
浪潮KaiwuDB论文被数据库国际顶会ICDE2024录用
近日,浪潮KaiwuDB 与中国人民大学合作的论文 FOSS: A Self-Learned Doctor for Query Optimizer 被数据库领域顶会The 40th IEEE International Conference on Data Engineering (ICDE 2024) 录用。论文提出了具备自学习、自诊断能力的查询优化器 FOSS,推动了基于 AI 算法的学习型查询优化技术革新,其技术创新性获得国际顶会权威认可。浪潮KaiwuDB 高级研发工程师、人大信息学院博士孙路明为共同作者。

ICDE 是电气与电子工程师协会(IEEE)举办的旗舰会议,与 SIGMOD、VLDB 并称数据库三大顶会,也是中国计算机学会 ( CCF ) 推荐的 A 类国际会议,主要聚焦设计、构建、管理和评估高级数据密集型系统和应用等研究问题,在国际上享有盛誉并具有广泛的学术影响力。此次在荷兰召开的ICDE 2024大会,吸引到北京大学、清华大学、中国人民大学、浙江大学、MIT、斯坦福等高校及全球知名科技企业参会,共同探讨数据库、数据处理领域的先进技术问题。
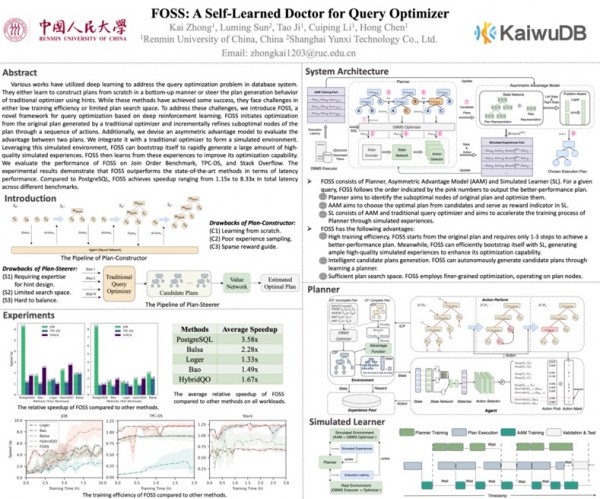
近年来,数据库研究人员提出了多个基于 AI 算法的学习型查询优化器,它们或者通过自下而上的方式从头学习构建查询计划,或者通过提示(Hint)引导或者限制传统优化器的执行计划生成过程。虽然这些方法取得了一些成功,但它们却面临训练效率低下、计划搜索空间有限等方面的挑战。
本篇论文提出了一种基于深度强化学习的查询优化新框架——FOSS。FOSS 的行为类似一个诊疗查询计划的医生,它从传统优化器生成的原始计划开始优化,发现其中的性能问题,并通过一系列优化动作逐步改进计划中的次优节点。与引导传统优化器行为的黑盒方法不同,FOSS 是一个白盒方法,通过优化传统查询优化器生成的计划,更好地利用专家优化知识。此外, FOSS 中还采用了不对称的收益模型来评估两个计划之间的性能差异。为了提高 FOSS 的训练效率,本文将 FOSS 与传统优化器集成以形成一个模拟环境。利用这个模拟环境,FOSS 可以自动快速生成大量高质量的模拟经验,然后从这些经验中学习以提高其优化能力。论文在 Join Order Benchmark, TPC-DS 和 Stack Overflow 等多组数据集和负载上评估了 FOSS 的性能,实验结果表明,FOSS 在模型收敛速度、查询优化效果上优于现有学习型查询优化器,与 PostgreSQL 默认查询优化器相比,更是获得了最高 8.33 倍的加速效果。通过引入该技术,数据库查询性能、响应时间及用户体验或将有效提升,适用于 OLAP、HTAP 等数据密集型场景的查询需求。
作为业内首款分布式、多模融合、支持原生AI 的数据库产品,KaiwuDB 长期致力于为 AIoT 等重点场景提供更丰富的数据运管能力和更卓越的数据库性能,力求不断在 SQL 优化、数据库自治等重点技术上实现突破。未来也将始终坚持以先进技术打磨产品,加速学术研究与产业应用融合,为中国数据库技术创新发展、数据处理效能提升等方面贡献新思路,为政企客户伙伴提供高性能、高可用、易运维的数据服务,助力产业数字化升级与应用创新。
来源:业界供稿
好文章,需要你的鼓励


OpenAI在版权诉讼中疑因隐瞒证据遭遇重大危机
OpenAI在与多家新闻机构的版权诉讼中陷入困境。以《纽约时报》为首的原告指控OpenAI在长达两年时间里向法庭撒谎,刻意隐瞒其已对ChatGPT日志进行大规模搜索的事实。据悉,OpenAI实际上已拥有包含1000万和7800万条记录的日志样本,并曾用于研究版权内容过滤器,却对外声称无法进行此类搜索。原告据此提出制裁动议,要求法院追责。OpenAI则否认相关指控,坚称其立场基于合理使用原则。

当AI学会“挑剔“:斯坦福与伯克利联手打造的智能验证框架,让AI自己检验自己的答案
斯坦福与UC伯克利提出LLM-as-a-Verifier框架,通过提取AI模型内部概率分布生成连续评分,在代码、机器人、医疗领域均达到最优性能,且无需额外训练。

外科医生远程操控人形机器人,完成全球首例活猪手术
美国加州大学圣地亚哥分校研究团队在《自然》期刊发表研究成果:外科医生通过远程操控宇树G1仿人机器人,成功完成两例活体猪胆囊切除手术,创下全球首例。与造价数十至数百万美元的达芬奇手术机器人相比,仿人机器人成本更低、体积更小,未来有望部署于农村、战地乃至太空等资源匮乏的医疗场景。但目前仍存在需频繁重新校准、机械臂活动范围受限等挑战。

字节跳动Seed团队发现:AI智能体学习新任务的速度,正以每三个月翻倍的惊人节奏增长
字节跳动Seed团队发现AI智能体在真实环境中学习的进步曲线精确遵循对数S形规律,R?达0.998,且前沿模型的学习速度每三个月翻倍。
2024
05/24
10:13
分享
点赞

OpenAI在版权诉讼中疑因隐瞒证据遭遇重大危机
外科医生远程操控人形机器人,完成全球首例活猪手术
OpenAI发布ChatGPT Work:AI助手可连续工作数小时
欧盟向Meta施压:关闭自动播放和无限滚动,否则面临巨额罚款
世界模型的潜力与局限:它真的能模拟一切吗?
苹果起诉OpenAI:前员工利用系统漏洞窃取商业机密
如何利用开源AI智能体实现工作流程自动化
Cloudzy 云服务评测:VPS 性能与体验全面解析
这款PCIe插卡内置38核至强处理器与64GB内存,堪称完整服务器
是否该为企业招募数字员工?AI 智能体团队搭建全指南
AI赋能自主机器人:从工厂走向家庭的未来图景
数据中心能源需求威胁特朗普"美国制造"计划
