
AI+设计,人工智能赋能悟空图像,让你的创作瞬间绽放!
近日,有国产Photoshop之称的“悟空图像”发布了最新的升级版。令人惊喜的是,小编发现,该版本进一步增强了AI作图功能,进行了大幅改版。一系列的创新引入使得悟空图像成为了国内市场上首款具备AI作图能力的专业图像处理软件。
AI作图功能的加入,为悟空图像带来了巨大的潜力和发展空间,设计门槛的降低,将惠及更多普通人。通过深度学习算法和大量的训练数据,用开放大模型叠加定向训练的小模型,悟空图像能够自动生成高质量的图像作品,不仅仅是通过文字定义设计,还可以通过参考图片选择自己满意的变换风格,线稿直接一键转漫画当然不在话下,利用色块图和景深图还可以精确控制生成区域和生成内容,通过图像分割和图片语义识别,还能够方便的进行二次编辑修改。无论是艺术家、设计师还是普通用户,都可以通过简单的操作,快速获得令人满意的图像结果。
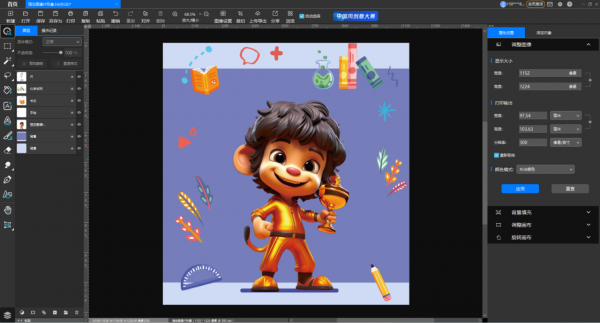
悟空图像的卡通图像“小悟空”就是其AIGC功能的杰作
小编体验之后,感觉非常惊艳。和其他AIGC的作图软件相比,作为把AI集成在专业级图像处理软件之中的国产PS,悟空图像具有三大特别的优势:易用性、可控性和全面性。
首先是易用性。悟空图像的AI功能非常易于使用,操作界面采用瀑布流的模式,无论以文生图还是其它图像生成方式,都按照时间瀑布流直接展示,方便回溯。无论你在日常生活中遇到什么图像处理难题,悟空图像都能提供一步到位的解决方案。它通过简便的操作和直观的界面,让用户能够快速完成各种复杂的图像处理任务。无论是普通用户还是专业用户,都可以轻松上手并发挥出AI的强大功能。
其次是可控性。悟空图像的AI功能不仅易用,还具有很高的可控性,每个生成的图像都有景深图、语义图的属性,可以直接进行局部修改或者消除,进行二次编辑和生成。用户可以根据自己的需求进行个性化设置,以满足特定的图像处理要求。例如,悟空可以根据用户的要求智能调节图像贴合描述的指数;又如,通过高级设置精细调控成像品质和图像细节。这种灵活性和个性化定制的能力,使用户能够更好地控制AI生成的内容,并获得满意的结果。
尤其让小编惊喜的是,悟空图像专门推出了基于AIGC技术的“AI擦除功能”,可以去除繁杂的人群、多余杂物或水印等,让图像更加清晰和专业。
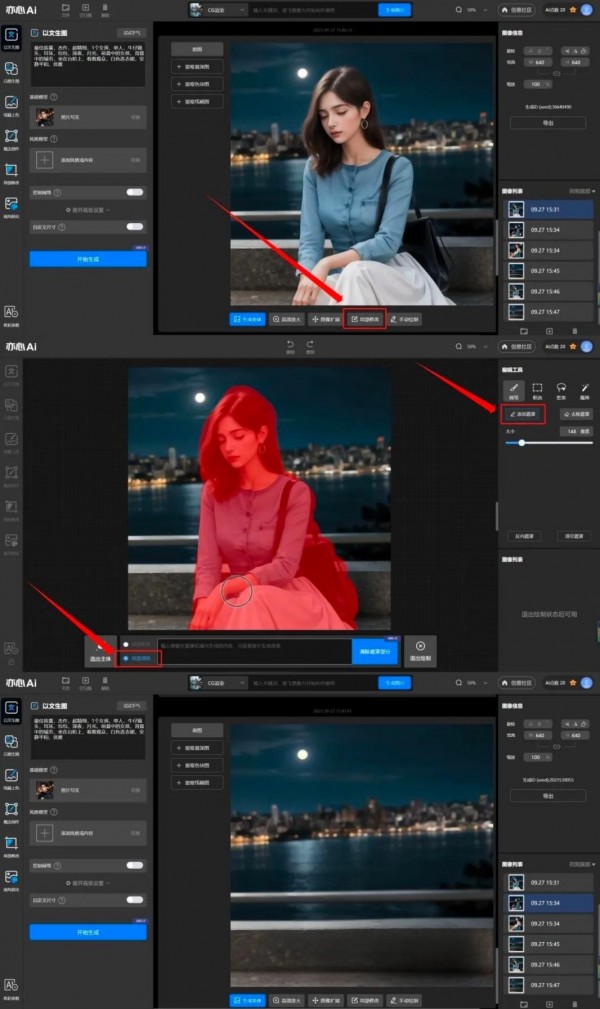
悟空图像的AI智能擦除功能使用流程
最后是全面性。悟空图像的AI功能非常全面,涵盖了多个领域和应用场景,还有极强的语义图和景深图支持,非常方便我们进行各方面的应用。它支持十余种艺术风格的AI作画,可以满足探索者的好奇心,还能让用户进行个性化的系列专业设置,为专业用户的生产力做出扎实的贡献。除了“凭空作画”,悟空还支持帮你“接着画”,只需提供线稿,即可根据要求进行AI上色,大幅节约了制图时间,为创意设计行业带来了巨大变革和无限可能。
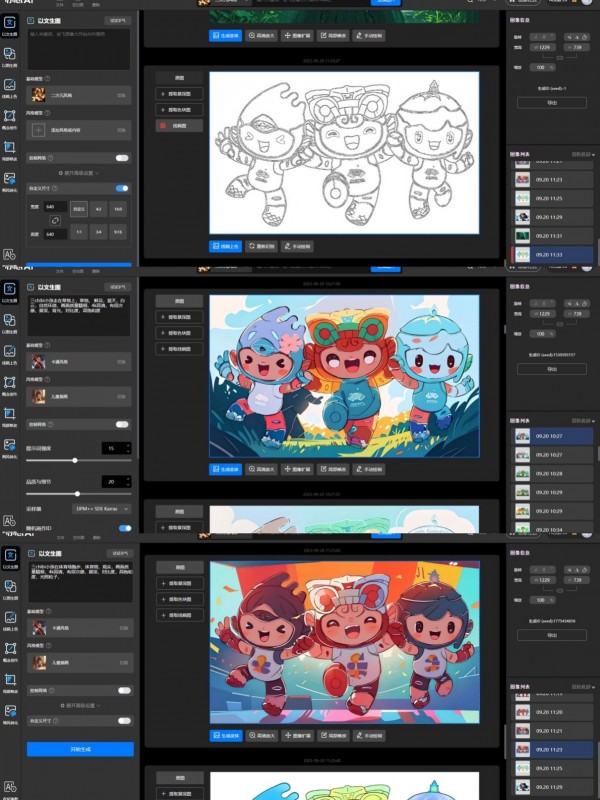
悟空图像的AI线稿上色功能为专业设计用户简化工作流
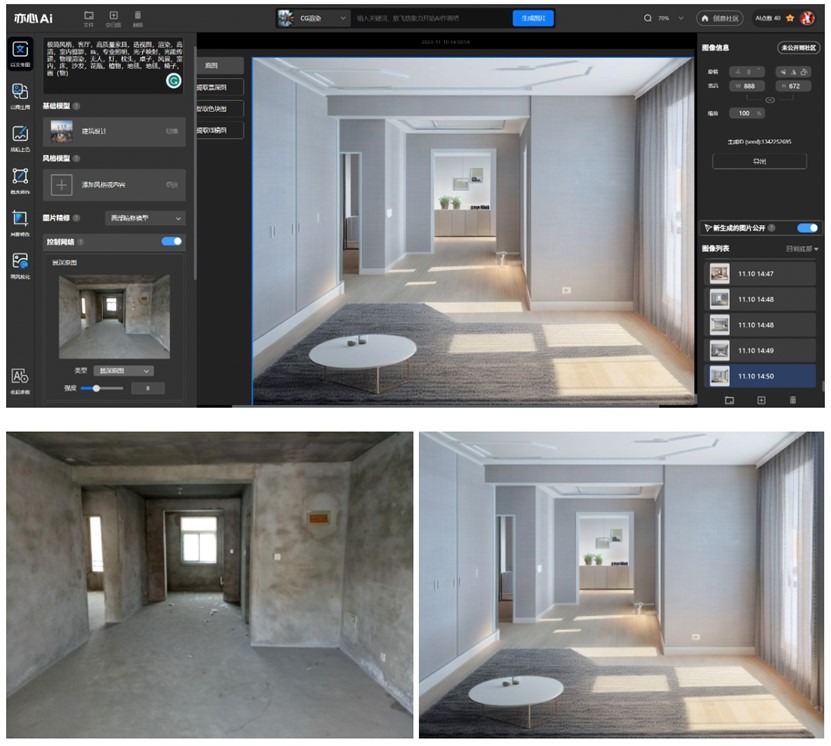
悟空图像能通过添加毛坯房输出装修效果
小编的感觉是,悟空图像集成AI作图功能,不仅提升了用户的工作效率,也为创意表达提供了更多可能性,也降低了设计门槛。无论是创作艺术作品、设计广告海报,还是制作个人照片集,悟空图像的AI作图功能都能帮助用户实现更高水平的创作。
可以说,悟空图像作为国内最早、也是唯一将AIGC深度集成的专业图像软件,以其易用、可控和全面的AI功能,给盼望国产工具的专业用户们交上了一份令人振奋而充满期待的答卷。它的出现填补了专业图像处理领域的空白,也为中国的图像处理行业注入了新的活力和创新力。

悟空图像能将用户涂鸦转成一幅画
悟空图像创始人刘昌伟曾经说过,悟空图像的目标是:让人人都成为设计师。悟空图像的AI作图的闪亮登场,让这个目标又更近了一步!
来源:至顶网软件与服务频道
好文章,需要你的鼓励



RLDP:卢森堡大学让隐私保护AI训练的颠覆性突破——一种自学习的“智能管家“让数据安全与模型效果完美共存
卢森堡大学研究团队开发的RLDP框架首次将强化学习应用于差分隐私优化,创造性地解决了AI训练中隐私保护与模型效果的矛盾。该方法如同智能教练,能动态调整隐私保护策略,在四种语言模型上实现平均5.6%的性能提升和71%的训练时间缩短,同时增强了抗隐私攻击能力,为敏感数据的AI应用开辟了新路径。

北大团队揭秘AI安全训练为何如此脆弱——大模型中隐藏的“弹簧效应“
这项由北京大学人工智能研究院完成的研究,首次从数据压缩理论角度揭示了大型语言模型存在"弹性"现象——即使经过精心安全对齐,模型仍倾向于保持预训练时的行为分布。

腾讯混元团队发布MixGRPO:让AI图像生成训练效率提升71%的混合式加速方案
腾讯混元团队联合北京大学提出MixGRPO技术,通过混合ODE-SDE采样策略和滑动窗口机制,将AI图像生成训练效率提升50%-71%,同时在多项人类偏好评估指标上超越现有方法。该技术采用"从难到易"的渐进优化策略,专注于图像生成早期阶段的重点优化,并引入高阶求解器进一步加速训练过程,为AI图像生成的产业化应用提供了更高效可行的解决方案。
2023
11/17
09:40
分享
点赞

高途x人大:在教育的深处,种下“有温度的AI”
北大团队揭秘AI安全训练为何如此脆弱——大模型中隐藏的"弹簧效应"
AI地震检测技术:像戴上眼镜一样清晰
医疗集团CIO采用AI提升生产力,在联络中心谨慎推进AI应用
仅需250个恶意文档就能让大语言模型产生后门漏洞
CIO们利用AI助力IT采购决策,超八成决策者已开始使用
AI拥抱并扩展企业软件市场,资金持续涌入
Spotify已可连接ChatGPT:互动功能体验升级
量子计算公司IonQ获得20亿美元融资加速商业化进程
Apple 收购计算机视觉初创公司 Prompt AI
Windows Copilot现可创建Office文档并连接Gmail
用上18A的英特尔至强6+,究竟“+”了什么?
