
IBM人工智能超级计算机 Vela 扩容一倍
IBM 研究部门 IBM Research将旗下人工智能超级计算机 Vela (IBM云的一部分)的容量增加了一倍,以应对 watsonx 模型的强劲增长,IBM Research还制定了积极的计划,利用自家研发的加速器 IBM AIU 继续扩展和增强人工智能推理能力。
IBM研究院一年前宣布建立用于训练基于英伟达A100 GPU的人工智能基础模型的大型云基础设施,名为Vela。IBM 客户正在迅速采用人工智能技术,目前已有数百个开发项目正在使用 IBM watsonx。IBM 在去年的一次分析师活动上分享了一些令人印象深刻的成功案例,并正在吸引更多的人工智能项目加入他们的管道。IBM 首席执行Arvind Krishna在最近的财报电话会议上表示,watsonx 的管道规模自上一季度以来大约翻了一番。
IBM Research 日前完成了 Vela 的第一阶段升级,并且计划继续进行升级,以满足业界对训练更大规模基础模型的需求。IBM Research 提供了有关细节,为其他希望在控制成本的同时升级人工智能基础架构的公司提供了宝贵的经验。
新的 Vela
最初的 Vela 配备了总数不详的 GPU 和英特尔至强 CPU,都是通过标准的 2x100G 以太网 NICS 互连。IBM Research 放弃了性能更好、成本更高的 Infiniband,以更低的资本成本展示了接近裸金属的性能,同时实现了 Kubernetes 的云标准容器支持。
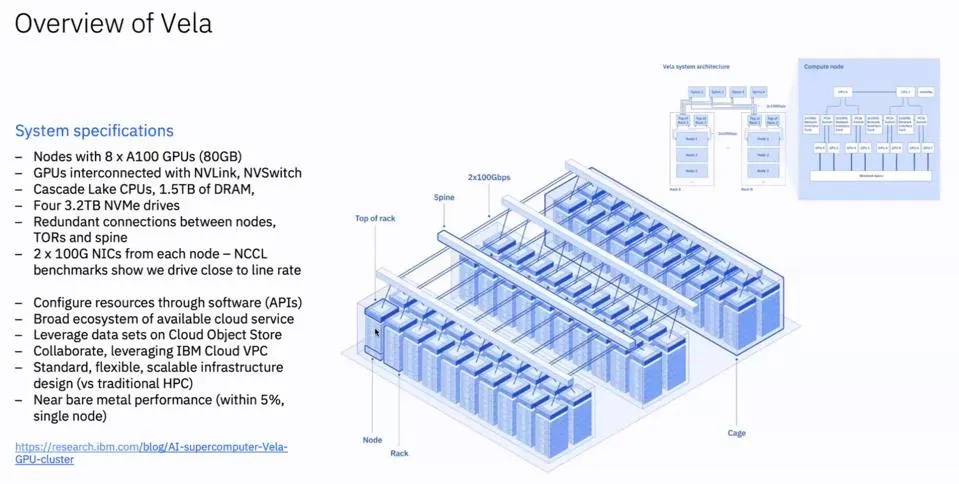
人工智能超级计算机Vela,专门用于基础模型研究和客户端模型开发(图:IBM)
为了处理不断增加的负载,IBM 的研究人员面临的选择是:用更多的 Nvidia A100 GPU 升级 Vela或全部换成速度更快的 H100。IBM 的研究人员意识到,如果实施功率封顶策略,就可以在相同的可用功率范围内将每个机架的 GPU 数量增加一倍,进而可以提高 GPU 的密度。
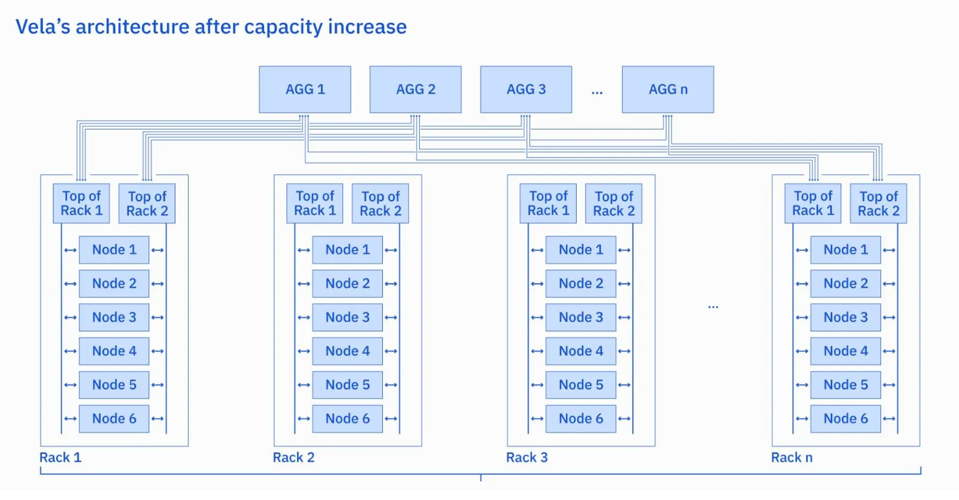
新的 Vela 云每个机架有 6 x 8 个 GPU 节点(图:IBM)
IBM 研究人员确定了要将 GPU 数量翻倍的计划后,就需要在不拆除网卡和交换机的情况下解决网络带宽问题。为此,他们部署了以太网 RDMA 和英伟达 GPU-Direct RDMA(GDR),将 GPU与GPU之间的带宽提高了 2 到 4 倍,延迟则降低了 6到10 倍。

IBM 还通过使用 RoCE 和 GDR 实施 RDMA,提高了 GPU-GPU 网络性能(图:IBM)
IBM 研究人员指出,“人工智能服务器的故障率高于许多传统云系统。而且,人工智能服务器发生故障的方式会让人意想不到(有时甚至难以检测)。此外,当节点(甚至单个 GPU)出现故障或性能下降时,可能会影响到在数百或数千个节点上运行的整个训练任务的性能。”IBM 研究团队成功提高了故障诊断能力,并将发现和解决问题的时间缩短了一半。
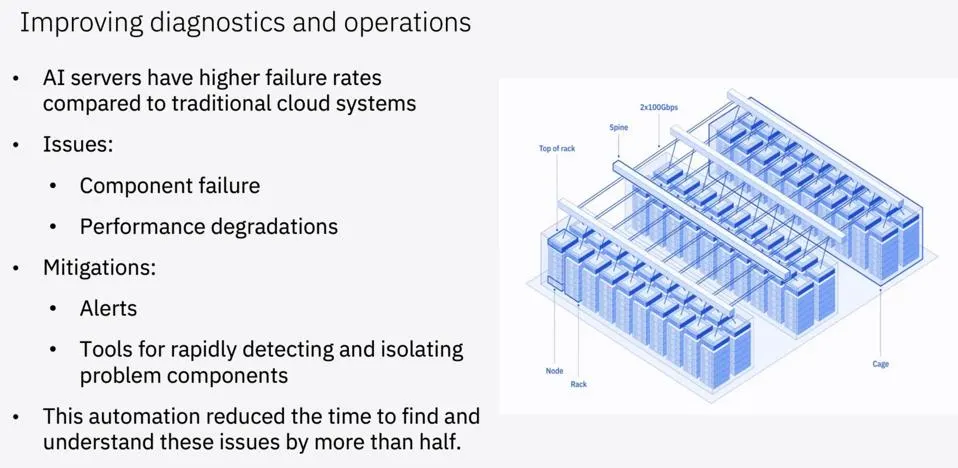
处理大型云故障的时间缩短一半(图:IBM)
下一步是什么?
IBM制定了计划应对Vela需求的不断增加。我们预计Vela的下一次重大升级将添加 H100 GPU甚至下一代 GPU(B100)。IBM Research还希望提供更具成本效益的推理处理基础设施,例如其自家研发的原型的“AIU”推理加速器原型。早期测试结果显示,AIU原型只需 40 瓦就能运行推理,其吞吐量与 A100 GPU 在该功率下的吞吐量相同。IBM 已在约克镇设施中部署了约 150 个 AIU并计划在技术成熟后将 AIU 的容量增加到 750 个以上。
结论
IBM 在各方面利用人工智能焕发活力,内部的人力资源咨询(Ask HR)和其他应用都用上了人工智能进行,IBM Z 的代码现代化也用了人工智能,IBM还利用人工智能为客户定制开发自己的基础模型。所有这些都帮助 IBM 积累了新的技能和专业知识,IBM并将其应用于客户咨询项目,取得了良好的效果。IBM 在大规模部署 AIU后将可能比其他云提供商更具竞争优势,原因是其他云提供商使用的推理技术更为昂贵,效率却不尽如人意。
如果三年前有人告诉我 IBM 将成为人工智能领域的主要参与者,我肯定不会相信。但到现在基于 IBM 在 watsonx 业务上取得的进展以及人工智能超级计算机Vela的相应增长,IBM 显然拥有正确的计划和技术,可以继续大幅增长旗下的人工智能业务。
好文章,需要你的鼓励


人工智能落地“最后一公里”,戴尔工作站助力AI应用提速
英特尔携手戴尔以及零克云,通过打造“工作站-AI PC-云端”的协同生态,大幅缩短AI部署流程,助力企业快速实现从想法验证到规模化落地。

意大利ISTI研究院推出Patch-ioner:一个神奇的零样本图像描述框架,让电脑像人一样描述任何图像区域
意大利ISTI研究院推出Patch-ioner零样本图像描述框架,突破传统局限实现任意区域精确描述。系统将图像拆分为小块,通过智能组合生成从单块到整图的统一描述,无需区域标注数据。创新引入轨迹描述任务,用户可用鼠标画线获得对应区域描述。在四大评测任务中全面超越现有方法,为人机交互开辟新模式。

阿联酋MBZUAI发布PAN世界模型,AI仿真技术迎来突破
阿联酋阿布扎比人工智能大学发布全新PAN世界模型,超越传统大语言模型局限。该模型具备通用性、交互性和长期一致性,能深度理解几何和物理规律,通过"物理推理"学习真实世界材料行为。PAN采用生成潜在预测架构,可模拟数千个因果一致步骤,支持分支操作模拟多种可能未来。预计12月初公开发布,有望为机器人、自动驾驶等领域提供低成本合成数据生成。

MIT团队重磅发现:不配对的多模态数据也能让AI变得更聪明
MIT研究团队发现,AI系统无需严格配对的多模态数据也能显著提升性能。他们开发的UML框架通过参数共享让AI从图像、文本、音频等不同类型数据中学习,即使这些数据间没有直接对应关系。实验显示这种方法在图像分类、音频识别等任务上都超越了单模态系统,并能自发发展出跨模态理解能力,为未来AI应用开辟了新路径。
2024
02/04
15:57
分享
点赞

《2025 中国企业级 AI 实践调研分析年度报告》:深度剖析与价值洞察
Gartner:在中国构建AI软件工程技能的三大举措
阿联酋MBZUAI发布PAN世界模型,AI仿真技术迎来突破
Nvidia和Google支持的AI代码编辑器Cursor获23亿美元融资
Anthropic披露首例Claude模型参与的AI网络间谍活动
Cadence首款系统芯粒架构成功流片,助力物理AI发展加速
百度发布定制AI加速器响应国产芯片需求
VasEdge试用火热招募,降本增效机遇来袭
Infinidat InfiniBox G4系列升级重塑高端企业存储格局
Avalonia为微软MAUI跨平台应用方案带来Linux和浏览器支持
谷歌DeepMind发布SIMA 2智能体:游戏世界中学习迈向AGI之路
Infinidat G4系列升级重新定义高端企业存储格局
最热门的 AI 模型:它们的功能和使用方法
这款古怪的 AI 智能手机可以创建你的数字分身
Faireez 获 750 万美元融资,为租赁市场提供 AI 驱动的酒店式管家服务
Broadcom 大获全胜:70% 大型 VMware 客户购买其最全面解决方案
Peer 获得1050万美元元宇宙引擎投资,推出3D个人星球功能
获 3000 万美元融资,Crogl 发布面向安全分析师的全新 AI "钢铁侠战衣"
Turing 获得 1.11 亿美元融资,估值达到 22 亿美元,为 OpenAI 等大语言模型公司提供关键代码支持
Tavus 推出系列 AI 模型,实现实时人脸交互技术突破
Welevel 获得 570 万美元融资,革新程序化游戏开发
AI 驱动的卓越运营:企业如何通过人人可及的流程智能提升成功
