
甲骨文推出新云基础架构代理服务,简化容器开发
至顶网软件频道消息: 甲骨文公司的目标是令开发人员可以更容易地将基于Kubernetes构建的容器化应用程序与其云服务连进行接。

甲骨文推出新的云基础设施代理(Cloud Infrastructure Broker)是一个重要举措,因为时下Kubernetes已经成了管理基于容器应用程序的流行软件,基于容器的应用程序可以只需构建一次就可以在任何计算平台上运行。 甲骨文有必要大力支持Kubernetes,因此宣布面向普通用户推出新的Kubernetes版甲骨文云基础架构服务代理。
推出甲骨文云基础架构服务代理的消息是在巴塞罗那举行的KubeCon CloudNativeCon Europe 2019活动上宣布的,该甲骨文云基础架构服务代理是Open Service Broker应用程序编程接口的实现,Open Service Broker应用程序编程接口也是一个开源项目,旨在将云服务接入应用程序及其部署工具。甲骨文云基础架构服务代理专用于甲骨文云基础架构服务,甲骨文云基础架构服务是甲骨文自治数据库(Autonomous Database)的产品套件,托管在甲骨文云数据中心上。
开发人员现在借助甲骨文云基础架构服务代理就可以通过API从Kubernetes内部连接到原生甲骨文基础架构服务。甲骨文公司表示,能这样做是甚为重要,因为可以节省开发人员的大量时间。原因是Kubernetes将每个应用程序基础架构的部署、配置和管理进行了自动化,因此可以快速轻松地连接到自主数据仓库和自动事务处理(Autonomous Data Warehouse and Automated Transaction Processing.)等服务。
甲骨文开发人员服务高级首席产品经理David Cabelus表示,“随着DevOps和Kubernetes的更多采用,开发人员希望简化自动部署策略,包括配置和绑定应用程序或微服务所依赖的任何云服务。例如,如果应用程序依赖于运行应用程序的对象存储,那么配置存储桶就应该是应用程序部署过程的一部分。”
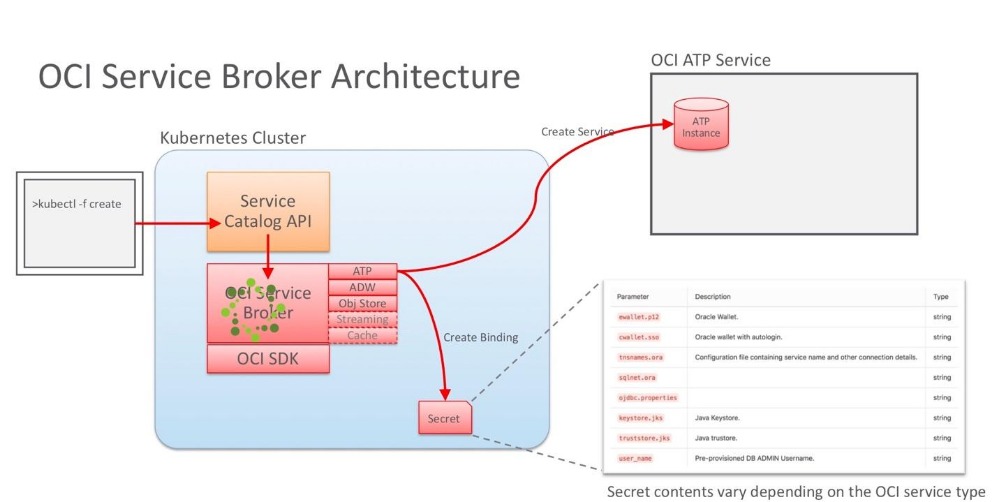
甲骨文表示,甲骨文云基础架构服务代理也有助于实现应用程序的可移植性,即是说在不同的云平台上迁移应用程序更容易些,用户因而可以在甲骨文和其他云提供商之间或本地之间迁移应用程序。
Cabelus表示,“应用程序部署过程里一致模型和嵌入云服务供应的结合意味着,在新的云环境中部署应用程序时系统已经拥有了运行所需的一切。”
甲骨文云基础架构服务代理目前可为旗下的自主事务处理(Autonomous Transaction Processing)、自主数据仓库(Autonomous Data Warehouse)、对象存储和流媒体(Object Storage and Streaming)等服务提供适配器,未来还将为更多服务提供支持。 甲骨文表示,甲骨文云基础架构服务代理可通过GitHub作为Docker容器或Helm图表使用。
其他来自KubeCon大会的新闻:甲骨文还宣布在旗下云基础架构上支持甲骨文Java SE和GraalVM Enterprise Edition。
甲骨文Java SE是甲骨文公司的软件开发工具包,适用于用Java编程语言编写应用程序的开发人员。甲骨文Java SE提供了一系列相关功能,例如允许这些开发人员为任何云平台或操作系统构建应用程序,且无需额外费用即可添加。而GraalVM Enterprise则将“高性能多语言编译器、运行时(Runtime)、SDK和虚拟机”整在一起,可用于编写和运行用JavaScript、Python、Ruby、R、基于JVM及基于LLVM等语言编写的应用程序,基于JVM的编程语言包括Java、Scala、Clojure、Kotlin和,基于LLVM的编程语言包括C和C++。
甲骨文Java SE和GraalVM Enterprise Edition两个SDK现在都可以通过甲骨文Cloud Developer Image从甲骨文Cloud Marketplace下载。
来源:siliconANGLE
好文章,需要你的鼓励


豪声电子泰国电声工厂初步投产:2500万泰铢项目进入产能爬坡
今天讲的出海案例是生产微型扬声器、受话器和音响产品的豪声电子,其计划投资2500万泰铢的泰国音响类电声工厂已经进入初步投产阶段。

华东师范大学等多家机构联合出手:让机器人训练数据“少而精“,原来靠这个秘密武器
SIEVE是一种面向机器人模仿学习的数据筛选方法,通过发现可复用行为原语和转换接口,用50%数据和训练量超越全量训练效果。


马萨诸塞大学的研究者们证明了:搜索引擎的“比较策略“在数学上优于传统方法
马萨诸塞大学从数学角度证明,MaxSim评分策略在理论能力上超越传统单向量内积方法,并提出Signed MaxSim扩展,显著改善否定查询性能。
2019
05/21
17:55
分享
点赞

“驯服”千亿模型,鏖战“黑猴打瓦”,龙虾“一键接管” ,锐龙AI Max+ 395开启全能桌面AI主机“王炸”时刻
豪声电子泰国电声工厂初步投产:2500万泰铢项目进入产能爬坡
地瓜机器人将560TOPS端侧算力,加载到了20+头部团队机器人中
WAIC 2026主论坛(下午场)重磅揭晓!
AI评测初创公司Braintrust遭入侵,敦促所有客户轮换API密钥
牙科诊所软件漏洞修复:患者医疗记录曾遭泄露
关键基础设施巨头Itron确认遭遇网络攻击
Vercel数据泄露范围扩大,黑客早于已知时间节点已入侵
苹果与博通签署300亿美元协议,共同生产美国本土无线芯片
摩托罗拉领投BRINC 1.25亿美元,推动紧急救援无人机大规模扩张
AI赋能芯片设计:前景广阔,疑问犹存
Arm今夏将推出自研芯片,Meta成首批客户
