
微软2018财年第二季度财报出炉:现金和Cortana状况如何?
至顶网软件频道消息:对于我们记者来说,财报电话会议通常都是令人沮丧的,因为不允许我们向企业高管提出问题。我们——好吧,也许只是我自己——每个季度在看网络广播的财报会议时,都会对着电脑大喊大叫,我们希望分析师们能询问一些关于产品和战略的问题,但是他们从来都不让我们如意。
微软2018财年第二季度财报电话会议于1月31日召开,情况略微有点糟糕。在会议最后的问答环节,分析师们询问了Cortana的未来,并且问到了微软打算利用新税法进行大并购的传闻。
分析人士也询问了商业企业预订的低迷状况,但是他们并没有问及商业云环比增长率乏力的问题,这是我在ZDNet的同事Larry Dignan在查看昨天的数据时注意到的。
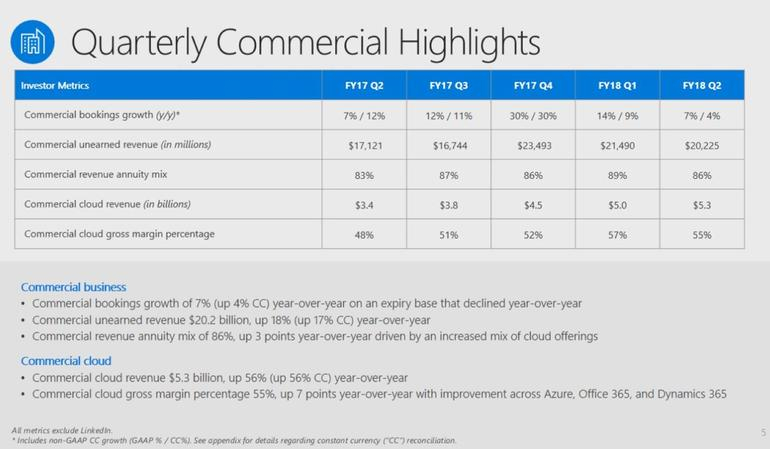
微软不再用年化运营收入来谈论“商业云”;该公司现在为这个业务类别提供了实际的季度数字和毛利率百分比。在第二季度,商业云收入为53亿美元,高于2018财年第一季度的50亿美元,毛利率达到了55%,低于2018财年第一季度的57%。
总体而言,微软第二季度非GAAP收益为75亿美元,折合每股96美分,营收收入为289亿美元,同比增长12%。由于税收方面的调整导致了138亿美元的支出,所以季度业绩状况为每股净亏损82美分。
在昨天的财报电话会议上,没有人问到微软的Surface业务,尽管该业务去年推出了三款新产品(Surface Laptop、Surface Pro和Surface Book 2),但是同比只增长了一个百分点。
首席财务官艾米.胡德(Amy Hood)也许想要谈论一下这个问题,她主动指出:“随着新的Surface Pro、Book和Laptop,Surface的不断推出,Surface业务从同比看应该是在增长的,但是由于节日的季节性因素,出现了环比下降。”
在Cortana和家庭自动化方面,微软首席执行官萨提亚.纳德拉(Satya Nadella)表示,微软认为在这个领域的投资不仅仅是一个音箱里的智能代理。
纳德拉(Nadella)表示:“现在大多数助理在进行单回合对话方面还相当愚蠢,但我们要做的是多回合对话,这需要对自然语言的真正理解。”
他重申,微软在这个领域人工智能的重点是在Azure上运行的认知服务(Cognitive Services),Cortana的角色将是“作为微软的代理,具有一些特殊的技能,尤其是在工作和生活之间交叉的地方。”
一些人非常好奇微软对Cortana和Alexa说好要进行的整合保持沉默是否意味着微软和亚马逊在去年宣布的这笔交易已经告吹,看起来对这个疑问的答案是否定的。纳德拉(Nadella)表示微软正在同Alexa合作,并且重申微软正在努力让Alexa出现在Windows设备上——这是一件好事,因为很多原始设备制造商(OEM)已经达成共识,由亚马逊开发的、针对PC的Alexa应用程序应该很快就会出现。
至于分析师们问到的可能存在的“大宗战略交易”(EA/Valve/PUBG、咳咳、咳咳),胡德(Hood)表示微软在过去没有等待税改就进行了重大的收购。
她补充表示:“我当然很高兴,能够更容易地获取现金,而不用通过债务市场才能够做出这些选择。无论是否投资于我们自身,你看到的这个季度的收入是增长了,无论像LinkedIn这样的收购的表现是否好过我们的预期。”
一些人对于微软可能会成为一个大型的游戏工作室的说法嗤之以鼻,对于这些人来说,纳德拉(Nadella)在昨天电话会议上的一句评论值得被记住:“游戏也是Azure增长的领域。换句话说,我们过去的服务现在已经增长了,我们打算加强Azure上的这些服务,以吸引更多的游戏开发商。”
对于微软来说,这一切又都回到了云上。
来源:ZDNet
好文章,需要你的鼓励



牛津大学让AI学会“物理直觉“:一个无需看视频就能预测物体运动的神经网络
牛津大学提出PHYSIFORMER,一种扩散变换器模型,通过三维网格顶点轨迹直接在世界坐标空间预测刚性与弹性物体的物理运动,一次性生成全序列轨迹,超越自回归基线。

美国多源电子患者数据采集方法研究综述
随着医疗数据数字化与互操作性的进步,跨机构纵向患者数据的研究应用成为可能。本研究通过对20位领域专家的访谈,识别出8种数据收集方法,涵盖智能手机应用、结构化数据导出、区域/全国研究查询及聚合数据源等。研究发现,各方法均有其优缺点,无单一最优方案。参与者中介交换方式可绕过复杂治理安排,但存在数据缺口;全国性网络尚不支持研究查询。公共政策的持续推进将对该领域发展起关键作用。

奖励模型的“选择困难症“:卡内基梅隆大学与Meta联手发现AI训练中被忽视的隐患
研究发现主流奖励模型对同等质量答案给出差异悬殊的分数,并提出"奖励聚类"算法通过蒙特卡洛随机失活将连续分数离散化,在不重训模型的前提下有效减少AI训练中的奖励作弊现象。

