
IBM有望在2026年前实现量子纠错
噪音是量子计算目前面临的最大挑战,也是实际应用中的限制所在。IBM正致力于在未来几年内应用各类量子错误管理方法,减少噪音、实现真正的量子纠错(QEC)。
要具体了解纠错方法,我们需要先知晓噪音的负面影响。量子比特是量子计算机中的基础信息单位,一个量子比特能够保持其量子状态的时间越长,所能执行的计算操作就越多。遗憾的是,量子比特对于环境噪音非常敏感,而这种噪音可能来自量子计算机的电控设备、布线、低温系统、其他量子比特、热量、甚至是宇宙微波辐射等外部因素。噪音会导致量子比特的量子态崩溃(即「退相干」),进而引发错误。如果未能及时纠错,问题可能级联成大量错误并破坏整个计算过程。
这种噪音源自原子层面,虽然无法完全消除,但却可以控制。
量子霸权与噪音
尽管媒体大肆宣传,但目前还没有确凿证据能表明现有量子计算机比经典超级计算机更强大。当然,量子计算机的确掌握着均可辩驳的优势。大多数专家相信,量子计算展示出超越传统超级计算机的优越性只是个时间问题。届时,量子计算将实现我们常说的“量子霸权”。
IBM将量子霸权定义为,量子算法在实际案例中的运行时间相较于最佳经典算法实现了显著改进。蓝色巨人在博文中进一步指出,证明量子优势所需的算法必须包含有效的量子电路表示,且不可存在能够有效模拟这些量子电路的经典算法。
但问题在于:要让量子计算机实现量子霸权,除了提高量子比特相干性、门保真度和电路执行速度以外,还必须显著增加计算量子比特数。可量子比特数的增加也会同步提升噪音和量子比特出错的几率。如果无法有效管理噪音和量子比特错误,量子计算就没有长期发展可言。
尽管经典计算机和某些内存硬件中也有纠错机制的存在,但同样的技术无法直接套用到量子计算机当中,这是因为量子力学定律阻绝了克隆未知量子态的可能性。
事实上,量子纠错(QEC)是个复杂的工程与物理问题。尽管量子纠错非常重要,而且经历了多年的探索与发展,但其正确方向仍然难以捉摸。在找到可行的完全纠错方法之前,IBM希望能先找到其他方案过渡一下。
量子错误管理
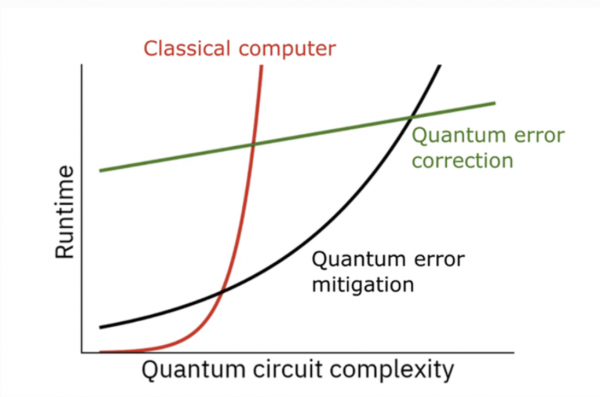
在量子纠错真正实现之前,只能先用量子错误缓解术先应付一阵。
在上图中,IBM将错误缓解量子电路的指数缩放与经典计算机的指数缩放进行了比较。其中的交叉点,就是量子错误缓解与经典解决方案达成等效的节点。
IBM在纠错研究方面拥有悠久的历史,最早可以追溯到David DiVincenzo在1996年时开展的调查。2015年,IBM开发出首个检测量子比特翻转与相位翻转错误的系统。如今,随着量子纠错的重要性广为人知,几乎每家企业、每个学术性量子计算项目都在开展某种形式的纠错研究。
IBM目前通过三种方法来研究量子错误管理,分别为:错误抑制、错误缓解和错误纠正。这里我们暂时不讨论错误纠正,只聊聊前两种方法。
错误抑制是最早、也是最基本的错误处理方法之一。它通常会修改电路,使用能量脉冲使量子比特保持更长时间的量子态,或者将脉冲引导至闲置量子比特以消除由相邻量子比特引起的负面影响。后一种类型的错误抑制,又被称为动态解耦。
IBM认为,错误缓解才是弥合当前硬件问题与未来高容错量子计算机间鸿沟的最佳方法。错误缓解的目标,就是用“曲线救国”的方式早日实现量子霸权。
多年以来,IBM从未放缓过对错误缓解研究的重视。通过这项工作,IBM开发出多种错误缓解方法,包括概率错误消除(PEC)和零噪音推断(ZNE)。
- PEC的原理很像是降噪耳机,系统会提取并分析其中的噪音,之后再混合原始噪音信号以将其抵消。PEC的一大特点在于,其并不像在音频噪音消除算法中那样只使用单一样本,而是通过一组电路计算其平均值。
- ZNE通过在不同噪音水平下运行量子程序来降低量子电路中的噪音,之后用推理计算确定零噪音水平下的估计值。
有效的量子纠错能够消除几乎一切与噪音相关的错误。值得注意的是,随着代码体量的增加,QEC需要抑制的错误也呈指数级增长。对于任何指定的代码规模,错误将始终存在。为了获得最佳结果,重要的是选择特定的代码大小来抑制错误,使其刚好适合目标应用。
但在QEC成为现实之前,量子错误缓解似乎是我们能够指望的最快量子霸权实现途径。
“傻瓜式”错误缓解技术
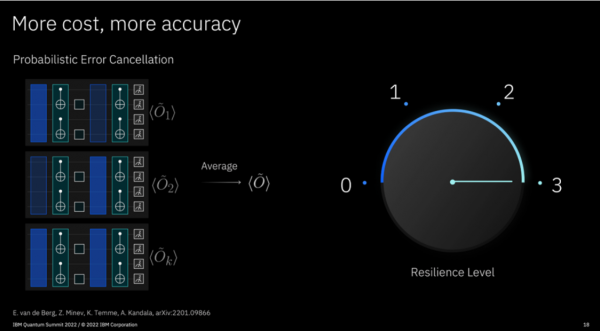
IBM最近宣布将错误抑制和错误缓解集成到了Qiskit Runtime的Sampler和Estimator当中。作为测试版功能,其允许用户牺牲速度来换取错误减少。IBM发布的路线图预计,这些功能的最终版本将在2025年面世。
错误缓解技术会在编译、执行和经典的后处理环节上带来一定开销,具体开销大小取决于所使用的错误缓解类型。IBM为其原语引入了新的简化选项,名为“弹性级别”,用户可以借此调整错误缓解的成本/准确性权衡。Sampler采样器和Estimator估算器将自动对优化级别1到3的电路应用动态解耦误差抑制。其中Resilience 0不提供任何错误缓解,Resilience 1为测量错误缓解,Resilience 2提供有偏错误缓解(通过ZNE),Resilience 3采用无偏估算器(通过PEC)。
错误缓解将全面登陆一切可通过云端访问的IBM系统。随着弹性级别的增加,相应成本也会上升。Resilience 3产生的错误量最少,但可能需要10万倍以上的计算时长。
IBM量子平台负责人Blake Johnson博士解释了蓝色巨人选取这种错误缓解服务的理由。
Johnson博士指出,“我们有一部分高级用户想要自行探索,他们不想让我们接触到具体电路。这样很好,我们也提供相应的方案。但另一方面,越来越多的用户其实想把量子计算机当成烤面包机那样使用。他们不需要明白底层是如何运作的,而只想按下按钮就得到正确的结果。因此,我们决定在不产生过量采样开销和额外成本的前提下,把某些选项设定成默认值。”
量子纠错
利益于整个量子计算社区展开的纠错研究,过去十年间QEC已经取得了重大进展。但即便如此,真正可先找解决方案恐怕也要等多年之后才会出现。
量子纠错的一大早期挑战,在于如何不破坏量子比特的量子态而测量其是否发生了错误。1995年,Peter Shor开发的突破性解决方案规避了这个问题。其系统并不会将量子态存储在单一量子比特内,而是将量子信息编码分布在九个物理量子比特构成的逻辑量子比特上。再配合监控系统的奇偶校验,即可在不直接测量(观察本身会破坏量子态)的前提下实现错误检测。
IBM目前正在研究其他几种量子纠错方法,包括一些类似于Shor码的方法。这类纠错码被称为量子低密度奇偶校验(qLDPC)。LDPC并不新鲜,已经在Wi-Fi和5G等经典应用中作为纠错机制。
根据IBM的介绍,qLDPC具有以下优点:
- 每个逻辑量子比特只需几个物理量子比特即可构成,远低于2-D表面码所需的几百个。
- 即使发生错误操作,也仅影响有限数量的量子比特。
量子纠错的研究方向和具体方法多种多样,本文无法一一涵盖。但毕竟有选择总是好的,如果想要实现容错量子计算机,就必须找到可靠的纠错方法。选择越多,其中存在正确答案的几率就越大。
IBM的量子路线图也反映出问题的复杂性,表明纠错解决方案可能要到2026年之后才会发展成熟。
总结
随着量子硬件的不断改进,IBM路线图中的量子错误缓解方法很可能让量子霸权提前来临。目前,错误缓解的运行时间正呈现出指数级增长,而且直接取决于量子比特数量和电路深度。但相信随着错误缓解方法、速度和量子比特保真度的同步改进,这样的开销将逐步减少。
IBM提出的目标是借错误缓解的思路,为错误纠正提供持续可行的开发路径。一旦实现了QEC,我们就能建立起包含数百万量子比特的容错超级量子计算机。这类机器能够模拟大型多体系统,优化复杂的供应链物流,创造新的药物和材料,并对复杂的金融活动进行建模和响应。
容错量子计算机的出现,标志着以量子为中心的科学研究新时代已经到来。在这种新能力的支持下,人类有望以更负责任的方式再次改变世界。
背景知识
- 尽管媒体一直大肆宣扬量子计算机的威力,但尚无证据能直接表明量子计算机相较于超级超级计算机拥有明显优势。
- Quantinuum最近发布了两项重要的QEC概念验证。其研究人员开发出一种逻辑纠缠电路,其保真度要高于对应的物理电路。研究人员还以完全容错的方式将两个逻辑量子比特门纠缠了起来。
- IBM宣称,其系统将引入动态电路以进一步缓解错误。动态电路有望在量子低密度奇偶校验(qLDPC)纠错码中发挥重要作用。
- 为实现量子霸权,IBM使用新近发布的433 Osprey量子比特处理器扩展了处理性能。Osprey的量子比特数量相当于现有127位Eagle处理器的3倍。
- 除了错误抑制和错误缓解计划外,IBM的量子路线图中还列出了实现量子霸权的其他几大里程碑:
- 2023年——随Condor处理器的发布进一步扩展规模,达到1121个量子比特。此外,全系统的速度和质量将进一步提升。
- 2024年——IBM着手集成并测试支持未来扩展的关键技术,例如经典并行化、耦合器、多芯片量子处理器和量子并行化。
- 2025年——补齐量子霸权目标的最后几块拼图,包括模块化量子硬件、新的控制电子元件和低温基础设施。
- 2026年——IBM将有能力将未来系统扩展至1万至10万量子比特。到那时,系统的速度和质量也将显著提高。量子错误缓解的成熟实施,将使得量子霸权成为可能。此外,量子纠错课题也将取得重大进展。
好文章,需要你的鼓励


Savi Security:用AI实时拦截AI诈骗电话与短信
Savi Security由Patrick和Ryan Coughlin兄弟创立,融资700万美元,并正式推出iOS和Android应用。该应用可实时筛查短信、语音邮件和来电,识别AI生成的诈骗内容。其核心功能是通话实时监控,用户可在可疑通话中邀请AI助手同步监听,分析行为特征。产品以家庭为单位收费,每月8美元,不限用户数量。FTC数据显示,2025年冒充诈骗造成损失高达35亿美元,是2020年的三倍。

香港中文大学(深圳)与字节跳动联手,造出能“自由调速“的语音大模型
香港中文大学(深圳)与字节跳动联合提出FlexiSLM,首个支持动态与可控帧率的语音大模型,在输入输出两端均实现自适应帧合并,6.25赫兹下推理速度提升一倍,语音对话质量超越同规模固定帧率模型。

Argo CD漏洞警示:GitOps基础设施应被视为零级核心资产
安全公司Synacktiv披露了Argo CD中一个未修复的高危漏洞,影响其repo-server组件的未认证gRPC端点。攻击者若能访问该端点及Redis数据库端口,可执行恶意命令、篡改部署数据,并在启用Auto Sync时自动推送恶意配置。由于Helm chart部署默认未启用网络策略保护,集群内任意受损Pod均可触发攻击。专家建议企业将Argo CD视为零级控制平面组件,实施严格的东西向流量隔离与特权访问管控。

中南大学团队打造“自我进化“的AI训练数据工厂:被丢弃的“废品“竟是最好的老师
这项研究提出DataEvolver框架,把被丢弃的"不合格训练图片"转化为改进数据收集策略的反馈,让AI文字图像生成训练数据的构建流程能自我进化,在相同数据量下显著提升文字渲染质量。
2022
12/08
16:18
分享
点赞

Argo CD漏洞警示:GitOps基础设施应被视为零级核心资产
AI投资拖累科技巨头气候承诺,碳排放持续攀升
Voltpost携手InCharge Energy,路灯电动车充电桩加速在美国扩张
Sonair发布全球首款获安全认证的3D超声波传感器
Niantic Spatial为Scaniverse新增USDZ导出功能,助力机器人仿真工作流
仿脑光传感器有望加速AI图像处理
Norm Ai融资1.2亿美元,估值达12亿美元,以AI智能体重塑法律服务
Bidbus获1500万美元融资,让经销商竞价收购你的二手车
AI法律创业公司Norm完成1.2亿美元C轮融资,跻身独角兽行列
征程赶超|WAIC 2026理论突破:以数理双向赋能为钥,开启AI范式革新新征程
征程赶超|WAIC 2026 Token经济:按下加速键,从技术计量到产业新范式
征程赶超|WAIC 2026科学智能:AI4S从“辅助计算”到“自主发现”,中国如何重塑全球科研版图?
