
微软率先拿下HBM驱动的AMD CPU供货
英特尔是第一家在CPU封装当中添加HBM堆叠DRAM内存的主要CPU制造商,相应推出的正是“Sapphire Rapids”Max系列至强SP处理器。但随着“Granite Rapids”至强6的发布,英特尔决定放弃使用HBM内存,转而采用其希望推向主流的MCR DDR5主内存。该内存采取频分多路复用设计,可将带宽提升至近2倍于常规DDR5内存。
英特尔之所以为Sapphire Rapids添加HBM内存,当然有其现实考量。其主要目的是为了提高百亿亿次“Aurora”混合CPU-GPU超级计算机中的CPU性能。这台超级计算机是英特尔在HPE的帮助下专门为阿贡国家实验室量身打造而成。Aurora设备拥有2.1248万个至强SP Max系列CPU,封装在10624个节点当中,此外还配备总计63744张英特尔“Ponte Vecchio”Max系列GPU。(即单一节点中由两块CPU搭配六块GPU,几乎已经占去了Cray EX托盘设计的全部物理空间。)
芯片巨头向CPU中添加HBM内存的另一个原因,是希望其他高性能计算中心能由此意识到对于尚未被移植至GPU而仍在沿用CPU的应用程序(或者即使经过移植也无法在工作负载上获得更佳性能的应用程序),只要搭配一块拥有更大内存带宽的CPU(大约达到常规DDR5内存的4到5倍),那么无需面向GPU移植代码也能显著提高应用程序的性能表现。
我们认为把HBM引入CPU确实有其合理性。除了Aurora之外,另外一些颇受关注的设备也在使用这种内存设施,包括2022年9月安装在洛斯阿拉莫斯国家实验室的“Crossroads”ATS-3全CPU集群。Crossroads总计部署有11880块英特尔至强SP-9480 Platinum Max处理器,每块处理器提供56个运行主频为1.9 GHz的核心,总计提供66.08万个核心,可在6.28兆瓦的功率范围之内以FP64精度提供40.18千万亿次的峰值理论浮点运算性能。
但正如前文提到,由于没有继续发布拥有更大性能核(即P核)的Granite Rapids至强6版HBM处理器,英特尔给AMD的HBM增强型CPU留下了发挥的空间。而这,正是传闻中基于Instinct MI300系列计算引擎的“Antares-C”变体。
“Antares”MI300X拥有八块GPU芯片,但在软件层次上其观感类似于单块GPU。本周在SC24超级计算机大会上亮相的劳伦斯利弗莫尔国家实验室“El Capitan”系统中使用的“Antares-A”MI300A就拥有六块GPU芯片以及三块八核“Genoa”芯片、总计24个核心(每芯片八核心)。本周在SC24大会和拉斯维加斯召开的微软Ignite大会上同时亮相的MI300 C,则是将Genoa芯粒部署在MI300封装之内——即两列六芯片下囊括十余个芯粒——共可提供96个Genoa核心,我们推测其运行主频与El Capitan中使用的MI300A混合计算引擎上的Zen 4核心同样为1.9 GHz。顺带一提,MI300A上的GPU芯粒的峰值主频为2.1 GHz。
然而,这款设备并非以MI300C的名号销售,而被纳入了Epyc CPU产品线之下,因此定名为Epyc 9V64H,跟英特尔的至强SP Max系列CPU一样明确面向高性能计算类工作负载。也就是说,该设备将适用于类似MI300 X和MI300A设备的SH5插槽,而非用于Epyc 9004(Genoa)和9005(Turin)系列的SP5插槽。
值得注意的是,AMD及其MI300C设备的首位客户微软Azure并没有选择基于较新Turin Zen 5核心建立的计算引擎变体。当初AMD着手为El Capitan制造混合CPU-GPU芯片时,MI300C的工作应该已经基本完成,AMD显然不希望让Turin的秘密过早暴露,否则劳伦斯利弗莫尔实验室可能会要求调整MI355A中的Antares GPU以确保与El Capitan的Turin CPU旗鼓相当。
话虽如此,对于AMD来说,基于Zen 5c核心的Turin芯片来打造MI355A或者Epyc 9V65H也不会是什么太大的工程技术挑战。Turin X86 CPU于今年10月发布,提供采用3纳米制程工艺的八核Turin芯片,使得每插槽所能容纳的芯片数量增加了三分之一,因此核心数量也从Genoa的96个增加到了Turin旗舰版本的128个。当然,Turin芯片和MI300 SH5插槽可能已经发布,但理论上AMD确实可以将16个X86芯粒排成两列以快速构建起具有128核心的MI355C——毕竟AMD在Epyc 9006系列中就是这样设计的。真正的问题在于,MI300系列当中的新款I/O芯片到底能否无缝接入Turin芯片。
最重要的是,Epyc 9V64H拥有128 GB的HBM3内存,峰值主频速率为5.2 GHz,可提供总计5.3 TB/秒的峰值内存带宽。相比之下,使用4.8 GHz DDR5内存的普版Genoa SP5 CPU插槽只能在十二条DDR5内存通道上提供460.8 GB/秒的带宽。也就是说,同样是以96个Genoa计算核心为参考标准,前者的内存带宽可提高至11.3倍。
顺带一提,2022年11月推出的至强SP Max系列CPU拥有四个HBM2E内存栈,总容量为64 GB,该内存的总带宽超过1 TB/秒。也就是说,AMD提供的核心数量增加了71%,内存容量增长至2倍,内存带宽则相当于英特尔HBM CPU的约5倍。
更妙的一点在于,微软为Epyc 9V64H处理器选择的归属其实是Azure云上的四插槽HBv5实例——从该实例的配置来看,核心和内存的某些指标相较其峰值理论上限稍微调低了一点,这应该是为了拉高其他某些属性而做出的权衡。
El Capitan系统采用Infinity Fabric将四个MI300A单元交叉耦合至共享内存结构当中,以便其混合CPU-GPU核心共享512 GB的HBM3内存。而微软似乎也在使用相同的架构:
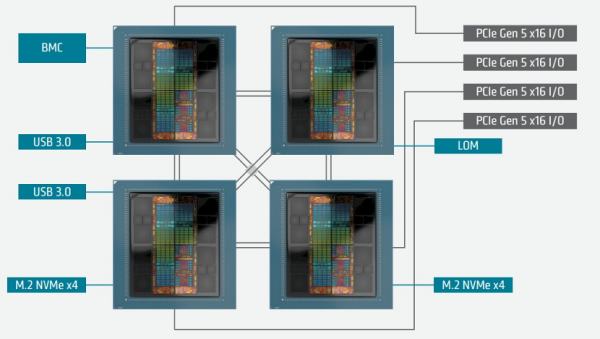
据我们所知,无论是谁在负责为HPE制造这批系统板,其最终客户都是微软Azure——甚至有理由怀疑,正是HPE亲自在为Azure HBv5实例及其背后的整个服务器节点制造主板。
这批用于MI300C的四路服务器卡(也就是Epyc 9V64H)拥有四个Infinity Fabric端口,可交叉链接四个SH5插槽,该内存架构拥有128 GB/秒带宽,同时为每节点提供四个PCI-Express 5.0 x16插槽。微软方面表示,这一参数已经达到迄今为止所有AMD Epyc平台Infinity Fabric带宽的两倍。
无论如何,最重要的一点在于,AMD使用SH5插槽为其GPU式计算引擎建立了四路共享内存配置,但其实际CPU设置仍然只能达到双路共享内存配置。但如果客户需要一台AMD四路设备,也并非不可能,具体设计方式imetEl Capitan和微软设备的思路即可。AMD后续应该会正式推出四路服务器,借此在高端内存内数据库和分析市场上与IBM和英特尔一较高下,目前看来AMD已经做好了前期准备。
为了应对高性能计算领域那些需要更高内存带宽的工作负载,微软Azure一直在其HBv3实例中使用64核“Milan-X”Epyc 7V73X CPU,在其HBv4实例中使用的则是96核“Genoa-X”9V84X CPU。这些是AMD为微软Azure打造的Milan-X与Genoa-X芯片的特殊变体。有些朋友可能还记得,这款X变体搭载有3D V-Cache,可将其L3缓存增加至三倍,并在带宽受限的应用程序上将性能提高约50%至80%。这种情况在高性能计算模拟和建模工作负载当中颇为常见。
在迁移到HBM内存之后,3D V-Cache的性能优势自然就大打折扣了。当然,部分原因也在于MI300C综合体在其X86核心块下还设有“Infinity Cache”,负责充当核心与外部HBM内存的超高速连接中介。我们之前曾经提到过,这里再次强调:只要价格足够便宜,所有芯片都应该采用3D V-Cache,借此在计算综合体上留出更多物理空间,同时缩小核心上的L3缓存区域。
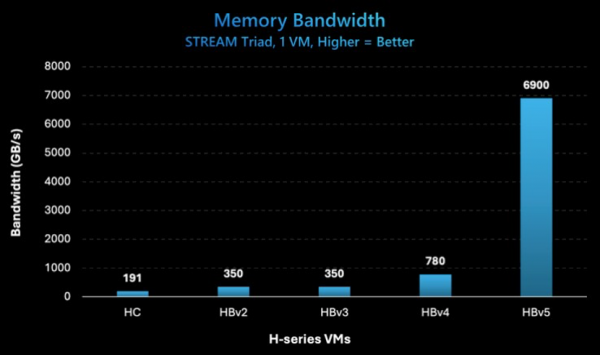
以下是微软制作的一张有趣图表,显示了迁移到MI300C的96核Genoa计算综合体在带宽方面的优势:
在本周SC24大会上,当我们与劳伦斯利弗莫尔国家实验室利弗莫尔计算公司的首席技术官Bronis de Supinski讨论起El Capitan系统时,他向我们证实称其CPU核心“获得的带宽超过了实际能够驱动的带宽”。这或许可以解释,为什么多数CPU并没有配备HBM内存。
如果我们以128 GB HBM3内存为每个MI300系列SH5插槽提供5.2 TB/秒的速度来聚会,那么在将四个内存插槽加起来的话,则四个SH5插槽将总计拥有20.8 TB/秒的带宽。多年以来,在我们研究过的大多数机器上,STREAM Traid基准测试得出的持续内存带宽一般为单个设备峰值理论带宽的80%。因此可以推断STREAM Traid的持续带宽为16.6 TB/秒。另外可以肯定的是,Infinity Fabric的NUMA特性也会带来自己的性能开销,只是很难准确加以量化。在CPU系统上,四路NUMA设置的性能肯定达不到4倍,一般为3.65倍。(在CPU之间链路数量增加一倍的双路插槽上,峰值理论值为2倍,而实际性能值一般为1.95倍。)
但在微软Azure通过其HBv5实例运行的STREAM Traid测试中,持续内存带宽达到6.9 TB/秒,远低于峰值聚合带宽的20.8 TB/秒。考虑到CPU核心可能无法像拥有大量并行核心的GPU那样驱动高带宽,也许有必要降低HBM内存子系统的速率以匹配CPU的性能特征。这是一种奇怪的现象,我们已经呼吁AMD和微软就STREAM Traid结果做出解释,特别是其为什么实际测试数值只有我们根据NUMA开销及过往独立设备上STREAM测试经验得出的预期值的1/2.2。
话虽如此,四路服务器的6.9 TB/秒成绩仍远远超过了Azure用于提高以往存在内存带宽瓶颈的HPC应用场景下其他双插槽服务器。HBv5实例能够将512 GB系统总HBM3内存当中的400 GB到450 GB,提供给高性能计算应用程序使用。如果取区间的最高值,则相当于每核心3.5 GB,这比Sapphire Rapids HBM配置下的每核心1 GB左右要大得多。Azure上HBv5实例每核心最高可以配置为9 GB内存,因为每核心对应的内存容量允许用户灵活设定。在机箱上的总计384个核心上,有352个可供实例上运行的应用程序使用。HBv5实例中共分配了62 GB到112 GB的HBM3内存加32个核心作为运行开销。(令人惊奇的是,为什么微软的虚拟机管理程序及其他开销没有像亚马逊云科技使用的「Nitro」NIC那样将负载移交给DPU,事实上谷歌也在尝试使用「Mount Evans」NIC达成同样的效果。)
HBv5实例还禁用了同时多线程(SMT)以提高性能,意味着这也是个单租户实例。该实例配备一个800 Gb/秒的Quantum 2 InfiniBand端口,该端口又被划分成四个虚拟200 Gb/秒端口,对应每插槽一个。这些InfiniBand NIC负责将节点聚集起来以共享作业,并且使用Azure VMSS Flex(即虚拟机规模集),其中的“Flex”代表其非常灵活,因为它可以将虚拟机分布在区域或可用区的故障域之内。微软方面表示,其可以“将MPI工作负载扩展至数十万个由HBM内存驱动的CPU核心之上。”
这意味着微软已经在各区域当中部署了数千台四CPU服务器,因此才敢于做出这样的声明。该系统还具备基于以太网的Azure Boost网络接口卡,可为HBv5实例下的机器提供160 Gb/秒的网络连接。该机器配备14 TB的NVM-Express冷艳,能够以50 GB/秒的速度读取数据、并提供30 GB/秒的数据写入速度。
HBv5实例目前正处于预览阶段,尚不清楚正式上线时间。MI300C(也就是Epyc 9V64H)目前仅通过微软对外开放,显然是与微软密切合作开发而成。微软希望在Azure之上运行更多高性能计算代码。对于众多高性能计算客户来说 ,能够在无需移植代码的前提下通过CPU获得具备GPU级内存带宽的硬件,无疑将大大减轻从本地向云端迁移的运营负担。
话虽如此,但我们还是衷心期待OEM和ODM厂商也能拿到MI300C。也许到了MI355C和MI400C发布的时候,这一切都将成为现实。
好文章,需要你的鼓励


OpenAI在版权诉讼中疑因隐瞒证据遭遇重大危机
OpenAI在与多家新闻机构的版权诉讼中陷入困境。以《纽约时报》为首的原告指控OpenAI在长达两年时间里向法庭撒谎,刻意隐瞒其已对ChatGPT日志进行大规模搜索的事实。据悉,OpenAI实际上已拥有包含1000万和7800万条记录的日志样本,并曾用于研究版权内容过滤器,却对外声称无法进行此类搜索。原告据此提出制裁动议,要求法院追责。OpenAI则否认相关指控,坚称其立场基于合理使用原则。

当AI学会“挑剔“:斯坦福与伯克利联手打造的智能验证框架,让AI自己检验自己的答案
斯坦福与UC伯克利提出LLM-as-a-Verifier框架,通过提取AI模型内部概率分布生成连续评分,在代码、机器人、医疗领域均达到最优性能,且无需额外训练。

外科医生远程操控人形机器人,完成全球首例活猪手术
美国加州大学圣地亚哥分校研究团队在《自然》期刊发表研究成果:外科医生通过远程操控宇树G1仿人机器人,成功完成两例活体猪胆囊切除手术,创下全球首例。与造价数十至数百万美元的达芬奇手术机器人相比,仿人机器人成本更低、体积更小,未来有望部署于农村、战地乃至太空等资源匮乏的医疗场景。但目前仍存在需频繁重新校准、机械臂活动范围受限等挑战。

字节跳动Seed团队发现:AI智能体学习新任务的速度,正以每三个月翻倍的惊人节奏增长
字节跳动Seed团队发现AI智能体在真实环境中学习的进步曲线精确遵循对数S形规律,R?达0.998,且前沿模型的学习速度每三个月翻倍。
2024
11/26
10:12
分享
点赞

OpenAI在版权诉讼中疑因隐瞒证据遭遇重大危机
外科医生远程操控人形机器人,完成全球首例活猪手术
OpenAI发布ChatGPT Work:AI助手可连续工作数小时
欧盟向Meta施压:关闭自动播放和无限滚动,否则面临巨额罚款
世界模型的潜力与局限:它真的能模拟一切吗?
苹果起诉OpenAI:前员工利用系统漏洞窃取商业机密
如何利用开源AI智能体实现工作流程自动化
Cloudzy 云服务评测:VPS 性能与体验全面解析
这款PCIe插卡内置38核至强处理器与64GB内存,堪称完整服务器
是否该为企业招募数字员工?AI 智能体团队搭建全指南
AI赋能自主机器人:从工厂走向家庭的未来图景
数据中心能源需求威胁特朗普"美国制造"计划
