
IDC:2017年前16大公有云服务提供商占据全球公有云服务收入半壁江山
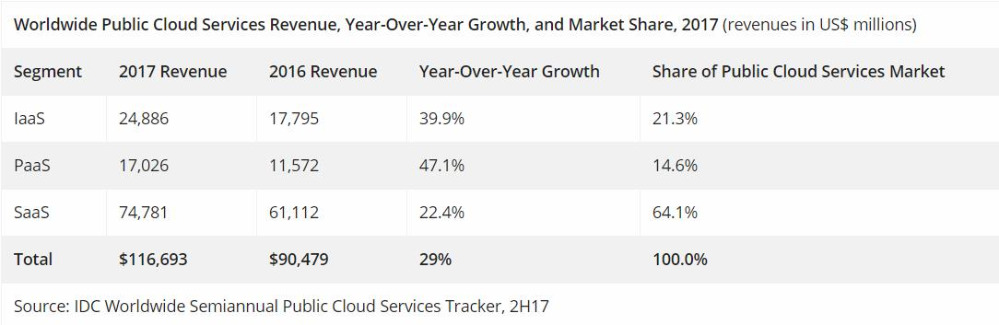
至顶网软件频道消息:根据IDC全球公有云服务半年度追踪报告的2017下半年报告显示,2017年全球公有云服务市场增长29%,总额达1170亿美元。尽管2017年的总体增长率略低于2016年,但前16家厂商(按市场份额)在此期间的收入继续加速增长,并在公有云服务市场占据主导地位。这16家厂商的市场份额从2016年的47.9%上升到2017年的50.7%,占全球公有云服务支出的一半以上。
从区域来看,美国仍然占据大部分公有云服务收入。美国所占的全球份额在2017年略有下降,从62%减少到60%,这是因为其他地区对全球市场的贡献有所增加。据IDC预计,未来几年这一趋势将持续下去,因为新的区域服务和全球竞争对手的扩张日益成为推动全球增长的强劲因素。
IDC高级副总裁兼首席分析师Frank Gens说:“2017年是扩大公有云服务普及的关键一年,公有云服务继续呈现违背通常的市场规律:连续第五年,支出增长保持在29%,即使这个时候市场已经增长了3倍。2017年,主要参与者的市场份额也出现了一些令人感兴趣的变化,他们对云计算的关注度明显提高,竞争压力也在逐渐加大。未来三年将决定未来20年谁将是IT行业的领导者。”
软件即服务(SaaS)细分市场的特点是提供商整合、客户采用日趋成熟以及稳定增长。企业资源管理(ERM)、客户关系管理(CRM)和协作应用程序对SaaS增长贡献最大,占所有SaaS交付应用的64%。2017年,供应链管理(SCM)和内容应用分别代表增长最快的两个SaaS应用类别,增幅分别为27%和28%。
IDC SaaS和云研究总监Frank Della Rosa表示:“SaaS交付模式占全球公有云服务收入的68%。SaaS应用继续以22%的可观增幅增长,2017年达到750亿美元,预计到2022年达到1630亿美元。在系统基础设施软件(SIS)类别,安全SaaS占所有收入的42%,到2022年的复合年增长率为13%。尽管定期有SaaS初创公司涌现,但Salesforce、微软和Oracle等老牌技术厂商仍然位列SaaS提供商榜单之首。”
在平台即服务(PaaS)领域,同比增长率从2016年的48%略微放缓至47%,2017年收入略高于170亿美元。IDC预计随着对新开发方法的认识,同时阻碍公有云采用的因素之间消除,这一增长将持续下去。
IDC平台即服务研究总监Larry Carvalho表示:“应用需求继续推动PaaS服务的增长以提高开发人员的生产力。容器和无服务器计算等新兴技术正在改变PaaS服务的交付和消费模式。随着越来越多的企业展示平台价值,不久的将来采用率将仍然保持在高位。”
在基础设施即服务(IaaS)领域,在新地区的企业采用和增长继续推动着全球IaaS收入的增长。尽管收入增长,但收入增幅本身是放缓的——从2017年的40%下降到2016年的45%——因为2017年的总体市场规模略低于250亿美元。
IDC公有云基础设施即服务(IaaS)研究总监Deepak Mohan表示:“企业采用公有云IaaS仍处于早期阶段。企业IT组织对增加使用公有云IaaS很感兴趣,主要提供商继续在解决大规模采用的障碍。这些因素将继续推动越来越多工作负载部署在公有云IaaS中,预计至少在未来两年内这个市场还将以目前的速度保持增长。”

好文章,需要你的鼓励


豪声电子泰国电声工厂初步投产:2500万泰铢项目进入产能爬坡
今天讲的出海案例是生产微型扬声器、受话器和音响产品的豪声电子,其计划投资2500万泰铢的泰国音响类电声工厂已经进入初步投产阶段。

新加坡国立大学与英伟达研究院联手打破视频生成的“非此即彼“困局:一个模型,两种能力,任意切换
新加坡国立大学与英伟达联合提出Flex-Forcing框架,通过时间帧和去噪步骤两个维度的灵活分块,将双向扩散和自回归视频生成统一到单一模型中,实现质量与效率的自由权衡。


南洋理工大学等机构联合发布:AI看懂艺术的“为什么“,距离人类还有多远?
MUSEBENCH是一个专门测试AI理解视听艺术创作意图的评测基准,涵盖电影、视觉艺术、舞台表演和游戏四类,发现最强AI得分仅48%,远低于人类专家87%。
2018
06/25
10:26
分享
点赞

“驯服”千亿模型,鏖战“黑猴打瓦”,龙虾“一键接管” ,锐龙AI Max+ 395开启全能桌面AI主机“王炸”时刻
豪声电子泰国电声工厂初步投产:2500万泰铢项目进入产能爬坡
地瓜机器人将560TOPS端侧算力,加载到了20+头部团队机器人中
WAIC 2026主论坛(下午场)重磅揭晓!
AI评测初创公司Braintrust遭入侵,敦促所有客户轮换API密钥
牙科诊所软件漏洞修复:患者医疗记录曾遭泄露
关键基础设施巨头Itron确认遭遇网络攻击
Vercel数据泄露范围扩大,黑客早于已知时间节点已入侵
苹果与博通签署300亿美元协议,共同生产美国本土无线芯片
摩托罗拉领投BRINC 1.25亿美元,推动紧急救援无人机大规模扩张
AI赋能芯片设计:前景广阔,疑问犹存
Arm今夏将推出自研芯片,Meta成首批客户
Gartner:到2025年,全球公有云终端用户支出将达到7230亿美元
让AI成为现实,我们需要一位首席人工智能官(CAIO)
Gartner:2023年全球IaaS公有云服务收入增长16.2%
IDC上调数据中心计算与存储支出预测
IDC预测2027年公共云服务支出将达到2190亿美元
Gartner预测2024年全球公有云终端用户支出将超过6750亿美元
2024年超大规模数据中心企业:全球最大型的数据中心运营商将何去何从?
康普【网事数说】 - 1.6T光纤网络何时部署更合适?
Gartner:可持续发展和数字主权将作为选择公有云生成式AI服务的首要标准
硬功夫的巅峰,亚马逊云科技获云原生基础设施技术能力评估最高分
