
主打国产化 网易数帆NDH技术创新看点多 原创
外部环境的不确定性不只是公共卫生事件,还有技术管控,所谓的“科学无国界”是个伪命题。虽然这给我们带来了挑战,但是另一方面也加速了关键技术自主化、国产化。
近年来政府部门也相继出台相关政策,鼓励中国厂商进行自主创新,推动软件国产化和自主化的研发。

比如大数据领域,据信通院的统计信息显示,有超过90%的企业场景都在使用如HDP、CDH或者一些开源平台自主搭建的大数据基础平台。今年3月CDH停服后,软件后续的升级、维护更是受限。
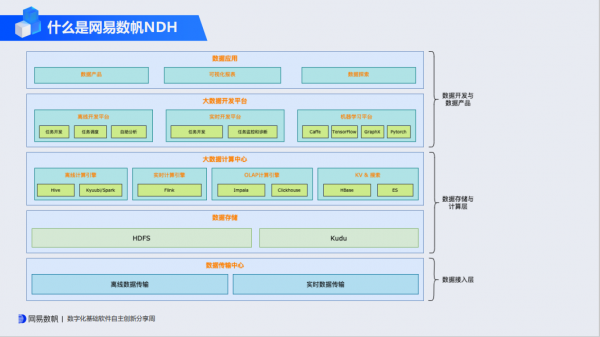
在此背景下,网易数帆正式发布有数大数据基础平台(NetEase Digital Sail Youshu Data Hub ,以下简称NDH)。网易数帆一直以来都坚持关键IT技术研发与创新,积极参与基础软件的国产化研究。
网易数帆资深大数据架构师蒋鸿翔表示,作为一个资深的大数据用户,网易2009年就开始对Hadoop投入研发。NDH就是基于网易在大数据领域十几年沉淀的经验而推出的企业级大数据基础平台。
NDH基于最新开源技术打造,内置多种存储计算引擎,并在Hadoop、Spark、Impala等多个核心组件做了功能及性能增强,可实现对整个Hadoop体系核心代码的完全自主掌握,并新增了Easyeagle实现智能运维和任务治理,支持企业级安全管控。
同时,NDH还适配了信创的软硬件生态,兼容多款主流国产化操作系统、数据库、芯片等,既支持在华为云、阿里云、腾讯云等场景下云化部署,也支持私有化部署,满足金融及政府行业的信创要求。
NDH技术创新看点多
除了上面提到的自主可控,NDH还具备平滑迁移、安全稳定、开发便利、智能运维等特点。

在切换新平台之前,企业对于迁移是否平滑,影响范围多大十分关注,毕竟迁移需要花费人力、时间等较大成本,稍有不慎,还会导致数据丢失、业务难响应等问题。
另外,迁移后上层的应用系统是否可以与替换的底层平台完美兼容,与其他国产组件是否能实现生态兼容,实现兼容后是否可以快速响应业务发展需求等也是企业关心的问题。
蒋鸿翔说,平滑迁移是在对业务不造成影响或者很小很轻微的影响下,完成整个大数据平台从老平台切换到新的平台。“网易内部部署了大量的大数据平台,成功进行过整个平台的版本升级或者跨机房的迁移,实现了对业务的无影响。”
基于网易内部多年平滑迁移方面累积的实践经验,网易数帆制定出一整套平滑迁移的落地方案,包括权限迁移、元数据/数据迁移、任务迁移等多个维度,为企业提供网易原厂的迁移服务,从而保证迁移过程基本不停服、迁移所需资源可控、迁移风险可控。
这也使得在对业务不影响或者影响时间较短(小于10min)的情况下,可以完成整体平台迁移到NDH,真正实现对业务侧不造成影响。此外,迁移完成后, NDH还将为企业提供额外收益,IT系统自动升级成存算分离架构建设,分别提升存储、计算机器的资源利用率,助力企业降本增效。
在安全性方面,NDH增强Impala,具备高可用和隔离能力:建立基于虚拟数仓的隔离环境,支持对于同一集群中的不同节点进行分组,不同workload的业务配置不同的分组,避免业务之间相互影响;增强HDFS,尽最大可能保障数据和服务安全。有数大数据基础平台NDH组件可提供增强回收站的功能,支持用户恢复数据,避免因误操作造成数据损失。
在开发便利方面,通过企业级数据湖探索平台Kyuubi ,企业可以像使用HiveServer2一样开发SparkSQL:Spark作为整个大数据计算领域最流行的计算框架,相比原先常用的Hive,在计算性能和资源利用方面有很大的提升,但大部分用户很难改变Hive模式下的使用习惯。NDH组件支持用户保留原有习惯和模式,基于Spark计算引擎上构建的SQL查询引擎,支持多租户隔离等特性,更好地实现分析计算。
在智能运维方面,系统会将任务与机器的资源进行串接,运维人员可以快速定位到任务执行过程中涉及到的硬件资源。比如,某台机器由于I/O的高利用率或者CPU的高利用率,导致任务的差异化反应。通过NDH的智能故障分析系统,运维人员可以快速从任务层面查询到背后的原因,反过来也可以从整个机器的层面,反查出机器故障影响了哪些任务的运行,让任务诊断变得快速便捷和直观。
结语
NDH一方面基于开源大数据组件,并在安全、隔离、性能等方面进行了增强,并完全支持国产信创生态,而且还提供产品售后的原厂服务,让企业后顾无忧。
作为国产大数据平台,NDH功能强大、代码自主安全可靠、迁移平滑、服务有保障,在未来自主可控的数据基础设施建设中将发挥更大的价值。
好文章,需要你的鼓励


Alice & Bob发布首款量子硬件系统,推动量子比特容错能力突破
欧洲量子计算初创公司Alice & Bob正式推出其首款完整量子硬件平台——Helium量子系统,标志着该公司从量子芯片制造商升级为完整系统开发商。该系统基于独特的"猫量子比特"架构,仅需18个猫量子比特即可实现首个逻辑量子比特的编码,并集成了处理器架构、控制电子设备及监控软件Starboard。系统功耗仅40千瓦,支持量子与经典计算资源的协同部署,面向高性能计算场景开放研究合作。

延世大学与英伟达联手:视频AI的物理幻觉,原来是被“过度加工“害的
本研究发现AI视频生成中物理幻觉的根源是去噪过程中的相位侵蚀,并提出免训练方法PhaseLock,用两步推理的运动先验引导完整生成,物理一致性平均提升6.2分。

Intuit首席AI官谈SaaS行业变革与企业AI实践
Intuit首席AI官Ashok Srivastava对外界盛传的"AI颠覆SaaS"论调保持冷静,认为SaaS行业的演变本是持续循环的一部分。他表示,公司通过引入AI智能体,过去一年开发速度提升40%,五年内开发效率提升12倍。QuickBooks Live订阅量因AI加入翻倍增长,QuickBooks Capital平台同比增长73%。Srivastava同时强调,Intuit拒绝"Token最大化"策略,坚持以服务客户为核心,在合规监管环境下稳步推进AI落地。

和弦符号能告诉AI音乐“是什么风格“吗?PearlLeeStudio用11种音乐流派测出了答案
本研究测试了5种AI适配方法在11种音乐风格和弦预测上的表现,发现和弦符号确能携带风格信息但不完整,控制词条与完整适配器效果相当。
2022
06/23
17:49
分享
点赞

Intuit首席AI官谈SaaS行业变革与企业AI实践
苹果3D处理技术令人惊叹,未来潜力更值得期待
微软与印度初创公司Alt Carbon签署碳移除协议,印度市场地位持续提升
DoorDash推出AI聊天机器人,支持文字与图片点餐
Meta与RWE签署298兆瓦德克萨斯州太阳能项目长期购电协议
Cypress Creek完成35亿美元融资,推进阿肯色州大型太阳能储能项目
谷歌Pixel手机系统更新引发启动循环故障,修复方案已初步明朗
Oppo Find N7曝光:7.6英寸宽屏折叠旗舰,折痕或将大幅改善
触屏MacBook即将到来,供应链消息人士100%确认
macOS 26 Tahoe菜单图标设计翻车,苹果用32年前的准则纠错
iOS 27 对 Journal 应用带来了哪些更新?
三星P9 Express microSD卡降价40%,为Switch 2存储翻倍的好时机
