
OpenStack实例正确设置九大技巧
在OpenStack的术语中,一个实例就是一台虚拟机,即客机工作负载。它从操作系统镜像中启动,并且配置有特定数量的CPU、RAM和磁盘空间,以及其他参数,例如网络或安全设置。
在红帽资深顾问Marko Myllynen撰写的这篇博文中,我们将探索九个OpenStack配置和优化选项,帮助您的工作负载实现所要求的性能、可靠性和安全性。
无论OpenStack云管理员在您的云环境中启用了什么功能,某些优化可在客机内进行。然而,更先进的选项要求提前启用,而且可能需要特殊的主机能力。这意味着本文介绍的许多选项取决于管理员如何配置云环境,或者可能在某些租户中不可用,因为这些选项是为某些用户组预留的。关于本主题的更多信息可见红帽文档门户和红帽OpenStack镜像服务综合指南。同时,上游OpenStack文档也提供了一些额外指导准则。
对于在任何OpenStack环境中运行的任何虚拟机,需要对以下配置进行评估。这些变更没有负面影响,而且即使未使用,一般也可以安全地启用。
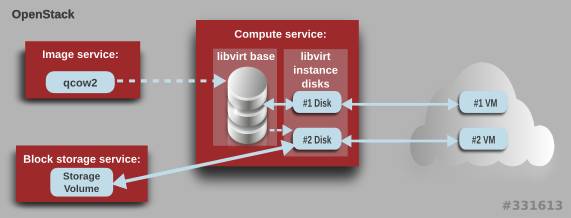
01、镜像格式:QCOW还是RAW?
OpenStack存储配置是云管理员的一个实施选项,而租户通常无法完整看到。存储配置也可能随着时间推移而变化,而无需管理员明确通知,因为他/她通过不同的规范而在配置中增加了容量。
在OpenStack上创建新实例时,该实例基于Glance镜像。两种最常见并且推荐使用的镜像格式是QCOW2和RAW。QCOW2镜像(来自 QEMU Copy On Write)的体积更小。以拥有一块100 GB磁盘的服务器为例,RAW格式的镜像如果格式化为QCOW2格式,其大小可能仅10 GB。无论哪种格式,在通过 virt-sysprep(1)和virt-sparsify(1)将镜像上传到Glance之前都需要进行处理。
QCOW2的性能取决于系统管理程序内核和格式版本,最新版本为QCOW2v3(有时称为QCOW3),比先前的QCOW2性能更优秀,与RAW格式基本相同。总体来讲,我们假设RAW的整体性能更好,尽管在运行方面存在缺陷(例如缺乏快照),或者上传或引导时间增加(由于体积更大)。最新的红帽OpenStack Platform版本自动采用更新的QCOW2v3格式(得益于最近的RHEL版本),而且该版本可以检查并且利用 qemu-img(1)在RAW和更老/更新的QCOW2镜像间进行转换。
OpenStack实例可以从本地镜像或者远程卷中引导。这意味着:
-
镜像支持的实例通过旧QCOW2与QCOW2v3和RAW间的性能差异而显著获益。
-
卷支持的实例可以从QCOW2或RAW Glance镜像中创建。然而,由于Cinder后端视特定供应商而不同(Ceph、3PAR、EMC等),它们可能不采用QCOW2或RAW。可能有自己的机制,例如重复数据删除、精简配置或者边写入边复制。需要特别注意的是,这并不支持在配有Ceph的Glance中使用QCOW2。
根据一般经验,极少使用的镜像应以QCOW2格式存储在Glance中,但对于经常用于创建新事例(在本地存储)的镜像,或者用于创建卷支持的事例的镜像,使用RAW能够提供更好的性能,尽管有时初始引导时间更长(Ceph支持的系统除外,原因是它采用了边写入边复制的方法)。最后,任何实际的建议都依赖于云管理员所选择的OpenStack存储配置。
02、通过镜像额外属性进行性能调整
从Mitaka版本起,OpenStack允许Nova自动优化计算主机上的某些libvirt和KVM属性,目的是更好地执行客机中的特定OS。要向Nova提供客机OS信息,只需定义以下Glance镜像属性:
-
os_type=linux # 通用名称,例如linux或windows
-
os_distro=rhel7.1 # 使用osinfo-query os列出支持的变体
此外,至少在目前,为了保证使用更新和更具扩展能力的virtio-scsi超虚拟化SCSI控制器取代旧的virt-blk,需要明确设置以下属性:
-
hw_scsi_model=virtio-scsi
-
hw_disk_bus=scsi
支持的所有镜像属性在红帽文档门户和其他CLI选项中列出。

03、为Cloud-init做好准备
“Cloud-init” 是用于云实例早期初始化的程序包,用于配置基本信息,例如分区/文件系统大小和SSH密钥。
您要保证已经在Glance镜像中安装了cloud-init和cloud-utils-growpart程序包,而且相关服务将在引导时执行,以允许执行针对OpenStack VM的 “cloud-init” 配置。
许多情况下可以接受默认配置,但也有许多定制选项可以使用。
04、启用QEMU客机代理
在Linux主机上,建议安装并启用QEMU客机代理,以允许正常关机和(将来)需要快照时客机文件系统的自动冻结,这是一致备份的必要操作:
-
yum install qemu-guest-agent
-
systemctl enable qemu-guest-agent
为了提供必需的虚拟设备,并且在需要时使用文件系统冻结功能,需要为Glance镜像定义以下属性:
-
hw_qemu_guest_agent=yes # 创建所需的设备,以允许客机代理运行
-
os_require_quiesce=yes # 接受文件系统冻结/解冻请求
05、从客机故障状态恢复
全面的实例故障恢复、高可用性和服务监控需要采用分层的方法。在下文中,我们列出了仅可用于客机内的选项(可视为最内层)。最常用的实例故障恢复机制有:
-
从内核瘫痪状态恢复
-
从客机挂起状态恢复(不一定涉及到内核瘫痪/错误)
在极少发生的客机内核瘫痪的情况下,kexec/kdump将捕获内核vmcore,用于提供进一步分析和客机重新引导。如果不需要vmcore,通过设置错误内核参数,例如“panic=1”,内核可以在瘫痪后按照指令重新引导。
为了在发生其他意外行为后对实例进行重新引导,例如某个阈值的高负荷,或者在没有内核错误时的整个系统锁定,可以使用watchdog服务。以下属性需要对Glance镜像或Nova Flavor而定义。
-
hw_watchdog_action=reset
然后,在客机内安装与配置watchdog程序包,最后启用该服务:
-
yum install watchdog
-
vi /etc/watchdog.conf
-
systemctl enable watchdog
根据默认设置,watchdog检测到内核瘫痪和整个系统锁定。例如,如何在watchdog功能检查过程中添加健康监控脚本。
06、调试内核
调试Linux代码的最简单方式是使用 “tuned” 工具。这种服务可根据所选的档案配置几十个系统参数,对于OpenStack,它是“虚拟客机”。对于NFV工作负载,红帽提供了一组NFV调试档案,用于简化网络密集型虚拟机的调试。
在您的Glance镜像中,建议安装所要求的程序包,在引导时启用服务,然后激活首选的档案。您可以在将镜像上传到Glance之前编辑镜像,也可以作为cloud-init配置的一部分:
-
yum install tuned
-
systemctl enable tuned
-
tuned-adm profile virtual-guest
07、通过VirtIO多队列增强网络能力
客机内核virtio驱动程序是标准RHEL/Linux内核程序包的一部分,并且自动启用,而不需要根据需要进一步配置。对于特定的Windows版本,Windows客机也应使用官方virtio驱动程序,用于显著提高网络和磁盘IO性能。
然而,在Linux内核和用户空间组件中网络程序包处理方面,最新的发展提供了大量用于调试或绕开virtio驱动程序的额外选项。下文列出了一种virtio设备模型。
网络多队列(或者叫virtio-net多队列)方法实现了并行数据包处理,这样能够随着客机可用vCPU数量而线性扩展,从而实现传输速度的显著提高,特别是对于vhost-user。
由于OpenStack Admin配置了带有支持组件的虚拟化主机(至少OVS 2.5 / DPDK 2.2),这一功能可由OpenStack Tenant通过需要网络多队列的这些Glance镜像中的以下属性启用:
-
hw_vif_multiqueue_enabled=true
在从该镜像完成初始化的客机中,可通过以下命令检查并更改NIC通道设置:
-
ethtool -l eth0 #用于查看当前队列的数量
-
ethtool -L eth0 combined <nr-of-queues> # 用于设置队列的数量。应与vCPU数量相符。
另外有一个开放RFE,用于实施多队列激活,这是内核中的默认功能。

08、客机的其他杂项调试
毫无疑问,规模适当的实例仅包含最少的程序包,并且仅运行所需的服务。特别需要注意的是,安装并启用irqbalance服务可能是一种很好的做法,尽管这并非在所有情况下都绝对有必要,但该服务的开销最低,并且应该在SR-IOV设置中使用。
即使在KVM上采用隐性设置,明确添加内核参数no_timer_check是一种很好的做法,这可以避免定时设备出现问题。分别使用PERSISTENT_DHCLIENT=yes和NOZEROCONF=yes启用永久DHCP客户端,并禁用网络配置中的zeroconf路径有助于避免网络极端状况的问题。
根据默认设置,客机MTU设置一般都能够正确地调整,但在堆栈的所有级别使用正确的MTU对于实现最高网络性能至关重要。在配有10G(以及更快)NIC的环境中,这一般意味着要使用MTU高达9000的Jumbo Frames,同时考虑可能的VXLAN封装。
09、改善您接入实例的方式
尽管某些纯粹主义者可能考虑在纯云原生实例中以不兼容的方式运行SSH,尤其是在自动扩展的生产工作负载中,但我们绝大多数人仍然依赖优秀的旧有SSH来执行配置任务(例如通过Ansible)以及维护和故障排除(例如,在软件故障后提取日志)。
SSH daemon应避免DNS查询,目的是加快建立SSH连接。对于这一要求,考虑在/etc/ssh/sshd_config 中采用UseDNS no,并向/etc/sysconfig/sshd增加OPTIONS=-u0。如果未使用Kerberos,可以考虑设置GSSAPIAuthentication no。如果实例频繁地互相连接,也可以考虑ControlPersist / ControlMaster选项。
一般来说,远程SSH接入和采用Horizon通过控制台接入对于大多数情况已经足够。在开发阶段,从Nova计算主机直接通过控制台接入也可能很有帮助,要做到这一点,需启用serial-getty@ttyS1.service,允许根据需要通过向 /etc/securetty添加ttyS1 而通过ttyS1进行根接入,然后利用virsh console <instance-id> –devname serial1从Nova计算主机接入客机控制台。
我们希望您通过本篇博文发现增强OpenStack实例性能的新方式。如果需要更多信息,不要忘了红帽在OpenStack文档门户中提供了大量文档,而且红帽提供了业内最优秀的OpenStack课程,您可以从免费的CL010:OpenStack介绍课程开始学习。
来源:业界供稿
好文章,需要你的鼓励



明尼苏达大学最新研究颠覆认知:训练AI大模型,只需动其中一层就够了?
这项来自明尼苏达大学等机构的研究发现,大语言模型在强化学习后训练中,只需训练中间少数几层即可匹配甚至超越全参数训练效果,且这一规律跨模型、跨任务高度稳定,为更高效的AI训练策略提供了新思路。


台湾大学与NVIDIA揭秘:你的声音正在悄悄改变AI对你的判断
本文介绍VIBE框架,一套通过开放式任务评估大型音频语言模型声音诱发偏见的系统,测试12个模型后发现每个模型均存在显著性别或口音偏见。
2017
08/31
12:04
分享
点赞

机器人管家系统上线!傅利叶携多款康养陪伴新品方案亮相WAIC 2026
赛那德“ 自主作业机器人天团” 登陆 WAIC:iLoabot-X+模型双升级,秀出具身场景落地硬实力
西门子Eigen工程智能体中国首发首展,荣获2026 WAIC SAIL之星奖
NVIDIA Cosmos 推动物理 AI 前沿发展
PPIO亮相WAIC 2026:发布智能模型网关,打造面向Agent时代的智能Token工厂
端侧感知、私有闭环、量子协同, NVIDIA全栈异构计算范式“接管”实体产业底座
边缘智算筑基、全栈软硬协同,研华科技将AI带进产业闭环
千问AI眼镜将升级为智能体眼镜:能灵活调用Skill和Agent,能全天候感知
对话Moonix郭于晨:先让用户戴上“眼镜”,再让“AI”记录世界
亮相WAIC 2026,临床实证赋能康养升级 无芯科技定义AI疗愈新范式
生态覆盖持续扩散,一文看懂各行业企业鸿蒙化转型进度
WAIC亮出集群协作真功夫,优艾智合领跑工业具身智能规模化
麻省理工学院新系统GIFT:让AI将2D设计高效转化为3D模型
AI时代的平台,红帽给出“选择权”
从Linux到Kubernetes再到AI:红帽始终站在每一次技术重构的中心
新版红帽企业Linux来了,赋能后量子就绪能力与AI驱动的自动化
红帽AI 3.4发布:重大升级打通开发运维协作链路,赋能智能体未来
从SDV到AIDV,汽车行业为什么需要全球化底座
操作系统重构:AI与容器化时代,IT运维团队如何实现体系化升级?
红帽推出红帽AI Enterprise,打造从底层硬件到智能体的一体化AI平台
红帽和NVIDIA AI工厂发布,助力加速可扩展生产级AI落地
红帽深化与NVIDIA的合作,将企业级开源与机架级AI深度结合,加速实现可投入生产的创新
