
OpenAI及DeepMind两团队令未来的AI机器更安全 原创
OpenAI和DeepMind的研究人员使用的新算法从人类反馈中学习,他们希望这样做能使人工智能更安全。
两家公司均为强化学习的专家,强化学习是机器学习的一个领域,其基本思想是,如果代理在特定的环境里采取正确的行动完成了任务就给予奖励。该目标是通过一种算法来指定的,代理经过程序后就会追逐奖励,例如游戏中的获胜点。
强化学习在训练机器如何玩如Doom或Pong等游戏或通过模拟驾驶自主驾驶汽车等案例中取得了成功。强化学习是探索代理行为的一个有效的方法,但如果硬编码算法错了或产生不良影响的话,这种方法可能也有危险。
arXiv上发表的一篇论文描述了一种有助于防止此类问题的新方法。首先,代理在其环境中执行随机动作。预测的奖励则是基于人类的判断,而且奖励被反馈到强化学习算法中,以改变代理的行为。
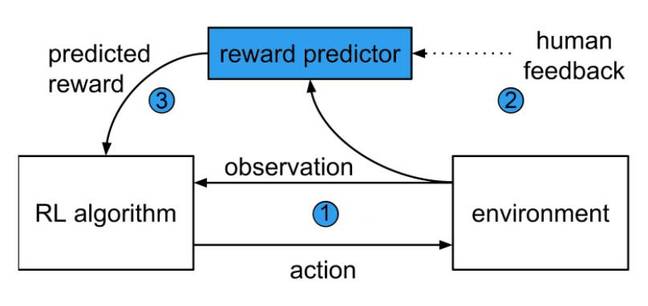
系统在人类指导下制定最佳行动及学习目标
研究人员将这种算法用于训练一个弯曲的灯柱往后仰。代理的两个视频然后再交给人观看,观看者选择哪一个的后仰动作更佳一些。
经过一段时间后,代理就逐渐学习了如何根据奖励函数最有效地解释人类的判断来学习目标。强化学习算法用于指导代理的行为,并可以持续在人类的批准下进行改进。
网上可找到相关的视频。(https://www.youtube.com/watch?v=oC7Cw3fu3gU)
人类评估者花掉的时间不足一个小时。但要完成做饭或发送电子邮件等更复杂的任务就会需要更多的人类反馈,从财务的角度来看则是昂贵的。
文章的作者之一达里奥·阿莫德(Dario Amodei)是OpenAI的一名研究人员,他表示,未来研究的重点会放在减少监督方面。
他告诉记者,“泛泛而言,名为半监督学习的技术在这一块可能有帮助。另一种可能性是提供更信息密集的反馈形式,如语言,或是让人类在屏幕上具体指出表示良好行为的部分。更多的信息密集反馈可能会让人类在更短的时间内更多地与算法进行沟通。“
上述研究人员在其他模拟机器人任务和Atari游戏里测试了他们的算法,结果显示机器有时可以实现超人式的性能。但这在很大程度上取决于人类评估者的判断。
OpenAI在一篇博文里表示,“我们算法的性能只能和人类评估者对于什么是正确行为的直觉一样好,所以,如果人类对一个任务没有很好的把握,那他们可能提供不了太多有用的反馈。”
阿莫德表示,目前的结果仅局限于非常简单的环境。但这种方法大有可能对有些很难学习的任务有用,这些任务的奖励功能很难量化,例如驾驶、组织事件、写作或技术支持的提供。
好文章,需要你的鼓励


马斯克:SpaceX愿景是攀登卡尔达肖夫指数,我们必须去太空
刚刚,确实是刚刚。2026 年 6 月 12 日,SpaceX 以每股 135 美元在纳斯达克挂牌(SPCX),收于 160.95 美元,涨 19%,市值突破 2 万亿美元,史上最大 IPO。

西交利物浦大学联手香港中文大学:用“信息几何“给AI安全装上“地震仪“
这项研究提出用费舍尔信息矩阵谱范数衡量深度神经网络的内在脆弱性,无需发动对抗攻击即可评估模型稳健性,并推导了VGG、ResNet、DenseNet和Transformer的理论排名。

Andrew Yang:降低生活成本是下一个创业大机遇
前美国总统候选人杨安泽认为,AI浪潮将压缩薪资、取代就业,由此催生出一个新的创业机会——帮助普通人降低生活成本。他以马克·库班的平价药品公司为灵感,于去年创办了移动虚拟运营商Noble Mobile,以低价提供手机服务并与用户共享利润。杨安泽表示,住房、教育、食品、交通等基本生活领域都存在巨大机会,市场可以在政策失灵时发挥再分配作用,鼓励创业者突破AI泡沫思维,关注真实的民生问题。

南加州大学的AI研究团队如何让“模仿学习“变得更聪明——当AI导师的指导方式决定了学生能走多远
南加州大学提出DistIL方法,通过前向交叉熵目标和完整序列级梯度,解决AI自蒸馏训练中方向偏差与局部信用分配问题,在科学推理、编程和难题数学上均超越现有基线。
2017
06/14
17:00
分享
点赞

Andrew Yang:降低生活成本是下一个创业大机遇
PeopleSoft零日漏洞波及数百机构,数十GB数据遭窃
Broadcom强化Spring安全体系,全力防御AI驱动的网络攻击
Apple Silicon大幅提升Mac整体拥有成本优势
iOS 27 新增多语言键盘支持及输入体验全面升级
Protocol Buffers模式漏洞曝光:六大安全缺陷可导致远程代码执行
Gemini macOS 应用迎来图标更新及截图快捷键新功能
苹果年内将推出四款全新Mac机型,抢先了解详情
谷歌起诉涉嫌利用AI发送诈骗短信的中国网络犯罪组织
Linux基金会成立Tokenomics基金会以应对AI Token成本管理挑战
Anthropic Fable 5悄然降级引发网络热议,安全限制究竟该如何拿捏?
五色全线史低!AirPods Max 2 登陆亚马逊最低价
