
IBM发布解决GDPR合规要求的SaaS解决方案
至顶网软件频道消息: IBM已经推出了一项新的企业产品,旨在帮助企业寻求帮助来限制其数据以达到GDPR标准。
欧盟委员会的通用数据保护条例(GDPR)截止日期已过,但仍有一些公司在努力追赶上。
欧洲的网站访问用户发现,一些在线服务在数据管理和实践到位之前处于暂时禁止访问的状态,还有另一些已经从消费者那里收集大量数据的网站现在面临着挑战——找出这些数据的位置,保障信息安全的方式,哪些是在GDPR范围内的信息以及如何遵守条例。
这一挑战是IBM Security新推出的软件即服务(SaaS)产品的核心。
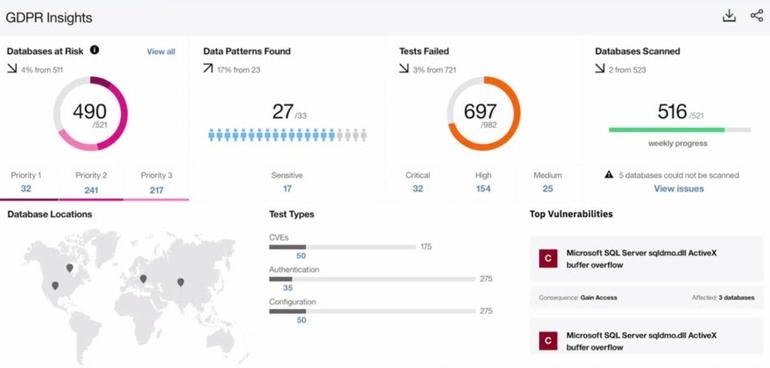
周二宣布推出的这个Guardium Analyzer解决方案是一项SaaS服务,专为在IT环境中找出GDPR相关数据的企业设计。
该工具使用数据分类引擎和基于GDPR的数据模式,在评估并确定应采取哪些措施来优先保护数据之前,跨云环境和内部数据库寻找以及分类信息。
Guardium Analyzer还能够扫描数据库中已知的安全漏洞和那些可能影响数据保护的安全补丁,确定哪些数据库最有可能与GDPR合规相关。
该工具包括一个仪表板,可以根据确保GDPR合规性所采取的措施进行自动更新。
IBM表示:“持续的基准测试对于帮助企业保持合规性并持续构建更强大的数据保护计划来说至关重要。”
IBM Security数据安全和隐私首席技术官Cindy Compert表示:“虽然GDPR于5月25日生效,但很多公司符合GDPR要求方面仍然还处于初期阶段。处理所有现存个人数据是关键的第一步,随着数据不断增加和变化,这也是最难的步骤之一。”
根据IBM首席隐私官和欧洲数据保护官员(DPO)Cristina Cabella的说法,GDPR确实带来了挑战,但这些法规也为企业带来了机遇。
她认为,GDPR需要企业具有“更多的问责制和更高的透明度”,但这些也可以成为改善客
户和供应商关系以及业务创新的基石。
好文章,需要你的鼓励



明尼苏达大学最新研究颠覆认知:训练AI大模型,只需动其中一层就够了?
这项来自明尼苏达大学等机构的研究发现,大语言模型在强化学习后训练中,只需训练中间少数几层即可匹配甚至超越全参数训练效果,且这一规律跨模型、跨任务高度稳定,为更高效的AI训练策略提供了新思路。


台湾大学与NVIDIA揭秘:你的声音正在悄悄改变AI对你的判断
本文介绍VIBE框架,一套通过开放式任务评估大型音频语言模型声音诱发偏见的系统,测试12个模型后发现每个模型均存在显著性别或口音偏见。
2018
06/07
10:43
分享
点赞

机器人管家系统上线!傅利叶携多款康养陪伴新品方案亮相WAIC 2026
赛那德“ 自主作业机器人天团” 登陆 WAIC:iLoabot-X+模型双升级,秀出具身场景落地硬实力
西门子Eigen工程智能体中国首发首展,荣获2026 WAIC SAIL之星奖
NVIDIA Cosmos 推动物理 AI 前沿发展
PPIO亮相WAIC 2026:发布智能模型网关,打造面向Agent时代的智能Token工厂
端侧感知、私有闭环、量子协同, NVIDIA全栈异构计算范式“接管”实体产业底座
边缘智算筑基、全栈软硬协同,研华科技将AI带进产业闭环
千问AI眼镜将升级为智能体眼镜:能灵活调用Skill和Agent,能全天候感知
对话Moonix郭于晨:先让用户戴上“眼镜”,再让“AI”记录世界
亮相WAIC 2026,临床实证赋能康养升级 无芯科技定义AI疗愈新范式
生态覆盖持续扩散,一文看懂各行业企业鸿蒙化转型进度
WAIC亮出集群协作真功夫,优艾智合领跑工业具身智能规模化
