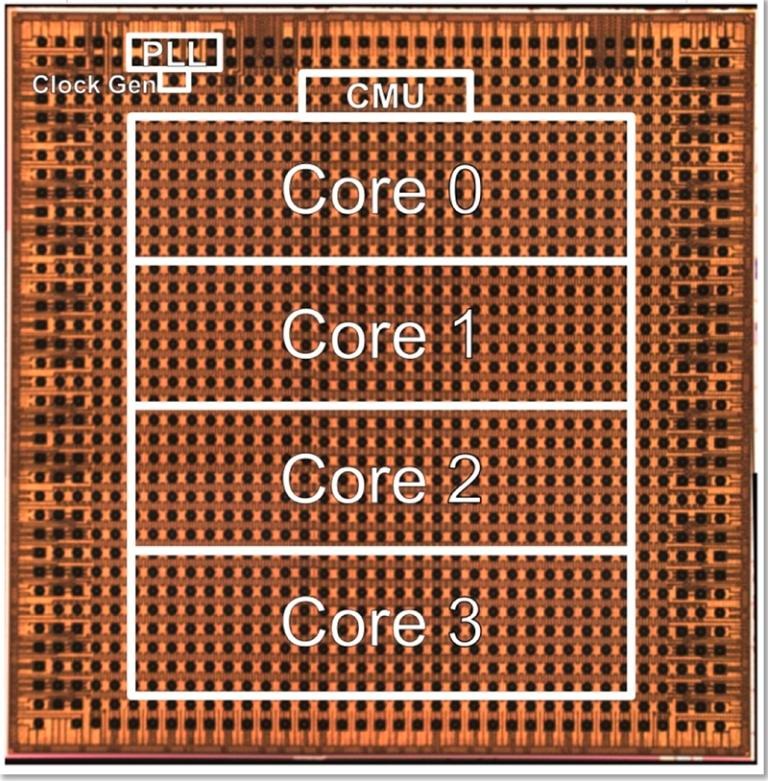
IBM的研究人员设计了他们所谓的世界上第一块人工智能加速器芯片,该芯片基于高性能7纳米技术,同时实现了高水平的能源效率。
参加此项研究的IBM研究人员Ankur Agrawal和Kailash Gopalakrishnan在互联网固态电路虚拟大会(International Solid-State Circuits Virtual Conference)推出了这款四核芯片,并且在最近的一篇博客文章中,披露了更多关于该技术的细节。尽管仍处于研究阶段,这款加速器芯片有望能够支持各种人工智能模型,并实现“领先的”电源效率。Agrawal和Gopalakrishnan表示:“这种节能的人工智能硬件加速器可以显著提高计算能力,包括在混合云环境中也是如此,而且不需要消耗大量的能量。”
人工智能加速器是一类硬件,顾名思义,这种硬件就是为了加速人工智能模型而设计的。通过提高算法的性能,这类芯片可以提升自然语言处理或者计算机视觉之类的数据密集型应用的结果。
但是,随着人工智能模型复杂程度的增加,支撑算法系统的硬件运行所需的电量也随之增加。这两位IBM的研究人员写道:“从历史上看,该领域已经接受了这样的关联:如果计算的需求量很大,那么需要的能耗也会很大。”
IBM的研究部门一直在为芯片创造新的设计,让它们能够处理复杂的算法而又不会增加碳足迹。挑战的关键在于设计出一种不需要消耗过高能量,但又不会牺牲计算能力的技术。
一种方法是在加速器芯片中采用降低精度的技术,这些技术已被证明可以帮助深度学习训练和推理,同时又只需要更少的硅面积和能耗,这意味着训练人工智能模型所需的时间和能耗可以显著降低。
IBM研究人员展示的新芯片针对低精度培训进行了高度优化。它是第一款采用被称为混合FP8格式的超低精度技术的硅芯片。FP8格式是IBM开发的一种八位训练技术,可以在图像分类、语音和对象检测等深度学习应用中保持模型精度。
此外,由于配备了集成的电源管理功能,该加速器芯片可以将自身性能最大化,例如,通过在高功耗的计算阶段降速来实现这一点。
该芯片还具有很高的利用率,实验表明训练利用率超过80%,推理利用率达到60%——据IBM的研究人员称,这一数字远远高于典型的GPU利用率(通常低于30%)。这一特性再次转化为更好的应用性能,这也是该芯片设计中提高能效的关键部分。
Agrawal和Gopalakrishnan表示,这些特性加在一起,让这款芯片不仅在能效方面“最先进”,而且在性能方面也是“最先进”的。研究人员们将该技术同其他芯片进行了比较,得出了结论:“我们芯片的性能和能效超过了其他专用的推理和训练芯片。”现在,研究人员希望这些设计可以扩大规模并进行商业部署,以支持复杂的人工智能应用。包括从语音到文本人工智能服务和金融交易欺诈检测等大规模云深度培训模型。
边缘应用也可能会找到IBM新技术的用途,自动驾驶车辆、安全摄像头和移动电话都可能会受益于功耗更低的高性能人工智能芯片。
研究人员们表示:“为了推动人工智能淘金热,我们一直在改善人工智能硬件技术的核心:支持深度学习的数字化人工智能核心,这是人工智能的关键推动因素。” 随着人工智能系统在所有行业中的广泛应用,这种承诺很难被视而不见。
好文章,需要你的鼓励


人工智能落地“最后一公里”,戴尔工作站助力AI应用提速
英特尔携手戴尔以及零克云,通过打造“工作站-AI PC-云端”的协同生态,大幅缩短AI部署流程,助力企业快速实现从想法验证到规模化落地。

意大利ISTI研究院推出Patch-ioner:一个神奇的零样本图像描述框架,让电脑像人一样描述任何图像区域
意大利ISTI研究院推出Patch-ioner零样本图像描述框架,突破传统局限实现任意区域精确描述。系统将图像拆分为小块,通过智能组合生成从单块到整图的统一描述,无需区域标注数据。创新引入轨迹描述任务,用户可用鼠标画线获得对应区域描述。在四大评测任务中全面超越现有方法,为人机交互开辟新模式。

阿联酋MBZUAI发布PAN世界模型,AI仿真技术迎来突破
阿联酋阿布扎比人工智能大学发布全新PAN世界模型,超越传统大语言模型局限。该模型具备通用性、交互性和长期一致性,能深度理解几何和物理规律,通过"物理推理"学习真实世界材料行为。PAN采用生成潜在预测架构,可模拟数千个因果一致步骤,支持分支操作模拟多种可能未来。预计12月初公开发布,有望为机器人、自动驾驶等领域提供低成本合成数据生成。

MIT团队重磅发现:不配对的多模态数据也能让AI变得更聪明
MIT研究团队发现,AI系统无需严格配对的多模态数据也能显著提升性能。他们开发的UML框架通过参数共享让AI从图像、文本、音频等不同类型数据中学习,即使这些数据间没有直接对应关系。实验显示这种方法在图像分类、音频识别等任务上都超越了单模态系统,并能自发发展出跨模态理解能力,为未来AI应用开辟了新路径。
2021
03/04
17:50
分享
点赞

人工智能落地“最后一公里”,戴尔工作站助力AI应用提速
《2025 中国企业级 AI 实践调研分析年度报告》:深度剖析与价值洞察
Gartner:在中国构建AI软件工程技能的三大举措
阿联酋MBZUAI发布PAN世界模型,AI仿真技术迎来突破
Nvidia和Google支持的AI代码编辑器Cursor获23亿美元融资
Anthropic披露首例Claude模型参与的AI网络间谍活动
Cadence首款系统芯粒架构成功流片,助力物理AI发展加速
百度发布定制AI加速器响应国产芯片需求
VasEdge试用火热招募,降本增效机遇来袭
Infinidat InfiniBox G4系列升级重塑高端企业存储格局
Avalonia为微软MAUI跨平台应用方案带来Linux和浏览器支持
谷歌DeepMind发布SIMA 2智能体:游戏世界中学习迈向AGI之路
最热门的 AI 模型:它们的功能和使用方法
这款古怪的 AI 智能手机可以创建你的数字分身
Faireez 获 750 万美元融资,为租赁市场提供 AI 驱动的酒店式管家服务
Broadcom 大获全胜:70% 大型 VMware 客户购买其最全面解决方案
Peer 获得1050万美元元宇宙引擎投资,推出3D个人星球功能
获 3000 万美元融资,Crogl 发布面向安全分析师的全新 AI "钢铁侠战衣"
Turing 获得 1.11 亿美元融资,估值达到 22 亿美元,为 OpenAI 等大语言模型公司提供关键代码支持
Tavus 推出系列 AI 模型,实现实时人脸交互技术突破
Welevel 获得 570 万美元融资,革新程序化游戏开发
AI 驱动的卓越运营:企业如何通过人人可及的流程智能提升成功
