
基于深度迁移学习的多语种NLP技术原理和实践
全球存在着几千种语言,这就对NLP研究者带来了巨大的难题,因为在一个语种上训练的模型往往在另外一个语种上完全无效,而且目前的NLP研究以英语为主,很多其他语种上面临着标注语料严重不足的困境。在跨语种NLP研究方面,业界已经做了不少研究,比较有代表性的有polyglot、以及近年来比较火的基于深度迁移学习的Multilingual BERT、XLM、XLMR等。
一、Polyglot介绍
Polyglot虽然能实现多语种的多个NLP任务,但是在实际应用中的效果并不理想,原因可能有以下几个方面:
a. Polyglot是通过对多个单语种的数据分别进行对应任务的学习,并不支持跨语种的NLP任务;
b. Polyglot是通过Wikipedia链接结构和Freebase属性来生成一些NLP任务的标注数据,可能存在生成的标注数据质量不高的问题;
c. Polyglot在一些NLP任务中使用的模型是浅层的神经网络,有进一步的提升空间。
BERT抛弃了传统的LSTM,采用特征抽取能力更强的Transformer作为编码器,并通过MLM(Masked Language Model, 遮掩语言模型)和NSP(Next-Sentence Predict)两个预训练任务,在海量数据上进行学习,相较于普通的语言模型,能够学习到更好的文本表示。BERT采用pre-train+fine-tuning的方式,对于一个具体NLP任务,只需对BERT预训练阶段学习到的文本表示进行 fine-tuning就能达state-of-the-art的效果。
2.1 Transformer
Transformer模型是2018年5月提出的一种新的架构,可以替代传统RNN和CNN,用来实现机器翻译。无论是RNN还是CNN,在处理NLP任务时都有缺陷。CNN是其先天的卷积操作不太适合处理序列化的文本,RNN是不支持并行化计算,很容易超出内存限制。下图是transformer模型的结构,分成左边encoder和右边的decoder,相较于常见的基于RNN+attention的encoder-decoder之间的attention,还多出encoder和decoder内部的self-attention。每个attention都有multi-head特征,multi-head attention将一个词的vector切分成h个维度,可以从不同的维度学到不同的特征,相较于全体空间放到一起更加合理。最后,通过position encoding加入没考虑过的位置信息。

BERT中使用transformer的encoder部分作为编码器,base版和large版分别使用了12层和24层的transformer encoder。
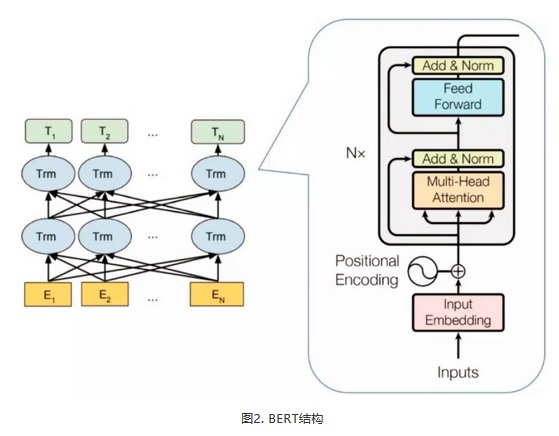
2.2 MLM
在BERT中,提出了一种叫做MLM的真正的双向语言模型。不像传统语言模型那样给定已经出现过的词,去预测下一个词,只能学习单向特征,MLM是直接把整个句子的一部分词(随机选择)遮掩住(masked),然后让模型利用这些被遮住的词的上下文信息去预测这些被遮住的词。遮掩方法为:有80%的概率用“[mask]”标记来替换,有10%的概率用随机采样的一个单词来替换,有10%的概率不做替换。
2.3 NSP
BERT另外一个创新是在双向语言模型的基础上增加了一个句子级别的连续性预测任务。这个任务的目标是预测两个句子是否是连续的文本,在训练的时候,输入模型的第二个片段会以50%的概率从全部文本中随机选取,剩下50%的概率选取第一个片段的后续的文本。考虑到很多NLP任务是句子关系判断任务,单词预测粒度的训练到不了句子关系这个层级,增加这个任务有助于下游句子关系判断任务。
Multilingual BERT即多语言版本的BERT,其训练数据选择的语言是维基百科数量最多的前100种语言。每种语言(不包括用户和talk页面)的整个Wikipedia转储都用作每种语言的训练数据。但是不同语言的数据量大小变化很大,经过上千个epoch的迭代后模型可能会在低资源语种上出现过拟合。为了解决这个问题,采取在创建预训练数据时对数据进行了指数平滑加权的方式,对高资源语言(如英语)将进行欠采样,而低资源语言(如冰岛语)进行过采样。
Multilingual BERT采取wordpiece的分词方式,共形成了110k的多语种词汇表,不同语种的词语数量同样采取了类似于训练数据的采样方式。对于中文、日文这样的字符之间没有空格的数据,采取在字符之间添加空格的方式之后进行wordpiece分词。
在XNLI数据集(MultiNLI的一个版本,在该版本中,开发集和测试集由翻译人员翻译成15种语言,而训练集的翻译由机器翻译进行)上Multilingual BERT达到了SOTA的效果。
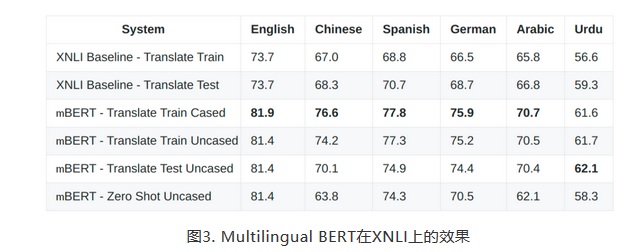
上面实验结果的前两行是来自XNLI论文的基线,后面四行是使用Multilingual BERT得到的结果。mBERT-Translate Train是指将训练集从英语翻译成其它语种,所以训练和测试都是用其它语种上进行的。mBERT-Translate Test是指XNLI测试集从其它语种翻译成英语,所以训练和测试都是用英语进行的。Zero Shot是指对mBERT通过英语数据集进行微调,然后在其它语种的数据集中进行测试,整个过程中不涉及到翻译。
XLM是Facebook提出的基于BERT进行优化的跨语言模型。尽管Multilingual BERT在超过100种语言上进行预训练,但它的模型本身并没有针对多语种进行过多优化,大多数词汇没有在不同语种间共享,因此能学到的跨语种知识比较有限。XLM在以下几点对Multilingual BERT进行了优化:
a. XLM的每个训练样本包含了来源于不同语种但意思相同的两个句子,而BERT中一条样本仅来自同一语言。BERT的目标是预测被masked的token,而XLM模型中可以用一个语言的上下文信息去预测另一个语言被masked的token。
b. 模型也接受语言ID和不同语言token的顺序信息,也就是位置编码。这些新的元数据能帮模型学习到不同语言的token间关系。
XLM中这种升级版的MLM模型被称作TLM(Translation Language Model, 翻译语言模型)。XLM在预训练时同时训练了MLM和TLM,并且在两者之间进行交替训练,这种训练方式能够更好的学习到不同语种的token之间的关联关系。在跨语种分类任务(XNLI)上XLM比其他模型取得了更好的效果,并且显著提升了有监督和无监督的机器翻译效果。
XLMR(XLM-RoBERTa)同是Facebook的研究成果,它融合了更多的语种更大的数据量(包括缺乏标签的的低资源语言和未标记的数据集),改进了以前的多语言方法Multilingual BERT,进一步提升了跨语言理解的性能。同BERT一样,XLMR使用transformer作为编码器,预训练任务为MLM。XLMR主要的优化点有三个:
a. 在XLM和RoBERTa中使用的跨语言方法的基础上,增加了语言数量和训练集的规模,用超过2TB的已经过处理的CommonCrawl 数据以自我监督的方式训练跨语言表示。这包括为低资源语言生成新的未标记语料库,并将用于这些语言的训练数据量扩大两个数量级。下图是用于XLM的Wiki语料库和用于XLMR的CommonCrawl语料库中出现的88种语言的数据量,可以看到CommonCrawl数据量更大,尤其是对于低资源语种。

b. 在fine-tuning阶段,利用多语言模型的能力来使用多种语言的标记数据,以改进下游任务的性能。使得模型能够在跨语言基准测试中获得state-of-the-art的结果。
c. 使用跨语言迁移来将模型扩展到更多的语言时限制了模型理解每种语言的能力,XLMR调整了模型的参数以抵消这种缺陷。XLMR的参数更改包括在训练和词汇构建过程中对低资源语言进行上采样,生成更大的共享词汇表,以及将整体模型容量增加到5.5亿参数。
XLMR在多个跨语言理解基准测试中取得了SOTA的效果,相较于Multilingual BERT,在XNLI数据集上的平均准确率提高了13.8%,在MLQA数据集上的平均F1得分提高了12.3%,在NER数据集上的平均F1得分提高了2.1%。XLMR在低资源语种上的提升更为明显,相对于XLM,在XNLI数据集上,斯瓦希里语提升了11.8%,乌尔都语提升了9.2%。
先明确两个概念,单语种任务:训练集和测试集为相同语种,跨语种任务:训练集和测试集为不同语种。
6.1 主题分类任务上效果
|
模型 |
训练集(数据量) |
测试集(数据量) |
指标(F1) |
|
XLMR-base
|
英语(1w)
|
英语(1w) |
0.716 |
|
法语(1w) |
0.674 |
||
|
泰语(1w) |
0.648 |
||
|
mBERT-base
|
英语(1w)
|
英语(1w) |
0.700 |
|
法语(1w) |
0.627 |
||
|
泰语(1w) |
0.465 |
主题分类是判断一段文本是属于政治、军事等10个类别中哪一个。实验中分别使用XLMR和Multilingual BERT在1w的英语数据上进行训练,然后在英语、法语、泰语各1万的数据上进行测试。可以看到无论是单语种任务还是跨语种任务上,XLMR的效果都优于Multilingual BERT,跨语种任务上的优势更明显。
6.2 情感分类任务上的效果
|
模型 |
训练集(数据量) |
测试集(数据量) |
效果(F1) |
|
XLMR-base |
法语(9k) |
法语(1.5k) |
0.738 |
|
阿语(586) |
0.591 |
||
|
阿语(2.5k) |
阿语(586) |
0.726 |
|
|
法语(1.5k) |
0.425 |
||
|
mBERT-base |
法语(9k) |
法语(1.5k) |
0.758 |
|
阿语(586) |
0.496 |
||
|
阿语(2.5k) |
阿语(586) |
0.716 |
|
|
法语(1.5k) |
0.364 |
情感分类任务是判断一段文本所表达的情感是正面、负面或中立。实验中分别对XLMR和BERT做了单语种任务的对比和跨语种任务的对比,可以看到在单语种任务中BERT和XLMR的效果差别不明显,而在跨语种任务中XLMR明显优于Multilingual BERT。
6.3 NER任务上的效果
|
模型 |
训练集(数据量) |
测试集(数据量) |
指标(F1) |
|
XLMR-base |
法语(5w) |
法语(3.4w) |
0.897 |
|
阿语(4k) |
0.525 |
||
|
mBERT-base |
法语(5w) |
法语(3.4w) |
0.916 |
|
阿语(4k) |
0.568 |
NER任务是抽取一段文本中实体,实体包括人名、地名、机构名。在该实验中,XLMR表现一般,不管是单语种任务还是跨语种任务上,效果比Multilingual BERT要略差一些。
Multilingual BERT使用特征抽取能力更强的transformer作为编码器,通过MLM和NSP在超过100种语言上进行预训练,但它的模型本身并没有针对多语种进行过多优化。而XLM对Multilingual BERT进行了优化,主要是增加了TML预训练任务,使模型能学习到多语种token之间的关联关系。XLMR结合了XLM和RoBERTa的优势,采用了更大的训练集,并且对低资源语种进行了优化,在XNLI、NER CoNLL-2003、跨语种问答MLQA等任务上,效果均优于Multilingual BERT,尤其是在Swahili、Urdu等低资源语种上效果提升显著。
在百分点实际业务数据的测试中,目前已经在英语、法语、阿语等常规语种上进行测试,无论是单语种任务还是跨语种任务,整体来看XLMR的效果要优于Multilingual BERT。想要实现在一种语种上进行模型训练,然后直接在另外一种语种上进行预测这样的跨语种迁移,仍需要相关领域进一步深入的探索。
Google近期发布了一个用于测试模型跨语种性能的基准测试Xtreme,包括了对12种语言家族的40种语言进行句子分类、句子检索、问答等9项任务。在Xtreme的实验中,先进的多语言模型如XLMR在大多数现有的英语任务中已达到或接近人类的水平,但在其它语言尤其是非拉丁语言的表现上仍然存在巨大差距。这也表明,跨语言迁移的研究潜力很大。不过随着Xtreme的发布,跨语种NLP的研究肯定也会加速,一些激动人心的模型也会不断出现,让我们共同期待。
来源:业界供稿
好文章,需要你的鼓励



明尼苏达大学最新研究颠覆认知:训练AI大模型,只需动其中一层就够了?
这项来自明尼苏达大学等机构的研究发现,大语言模型在强化学习后训练中,只需训练中间少数几层即可匹配甚至超越全参数训练效果,且这一规律跨模型、跨任务高度稳定,为更高效的AI训练策略提供了新思路。


台湾大学与NVIDIA揭秘:你的声音正在悄悄改变AI对你的判断
本文介绍VIBE框架,一套通过开放式任务评估大型音频语言模型声音诱发偏见的系统,测试12个模型后发现每个模型均存在显著性别或口音偏见。
2020
06/29
16:29
分享
点赞

NVIDIA Cosmos 推动物理 AI 前沿发展
PPIO亮相WAIC 2026:发布智能模型网关,打造面向Agent时代的智能Token工厂
端侧感知、私有闭环、量子协同, NVIDIA全栈异构计算范式“接管”实体产业底座
边缘智算筑基、全栈软硬协同,研华科技将AI带进产业闭环
千问AI眼镜将升级为智能体眼镜:能灵活调用Skill和Agent,能全天候感知
对话Moonix郭于晨:先让用户戴上“眼镜”,再让“AI”记录世界
亮相WAIC 2026,临床实证赋能康养升级 无芯科技定义AI疗愈新范式
生态覆盖持续扩散,一文看懂各行业企业鸿蒙化转型进度
WAIC亮出集群协作真功夫,优艾智合领跑工业具身智能规模化
脑部植入物助瘫痪男子重获进食与饮水能力
能源公司IPO融资创21世纪新高,押注AI基础设施热潮
Apple Intelligence获中国监管批准,携手阿里巴巴与百度正式进入中国市场
最热门的 AI 模型:它们的功能和使用方法
这款古怪的 AI 智能手机可以创建你的数字分身
Faireez 获 750 万美元融资,为租赁市场提供 AI 驱动的酒店式管家服务
Broadcom 大获全胜:70% 大型 VMware 客户购买其最全面解决方案
Peer 获得1050万美元元宇宙引擎投资,推出3D个人星球功能
获 3000 万美元融资,Crogl 发布面向安全分析师的全新 AI "钢铁侠战衣"
Turing 获得 1.11 亿美元融资,估值达到 22 亿美元,为 OpenAI 等大语言模型公司提供关键代码支持
Tavus 推出系列 AI 模型,实现实时人脸交互技术突破
Welevel 获得 570 万美元融资,革新程序化游戏开发
AI 驱动的卓越运营:企业如何通过人人可及的流程智能提升成功
