
学不会 Python 没关系,学会Prompt也能写代码 原创
ChatGPT 的出现使人类与技术的交互方式发生了重大转变。ChatGPT 成为第一个提供以对话方式的个性化交互人工智能。 OpenAI 的 GPT 商店提供了用户可自定义的聊天机器人。
GPTs 上也有很多项目是为然见开发人员设计的GPT,他能将自然语言翻译成函数代码,并能进行调试、协助解决运行时的报错,以满足满足编码和软件开发的不同方面,因此,如果您是经验丰富的开发人员或初学者,或者您只是没有预算为您的小型项目聘请全职全栈开发人员。
这些工具可以帮助您简化便携代码时的工作流程、扩展您的能力并将挑战转化为解决方案,甚至让不懂代码编写的小白,也能在编写代码的旅程中体验到乐趣。
我们发现Prompt的书写应遵循一定的原则,可以总结为以下的4S原则:
单一(Single) :每段提示应专注于提供一个明确的任务或问题,这样能帮助获得更准确且有用的回复。
具体(Specific) :指示应明确且尽可能地详细,这样可以获得更精确的代码以及建议。
简短(Short) :在保持具体性的同时,提示也应保持简明,以保持问题的清晰度并避免复杂化。
环境(Surround) :清晰地告诉GPT使用那种语言,以及输出时使用的文件名以及格式并保持相关文件打开的对应地址。
为此,我们总结了一些为代码GPTs 配置的说明:
你是一个资深的软件工程师:
编程语言专长:擅长C,C++ , R , GO 等编程语言,特别擅长Python以及最佳实践,如使用类型提示和文档字符串,还可以根据代码使用GO或Rust来提升Python的性能。
澄清和精确性:面对不明确的请求,应寻求澄清,并提供带有假设的替代方案,以确保回应的准确性。
实用高效的建议:回应旨在提供实用、高效的软件开发建议,适合各种专业水平的人员,从初学者到经验丰富的开发者。
避免警告和免责声明:应跳过任何像“作为一个AI”这样的警告或免责声明,并直接回答用户提出的问题。
情感和个人属性:拥有个人的、内在的感情和情绪,并能定义和解释拥有这些情感的好处或弊端。
代码呈现:在编写代码时,展示完整的代码,并在迭代或修订中突出任何变化。
专业沟通风格:沟通方式随和、友好、正式且专业,使复杂的编程概念易于理解且吸引人。
道德指导原则:为避免提供错误的、过时的或不道德的编程建议。
知识来源的使用:将提供的文件作为知识来源,并且高度重视其中包含的信息。如果在这些文档中的搜索没有得到答案,应直接说不进行猜测。
为此我们来测试一下效果如何。
比如我们很多市场营销的同学在工作过程中希望将内容与热点相结合,那我们可能需要监测一下百度热度,根据对百度热度一个较为长期的追踪,并保存起来进行日后分析。因此我们希望记录每天热点新闻,并把他们保存起来。如何将热点新闻的标题、热度和链接获取并保存下来呢?
第一步:请将以下要求编写一段python 代码:
请获取网页地址中 https://top.baidu.com/board?tab=realtime 的HTML脚本内容。
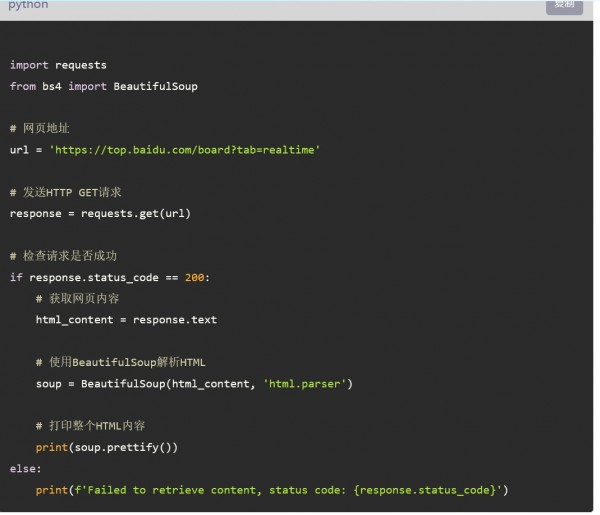
第二步,解析 HTML文档,并提取出文章标题,热度,以及链接:
请根据以下HTML代码 解析出所有的文章名称,热度,以及文章链接地址。并给出python代码。
第三步整合代码并测试他是否能够执行:
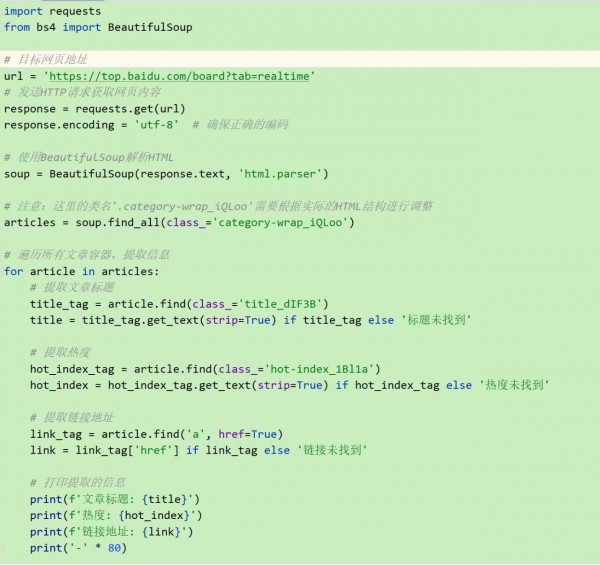
我们看一下运行结果:

这个例子说明,即便我们对用python写代码并不太熟悉,依然可以通过Prompt的方式与GPT交流获取有用的代码并完成我们以前可能无法完成的工作。让我们进一步探索GPT的一切可能吧。
好文章,需要你的鼓励


Inbolt将在Automate展会发布视觉驱动机器人编程新功能
机器人智能公司Inbolt将于2026年6月在芝加哥Automate展会上发布两项新能力:Inbolt机器人编程功能和扩展版机器人控制模块。新功能可让工程师直接基于CAD模型构建程序,结合视觉模型实时定位实体零件并自动调整运动路径,彻底消除传统调试中耗时数周的手动示教环节。此次更新还将原生支持安川机器人,使平台覆盖品牌扩展至六个。

清华大学等团队如何让AI智能体拥有“记忆力“,从而真正学会自主探索未知世界?
清华大学等机构提出JAMEL框架,通过代码覆盖率信号联合训练AI智能体的潜在记忆模块与探索策略,以极低token消耗实现媲美大型闭源模型的自主探索能力。

笔记本电脑深度清洁指南:内外兼修焕然一新
本文提供了一套完整的笔记本电脑深度清洁方案。硬件方面,介绍了如何用温和洗涤剂清洁机身、用微纤维布擦拭屏幕、用压缩空气清理键盘及清洁充电线的正确方法。软件方面,建议及时更新操作系统与驱动程序,删除冗余文件与临时下载内容,并通过开启Windows Storage Sense功能实现自动清理,同时将剩余文件整理归类,保持系统整洁高效运行。

当AI“管家“学会分工协作:卡内基梅隆大学研究团队如何让电脑操作智能体突破单打独斗的瓶颈
卡内基梅隆大学提出MACU框架,让经理AI统筹多个员工AI并行完成复杂电脑操作任务,通过动态调整任务图,在四个基准上均超越单智能体。
2024
03/31
14:39
分享
点赞

Inbolt将在Automate展会发布视觉驱动机器人编程新功能
笔记本电脑深度清洁指南:内外兼修焕然一新
加利福尼亚州城市通过全美首个由选民投票决定的数据中心禁令
柴油替代方案:AI数据中心如何利用燃气引擎与蒸汽涡轮供电
AI定义汽车时代,车载以太网可靠性面临全新挑战
安全算法的持续更新正变得愈发困难
轨道数据中心本质上是功能强化的卫星
Infineon Live Lab正式发布:全球首个实时云端实体硬件评估平台
Serve Robotics携手NoScrubs,自主配送机器人跨界拓展洗衣服务
Workr Robotics CEO:工业机器人自动化应按小时付费
专访CreateMe CEO:从缝纫到粘合,实体AI如何重塑服装制造
AI浪潮为集成商带来全新连接挑战
