
AI以全新方式助力医生获取专业知识
想象一下,一位20世纪50年代的医生正在治疗一位症状复杂的患者。他会首先查阅袖珍工具书《华盛顿医学治疗手册》,接下来又翻开办公室里保存的冗长参考资料《哈里森内科学原理》。由于仍然难下诊断,他又与同事们讨论了这个病例,再动身前往医院的图书馆中搜索相关期刊文章。
在整个20世纪,医生主要就是依靠这种方式检索医学知识。然而几十年过去,信息总量激增,计算机将知识内容数字化、互联网则连通了整个世界。到21世纪初,医生转向在线信息来源,首先通过台式电脑、随后则开始使用移动设备。
现如今,医生们又多了更多知识检索方案。
医生们会经常搜索PubMed及谷歌学术等数据库,翻阅UpToData主题摘要。有三分之二的从业者会使用MDCalc,这是一款带有各种决策支持功能的即时参考工具。此外,医生们还会访问专业协议网站、WebMD等医学网站,有时甚至还会参考非医学类网站。
而人工智能的大爆发再次改变了我们获取知识的方式。在本文中,我们将一同了解AI科技如何帮助从业者在信息浪潮中紧跟时代步伐。
在信息浪潮中紧跟时代步伐
PubMed索引共包含3600万篇综述文章,并且以每年100万篇的速度持续增加——相当于每分钟新增两篇。谷歌学术上则包含约4亿篇论文、引文及专利,外加几千份临床实践指南。很明显,没有任何人类医生能够跟得上这样的知识更新速度。
在20世纪90年代初,热爱网球、极具前瞻性思维的哈佛医学院肾病专家Bud Rose博士曾尝试开发一款计算机程序来解决这个问题。这款程序能够搜索并定期更新存储在软盘之上的临床“主题卡”,而由此建立的公司被他命名为UpToDate。
随着主题数量的增加,存储介质也变成了CD-ROM、互联网以及移动设备。
如今,UpToDate已经成为Wolters Kluwer Health的组成部分,其中约有8000名附属临床专家及60名副主编共同遵循同行评审的循证医学方法,开发并维护着涵盖25个医学专业的1.2万份临床主题摘要。
这款产品大获成功。目前来自约5万家医疗机构的近300万临床医生都在通过机构订阅等形式使用UpToDate,面向个人用户的年度订阅价格则为579美元。
这份权威摘要大受欢迎自然有其原因。正如Wolters Kluwer Health首席医疗官Peter Bonis博士在采访中所言,“我们所做的一切,都是为了帮助临床医生针对患者病情做出最佳决策。”
然而,由于其并不属于查询服务,所以医生必须翻阅相关主题摘要才能为困扰自己的问题找到答案。例如,UpToDate无法直接回答用户“如何治疗小肠细菌过度滋生?”的问题。相反,用户需要先搜索SIBO、选择主题摘要,再浏览结果才能发现作者普遍推荐利福昔明作为首选疗法。该公司报告称,用户交互的平均持续时间长达60秒。
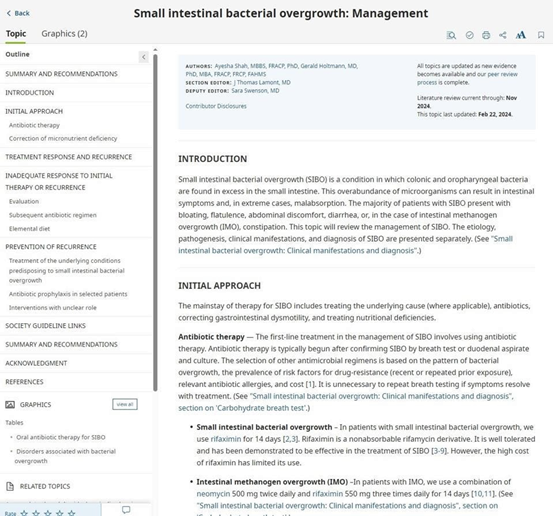
UptoDate主题摘要示例
运用AI科技管理医学知识
UpToDate目前正为平台添加AI驱动搜索功能,以便用户可以直接从现有摘要中访问到有针对性且可逐字逐句查询的相关段落。其目标也非常明确,让产品更加易用、效率更高,同时避免因引入AI生成内容而导致的错误。
OpenEvidence及Consensus等专门构建的新兴AI原生搜索引擎则采用了不同的实现方法。这些产品不会显示预先写好的主题摘要,而直接以动态形式回应用户的查询。
这类解决方案面临的核心挑战,在于如何确保其输出足够可靠以符合医疗实践的要求。生成式AI产品经常会产生不够稳定的答案。例如,谷歌Gemini大模型就曾犯下广为人知的错误,建议人们每天吃一块石头,理由是“石头是矿物质和维生素的重要来源”。
这类“幻觉”在很大程度上反映了所谓“垃圾进、垃圾出”的问题。正如OpenEvidence公司创始人Daniel Nadler对此做出的解释,“网站索引并不是事实索引。”因此在整个互联网数据(包括来自Reddit及Onion网站的数据)之上训练而成的大语言模型,必然会产生虚假信息。
Nadler创立的这家公司源自梅奥诊所的平台加速计划,希望通过确保仅从经同行评审的生物医学文献中汲取知识来回避这些问题。
当用户(必须身为临床医生)输入宽泛或具体的问题(例如「对于买不起利福昔明的患者,我该如何治疗小肠细菌过度滋生?」)之后,OpenEvidence会在数百万份临床文档中识别出潜在的相关来源,包括对PubMed摘要、期刊文章全文、专著、书籍章节等中的元数据进行索引。在此之后,它会根据查询的相关性、出版日期、期刊影响因子以及引用计数等因素选择最权威的知识来源。最后,由大语言模型整理出带有引用来源链接的摘要响应结果。
OpenEvidence正在医学领域迅速传播。自今年1月以来,已经有超过25万名临床医生访问该网站,单在刚刚过去的11月就完成了近200万次查询。该产品主要靠广告支持运营,个人用户可以免费使用。
另有一款名为Consensus的AI搜索引擎,涵盖医学以及生物学、环境科学等非医科学领域。此网站面向公众开放,其中临床医生占用户总量的五分之一。在输入问题之后,Consensus就会整理答案,同时辅以指示建议强度的“共识指标”(对于是/否类问题)。
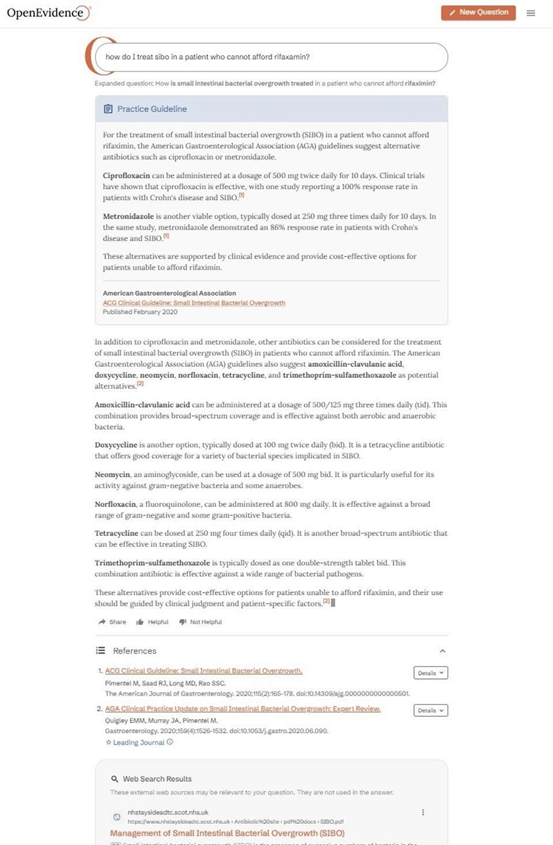
OpenEvidence查询响应示例
权衡利弊
打个比方,搜索PubMed或者谷歌学术就类似于向图书管理员询问特定主题的最佳知识来源。UpToDate则更接近图书馆中的特殊收藏。在使用这些工具时,用户必须浏览大量超链接列表,选定并阅读来源、再从中提取相关信息。通过这样的过程,用户需要花费一些时间和精力来逐渐了解某个主题,再根据自己掌握的新知识尝试解决特定问题。
与此不同,使用OpenEvidence或者Consensus等AI搜索则类似于直接向一位聪明的教授提问并收到带有参考资料的答案。其快速、方便而且非常具体。个中的风险在于,某些“言之凿凿”的答案可能达不到置信标准或者缺乏充分的背景信息。因此,临床医生必须全程持续跟进,并在必要时进行深入挖掘。
为此,我们向两位杰出的信息学医生询问了他们对AI搜索的看法。
MDCalc创始人兼急诊科医生Graham Walker博士警告称,“人们对于自动化系统可能引发偏见的担忧值得关注——已经有一部分医生默认这些工具比自己更聪明,而这会逐渐削弱医生对于患者症状进行批判性思考的能力。”
在另一方面,心脏病专家及信息学家Larry Klein博士则认为AI搜索具有显著且纯粹的积极作用。他解释称,“我每天都在使用OpenEvidence,向它问题,它就像随时坐在我身边的一位专家级同事。这项技术毫无疑问具有革命性意义。”
但请注意,传统搜索与AI搜索其实各有用处,只是适用场景不甚相同。例如,接收急性冠状动脉综合征患者的住院医生可能会查阅UpToDate以了解诊疗原则,而一位杰出的肾病学家也可能会搜索PubMed来参考肾小球肾炎治疗试验中患者的特征。与此对应,在青霉素过敏的情况下,决定是否治疗幽门螺旋杆菌感染的家庭护士则可向OpenEvidence查询以获取快速指导。
展望未来
调查发现,临床医生每接待两名患者,就会面对至少一个医学知识方面的问题——通常涉及症状产生原因或者疾病的治疗方法。然而,医生们往往只能为半数问题找到答案,主要就是因为没有充足的查询时间。
AI搜索能够加快信息传播速度来协助解决这个问题。然而,这种新的工作方式也凸显出人机管理、细微差别与简洁性、自动/手动处理以及潜在的机器错误/人为错误之间的密切关联。我们必须认真评估这些AI工具如何影响临床工作人员及患者,努力保证其尽量发挥更纯粹的积极作用。
纵观行业历史,医生管理信息的方式一直在变化并且备受关注。例如,当初曾有许多医生反对从医学教科书中学习知识,强调根据经验总结心得才能让人们进行更加深入的思考。几十年后,又有人“坚持认为医疗信息的数字化,破坏了有形纸质工具所承载的传统思维与认知实践。”
发展之路从来不可能一帆风顺。快速运用集体知识的能力既可以帮助医疗从业者更好地减轻病患痛苦、促进诊疗体验,也有助于减轻医生们的认知负担以保持更充沛的精力与工作状态。
随着各类新兴AI功能的出现,我们应当将重点从回忆事实转向提出正确问题。尽管答案的出现速度远远超过历史上的任何时期,但大多数临床决策仍然缺乏充足的已发表数据。因此,临床直觉和经验仍然非常重要——与以往任何时候都同等重要!正如循证医学运动的先驱们解释的那样,“优秀的医生既善于运用个人临床专业知识,也重视对高质量外部证据的参考,二者不可偏废、应当相辅相成。”
好文章,需要你的鼓励


米拉·穆拉提重返公众视野,谨慎发声
穆拉蒂时隔18个月首次接受重大媒体采访,介绍其创立的Thinking Machines Lab正在开发的"交互模型"。该模型能以200毫秒间隔处理音频、文本和视频流,捕捉人类交流中的中断、修正和停顿。她还谈及OpenAI"政变周"经历,强调行业决策权过于集中的担忧,并回应了公司近期研究人员离职问题,表示这是初创实验室的正常波动。

当AI机器人“自信地“撞向墙壁:STATE16研究院揭示物理AI系统中那些无声无息的致命错误
STATE16研究院这篇综述发现,物理AI系统存在"静默失效"风险——AI以高度自信执行基于错误世界信息的动作,却不触发任何报警,并提出在AI输出与物理执行之间建立独立授权层的框架。

特斯拉疑似删除FSD证据,卡特彼勒加速电动化布局,高压系统技术培训刻不容缓
本期《Quick Charge》播客涵盖多个热点话题:特斯拉疑似试图删除FSD欺诈相关证据以规避巨额赔付;卡特彼勒持续推进建筑领域电气化布局;住宅太阳能30%税收抵免即将到期。此外,嘉宾Tom Pacheco就高压系统与电池技术培训展开探讨,强调电动车技术人才培养的紧迫性。节目同时提醒有意安装太阳能的用户尽快行动,可通过EnergySage平台比较多家安装商报价。

当AI学会“边干边学“:UIUC与微软联合打造的网页智能体训练新范式
UIUC与微软联合研发的OpenWebRL框架让4B小模型仅凭400条初始数据,通过在真实网站上边做边学的强化学习方式,在网页智能体基准上超越了用27万条数据训练的竞争对手。
2024
12/23
14:15
分享
点赞

特斯拉疑似删除FSD证据,卡特彼勒加速电动化布局,高压系统技术培训刻不容缓
智能体网络流量首超真人访问,"死亡互联网"理论引发新争议
Mentium Technologies Luna-R1 AI芯片入选ET-01星座任务,完成多星部署里程碑
汤道生×姚顺雨:腾讯AI下半场,拼的是“模型×产品”系统能力
AI驱动网络犯罪数量飙升,勒索软件受害者年增389%:Fortinet 发布2026年全球威胁态势研究报告
Inbolt将在Automate展会发布视觉驱动机器人编程新功能
笔记本电脑深度清洁指南:内外兼修焕然一新
加利福尼亚州城市通过全美首个由选民投票决定的数据中心禁令
柴油替代方案:AI数据中心如何利用燃气引擎与蒸汽涡轮供电
AI定义汽车时代,车载以太网可靠性面临全新挑战
安全算法的持续更新正变得愈发困难
轨道数据中心本质上是功能强化的卫星
