
“AI驱动专业视听新生态,为亚太市场带来更多机遇”北京InfoComm China 2025盛大开幕
亚太领航专业视听及集成体验商贸盛会——北京InfoComm China 2025今天在北京国家会议中心盛大开幕,为全球视听行业人士、创新者和垂直行业用户提供一个重要的平台供相聚交流,共探新机遇。
本届北京InfoComm China 以 “数字未来 中国先行” 为主题,4月16 -18日为期三天云集全球 400家顶尖视听科技品牌,展示领先音视频技术及覆盖政企、教育、文旅、广电、教育等行业的创新解决方案,赋能加速千行百业数字化转型。

精彩开幕,行业精英齐赴盛会
北京InfoComm China 2025以精彩的开幕典礼拉开帷幕。继开幕表演之后,主办单位InfoComm Asia高层致欢迎词,热忱欢迎来自全球各地的展商、观众和合作伙伴共襄盛举。上海人工智能技术协会首席顾问尹智带来激情洋溢的开幕主题演讲——AI大模型的产业赋能应用落地之路,把脉行业发展。
作为亚太领航的专业视听及集成体验商贸展,北京InfoComm China 2025聚焦 AI+专业视听,升级高峰会议和特别活动,搭建行业深度交流平台。InfoCommAsia执行董事高浣勤女士表示:“北京InfoComm China 2025成功举办是一个重要的里程碑,不仅标志着在AI浪潮下视听行业持续发展的光明前景,更再次印证了我们向全球行业伙伴提供始终如一的卓越商贸体验的坚定承诺。让我们一起参与这场变革性盛会,共同见证它促进行业增长、协作和无限创新。”
突破性技术云集,多款“AI x视听”黑科技亮相
展会首日各个展馆人流如潮,400家全球品牌携带近500件新品首发,超100件亚洲首秀的创新产品与技术亮相。
AI是今年展会亮点,现场集中展示 AI 与视听技术深度融合创新技术,涵盖智能会议、虚拟制作、超高清商显、AR/VR、增强现实、全息互动、沉浸式光影、AIGC 内容生成、智能音视频集成等前沿领域。



沉浸式互动体验,解锁行业新场景
AI正赋予视听设备“感知、自主决策、交互”的能力,推动行业从“硬件应用”向“智慧体验”升级焕新。在北京InfoComm China现场,智慧文旅、智慧办公、智慧广电、智慧教育等场景以超强沉浸式互动体验成为热点,观众纷纷表示现场展示的各个垂直行业的创新解决方案,为他们探索业务发展打开新思路。

“AI技术应用专区”等两大全新展区备受欢迎
展馆P 特设“AI技术应用专区”和“新秀展区”,聚焦AI 和创新领域的技术创新。在AI技术应用专区,巨量引擎、百度文心大模型及飞桨、上海钒敉、IDMA、心影随形、瀚皓科技、WeShop Al、无界创羿、梦野追逐等AI技术企业集中展示,聚焦AI + 视听落地场景。并配套AI技术应用专区推介会,探讨生成式AI、计算机视觉等技术如何重塑视听产业生态,吸引众多观众前往探索。

超80场峰会及特别活动精英云集
北京InfoComm China高峰会议联合NVIDIA、invidis consulting、Themed Entertainment Association (TEA)、中关村海外科技园、北京服装学院、迪显咨询等海内外知名机构,演讲嘉宾来自NVIDIA、阿里云、字节跳动、舒尔、小鸟科技、TCL等近100位全球行业领袖、技术专家和创新者,带来最前沿的见解和实践经验。
特别活动是今年展会的重磅亮点之一,午餐交流会、业界精英欢迎酒会及观众导览团等多个活动今天成功举办。现场还有近100场富有洞见的产品演示/新品发布会,让参观者深度了解最新技术。
第二天(4月17日)精彩峰会&活动预告:
- NVIDIA 专场论坛:AI 重塑媒体格局:全新技术引领传播变革
- “智”播未来–智慧广电和全媒体发展论坛
- InfoComm China文旅交流酒会(与TEA联合举办)
- 人工智能与教育未来:创新研究与实践探索论坛
- 专业视听技术座谈 - 专业视听技术座谈
- 智慧办公
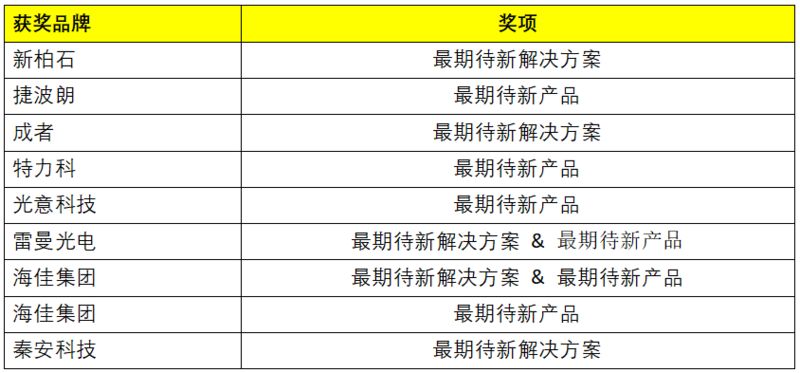
北京InfoComm China今年推出两大展商评选活动,由观众票选出最期待的新品和新解决方案,推动行业人士积极参与塑造行业互动。
获奖名单揭晓:
好文章,需要你的鼓励


Glean年收入突破3亿美元,削减AI成本成核心卖点
企业AI搜索公司Glean宣布年度经常性收入(ARR)达3亿美元,较15个月前的1亿美元增长三倍。尽管谷歌、微软、OpenAI等科技巨头纷纷入局企业AI搜索市场,Glean凭借"上下文图谱"技术深度理解企业业务需求,并帮助客户显著降低AI计算成本。该公司提供按用量计费和混合定价两种模式,客户涵盖Databricks、Reddit、Pinterest及三星等企业。Glean上轮融资后估值达72亿美元。

香港中文大学与MiniMax联手破解AI图像描述的“说多错多、说少漏多“困局
香港中文大学与MiniMax提出ClaimDiff-RL框架,将图像描述的AI训练从整体打分升级为逐条核查,有效解决了传统方式导致AI"少说保平安"的问题,同时在多项基准测试上超越Gemini-3-Pro-Preview。

蓝色起源“新格伦“火箭在佛罗里达测试中发生爆炸
杰夫·贝索斯旗下的蓝色起源公司在佛罗里达卡纳维拉尔角进行静态点火测试时,新格伦重型火箭发生爆炸。这是美国历史上最大规模的火箭爆炸之一,也是蓝色起源公司遭遇的最严重失败。所有人员安全,但该事故可能导致新格伦火箭项目长期暂停。此前该火箭已成功完成三次发射,并实现了助推器回收和重复使用。

NTU、HKU等多所顶校联手,让AI同时“多角度看片“——视频理解的并行探针革命
ParaVT是一个由南洋理工等多校联合提出的并行视频工具调用框架,通过让AI同时分析多段视频并引入PARA-GRPO算法解决训练中的格式崩溃与工具跳过问题,在六项长视频理解测试中平均提升约7.9%。
2025
04/16
19:21
分享
点赞

Glean年收入突破3亿美元,削减AI成本成核心卖点
蓝色起源"新格伦"火箭在佛罗里达测试中发生爆炸
智能体AI正在重塑企业架构与Token经济学
堪培拉理工学院如何借助技术革新重塑课堂教学体验
Gemma 4携手Arm:优化端侧AI,加速移动应用体验
制药公司与初创企业如何携手推动AI落地
《星球大战》导演盛赞生成式AI:电影制作的革命性工具
Salesforce借助Informatica布局企业级无头数据管理架构
几乎所有M5 MacBook Air配置现在都降价近200美元
大模型评测风向变了,Testin云测如何构建企业级AI质量标尺?
因民事养老金管理失误,英国政府拒绝向Capita授予5.63亿英镑合同
YouTube提升AI生成视频标签的显示效果
中国AIGC产业峰会在京顺利举办!20余位科技巨头解码AI产业落地密码
向左走、向右走:微软创想未来峰会解码企业AI转型之路
英特尔技术专家解读:MLPerf如何推动AI发展
你的AI正在"裸奔"?Precision AI就是那道固若金汤的防线
Writer 推出 "AI HQ" 平台,以 AI 代理重塑企业工作模式
MediaTek举办天玑开发者大会MDDC 2025,联合产业伙伴加速智能体AI体验普及和发展
HPE ProLiant Gen12正式发布,打造极致可靠、能效优化、智能自驱的新一代计算平台
微软创想未来峰会:智能体世界,从这里启程!
新一代端侧AI生产力工具 雕琢三重“开发自由”的“辩证法”
开源如何成为企业AI的“加速引擎”?
