
浪潮KaiwuDB通过中国信通院“可信数据库”性能与稳定性评测
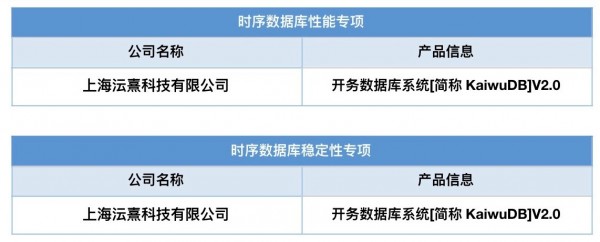
11月29日,中国信通院2023年下半年“可信数据库”评估评测结果正式发布,由浪潮KaiwuDB 研发的开务数据库系统KaiwuDB V2.0 达到信通院时序数据库性能、稳定性测试标准。至此,KaiwuDB 已完成时序数据库基础能力、性能、稳定性全项评测,能够满足海量时序数据存储、处理、应用等各类场景数据管理需求。
KaiwuDB 是浪潮创新研发的、业内首款分布式多模数据库系统。在拥有分布式数据库的强一致、高可用分布式架构、分布式水平扩展、高性能、企业级安全等特性的同时,兼备多模数据库的特性,可支持时序、结构化、半结构化和非结构化数据的存储和分析。其中,时序引擎针对物联网、工业互联网、车联网、智慧产业等场景中数据体量大、采样频率高、数据乱序到达、分析需求多、存储与运维成本高等问题设计并优化,以创新研发的“就地计算”技术为依托,拥有海量时序数据高吞吐写入、高性能大批量复杂查询、原生AI 支持等优势,可实现工业数据的高效实时处理、智能分析、统一运管及低成本运维,帮助用户降本增效、提升决策科学性。此外,KaiwuDB 数据库系统在突发故障、高负载、资源占满等测试情况下拥有较强的韧性和故障恢复能力,匹配用户对数据库高可用和连续性的要求。
目前,KaiwuDB 分布式多模数据库已在智能制造、能源风电、智慧矿山等多个项目中应用落地,并在时序数据写入查询性能、水平扩展能力、大数据分析、云边端一体化能力等方面展现极大优势。作为“可信数据库”的一员,浪潮KaiwuDB 将持续专注于产品性能提升,以高吞吐、高压缩、高可用的新一代数据库系统夯实物联网数字底座,助力企业伙伴数字化升级。
来源:业界供稿
好文章,需要你的鼓励


Claude Sonnet 5 发布:编码、推理与工具使用能力全面提升
Anthropic于6月30日发布Claude Sonnet 5,相较前代Claude Sonnet 4.6在编程、推理、工具使用及知识工作方面均有显著提升。该模型可自主制定计划、使用浏览器和终端等工具,达到数月前需更大更贵模型才能实现的水平。安全评估显示其不良行为率更低。Sonnet 5默认开启自适应思维,采用更新的分词器,性能接近Opus 4.8但价格更低,现已面向所有订阅计划开放。

复旦大学、上海交大联手攻克机器人“眼手协调“难题:让AI真正理解动作背后的物理世界
复旦大学联合多机构提出A2World框架,通过210万条真实机器人轨迹进行动作条件化预训练,将学到的物理动力学先验同时迁移到仿真模拟和策略控制两个方向,在LIBERO和真实机器人任务上均取得当前最优表现。

AI高速扩张正悄然考验电网承载极限
人工智能基础设施的快速扩张不仅带来总用电量激增,更在改变电网的运行特性。AI训练任务高度同步、计算密集,推理任务则分散且难以预测,两者均可在极短时间内造成电力需求骤变。数据中心的地理集中分布进一步加剧局部电网压力。现有监管框架多基于稳定工业负荷设计,难以适应这类新型需求。专家指出,电网规划需从关注总能耗转向关注需求波动性与同步效应。

同济大学研发的“地空协作机器人“:如何让无人车和无人机在黑暗隧道里默契配合?
同济大学研发的FLISP系统,让无人车与无人机在水电隧道中无需建图、仅靠激光雷达实时协作导航,规划延迟仅7毫秒,成功率100%。
2023
11/30
14:12
分享
点赞

AI高速扩张正悄然考验电网承载极限
福特对AI失望,重新雇用350名经验丰富的工程师
首批四家云服务商加入CISPE欧盟云主权认证计划
2026 Eurobike 展会:最值得关注的电动自行车与新奇产品盘点
联想Legion 7i Gen 10游戏本评测:颜值在线,性价比存疑
杀毒软件已不够用?全面了解现代网络安全防护
大语言模型助力机器人理解模糊指令并聚焦关键细节
MIT AI与社会论坛:探讨AI对就业、民主等领域的深远影响
麻省理工学院新芯片助力微型机器人穿越复杂环境
扎克伯格承认Meta智能体AI进展未达预期
Rust 1.96 正式发布:引入全新 Range 类型体系
AI驱动的内存危机:苹果的困境也是所有人的困境
