
Oracle第二季度云业务表现抢眼 SaaS势头强劲 原创
Oracle第二财季业绩表现抢眼,业绩和营收均高于预期,云业务也超出预期。该公司公布第二季度净收入为22亿美元,折合每股收益52美分,营收96亿美元,同比增长6%。本季度非GAAP收益为每股70美分。

华尔街预计第二季度每股收益68美分,营收95.7亿美元。在财报出炉之前,分析师们正在密切关注云预订。去年11月7日通过的对NetSuite的收购已经满了一周年,这使得软件即服务(SaaS)在未来几个季度的增长更加困难。
JMP Securities的分析师Patrick Walravens表示,投资者期望云预订增长超过40%,收入增长在40%至45%之间。分析师也对数据点感兴趣,这些数据显示,Oracle正在与亚马逊网络服务(AWS)、谷歌和微软在基础设施即服务方面展开有效竞争。
甲骨文的云业务总收入为15亿美元,比去年同期增长了44%。其中,11亿美元的销售额来自软件即服务,平台和基础设施即服务为3.96亿美元,同比增长21%。
本季度云和本地软件收入为78亿美元。
Oracle表示,其云业务正在“形成良好的势头”,首席执行官Safra Catz预计该业务表现良好。联合首席执行官Mark Hurd也表示,Fusion ERP和Fusion HCM SaaS套件的销售额在本季度上涨了65%。在与分析师的电话会议上,Hurd还强调了数据库市场份额。
与此同时,Hurd表示,Oracle正在保持其数据库的份额,并在竞争中发起了一些进攻。Hurd表示:
让我告诉你谁没有离开Oracle。你听说过的一家公司在上个季度又给了我们5000万美元。这家公司就是亚马逊。他们并没有离开Oracle。Salesforce并没有离开Oracle。我们的那些不怎么喜欢我们(他们也没有理由喜欢我们)的竞争对手继续投资,并且在Oracle上运行他们的整个业务。我不知道有谁离开Oracle了。也许Mark知道,也许Safra知道。但是亚马逊——你会认为亚马逊真的想要离开。让我告诉你另一家没有离开Oracle的公司:SAP。他们有一个名为HANA的数据库。他们想要迁移SuccessFactors。他们一直试图从Oracle离开有五六年了。所有SAP的大客户都运行在Oracle上。亚马逊继续购买Oracle的技术来运营他们的业务。Salesforce则完全运行在Oracle上。来吧,你来告诉我还有谁想要离开Oracle。
展望未来,Oracle和专注于该公司的分析师预计,在甲骨文全球大会(Oracle OpenWorld)上描述的自主数据库将推动这家公司的发展。
在Oracle的自主数据库方面,首席技术官Larry Ellison表示,它将在1月份发布。他说:
我们预计这项新技术将极大地推动PaaS和SaaS业务的增长,并保持我们的数据库授权业务保持强劲。人们正在购买数据库授权以在本地和云端运行。你可以在各种环境选择中运行它们,无论是在本地还是在云端。
至于前景,Catz表示第三季度收入增长将在2%至4%之间,按恒定货币计算,非GAAP每股收益为68美分至70美分之间。考虑货币波动,Oracle预计每股收益为71美分至73美分,符合华尔街的预期。
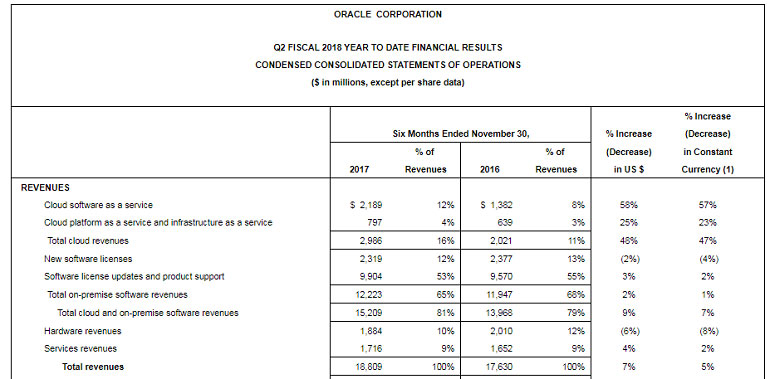
Catz表示,第三季度的云业务总收入预计将增长21%至25%。
好文章,需要你的鼓励


GLM-5.2海外爆火,我们翻了1500条评论,看看用户在讨论什么
跑分只是基准,情绪才是真相。我们整理了 1500 条海外开发者对 GLM-5.2 的评价,发现这个号称能“平替顶级闭源模型”的开源巨兽,最大的争议点竟然是“硬件成本”。当部署一个模型需要“一套房”时,你还愿意本地化吗?

清华大学研究出一套“智能剪辑师“,让AI既能答题又能完成复杂任务
清华大学提出VG-GUI-Bench评测视频引导操作能力,并设计TASKER关键帧搜索算法,在视频问答和GUI智能体任务上均实现性能与效率的双重提升。

电动自行车的功过之辩:被忽视的那一面
电动自行车频繁出现在负面新闻中——危险骑行、电池火灾、立法管制。这些问题确实存在,需要通过教育、执法和安全标准加以解决。但更大的图景常被忽视:数百万人因此骑车通勤、重拾运动、减少开车,带来健康、减排和出行独立性等多重效益。研究也表明,电动自行车骑行具有显著心肺锻炼价值。正如汽车不能只以醉驾定义,电动自行车也不应仅凭最坏案例被评判。

华科大与阿里通义联手:让AI图像生成更“聪明“地分配算力,关键细节不再被噪声埋没
SharpMoE是华科大与阿里通义联合提出的扩散模型MoE后训练框架,通过引入干净潜变量指导路由,解决噪声导致的算力分配失准问题。
2017
12/15
14:58
分享
点赞

电动自行车的功过之辩:被忽视的那一面
Neo:印度科技大亨自掏3000万美元,打造微软Office的AI替代品
AI数据中心如何获得电网接入资格?公用事业公司的规划逻辑解析
Brookfield与Bloom能源将融资规模扩至250亿美元,押注AI数据中心独立供电
当CIO的技术提案遭到否决,该如何应对?
这款谷歌实验室 AI 应用如何成为我每日必用的工具
起亚EV5推出Storm特别版并新增全轮驱动选项
Meta效仿SpaceX,将过剩AI算力变现
Gemini Spark智能体登陆Mac,新增多项功能升级
Venice AI完成6500万美元A轮融资,估值达10亿美元
Anthropic Claude模型解除出口限制,全球发布重启
自动驾驶热潮卷土重来,Humble Robotics剑指货运领域
Bending Spoons上市首日股价飙升40%,逆势突围SaaS寒冬
Gusto年收入突破10亿美元,IPO之路渐行渐近
紫光股份发布2025年报:规模再创新高,利润节节攀升,AI红利持续释放
紫光股份发布 2025年三季报:做强“算力×联接” 成就强劲高增长
Gravitee 平台助力企业管理 API 获得 6000 万美元融资
保险科技 Bestow 获高盛及 Smith Point Capital 投资 1.2 亿美元 D 轮融资
微软将允许合作伙伴自主设计按需付费的 SaaS 计划
现行 SaaS 交付模式:风险管理噩梦,CISO 评价
生成式AI×CRM,纷享销客的SaaS下半场新打法
英特尔至强助力:数据中心和人工智能事业部营收同比增长8%
