ЙЁТ»ЙЁ
·ЦПнОДХВөҪОўРЕ
ЙЁТ»ЙЁ
№ШЧў№Щ·Ҫ№«ЦЪәЕ
ЦБ¶ҘН·Мх
ЎЎЎЎҫЭОТЛщЦӘЈ¬Web·юОсКЗЧоҝбөДјјКхЈ¬ө«ЛьЧоЦХ»бИГҙујТҫхөГіБГЖЎЈІ»ЦӘөАДъёРҫхИзәОЈ¬ГҝөұОТІОјУМЦВЫweb·юОсөДСЭҪІКұЈ¬ЧЬКЗМэөҪәЬ¶аЛхРҙЈ¬ИзRESTЎўXML/RPCЎўSOAPәНRSSЎЈИ»әуҫНҝӘКјҙтнпЈ¬ГОөҪУРёцөШ·ҪКчЙПіӨВъKrispy KremeМрГжҫнЎЈРСАҙКұЈ¬ОТИПК¶өҪКөјКЙПОТЧцБЛәЬ¶аweb·юОс№ӨЧчЈ¬ІўГ»НкИ«УГөҪДЗР©әБОЮТвТеөДұкЧјіМРтЎЈОТҝҙҙэweb·юОсөД·ҪКҪ·ЗіЈјтөҘЈ¬ЛьҫНКЗwebУҰУГіМРтөДұёУГҪУҝЪЈ¬ФКРнЖдЛыіМРтТФұаіМУпСФҝЙТФАнҪвөД·ҪКҪУлОТөДУҰУГіМРтНЁРЕЎЈИЛГЗНЁ№эHTMLУлУҰУГіМРтНЁРЕЈ¬УҰУГіМРтНЁ№эXMLЎўCSV»тЖдЛыұкЧјУлОТөДУҰУГіМРтНЁРЕЎЈ
ЎЎЎЎ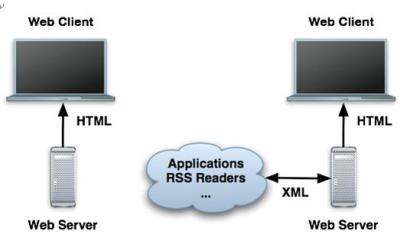
ЎЎЎЎ
ЎЎЎЎНј1ДЬёьәГөШҪвКНХвёцАнВЫЈә
ЎЎЎЎНј1. ҙ«НіөДwebУҰУГіМРтУлГжПт·юОсөДјЬ№№ЈЁSOAЈ©
ЎЎЎЎЧуІаОӘҙ«НіөДwebУҰУГіМРтЎЈ·юОсЖчНЁ№эHTMLУлwebҝН»§¶ЛНЁРЕЎЈёГ·юОсЖчҝЙТФКЗИОәОјјКхЈәJavaЎў.NETЎўRailsЎўPHPЎўPython»тColdFusionЎЈУТІаОӘПаН¬өДwebУҰУГіМРтЎЈө«КЗЛьіэБЛМṩHTMLЈ¬»№К№УГXMLНЁРЕЈ¬ТтҙЛҝЙТФУлЖдЛыУҰУГіМРт»тRSSФД¶БЖчЦ®АаөДЧЁУГ·юОсЖчҪ»БчЎЈ
ЎЎЎЎОТҫӯіЈМэөҪИЛГЗМёВЫНкИ«»щУЪ·юОсөДУҰУГ·юОсЖчЎЈХв¶ФУЪәу¶ЛјјКхАҙЛөҝЙДЬІ»ҙнЎЈө«КЗ¶ФУЪЖХНЁөДwebУҰУГіМРтЈ¬ДъЧЬКЗПЈНыЛьН¬КұЦ§іЦHTMLәНXMLҪУҝЪЎЈУөУРБҪЦЦҪУҝЪөДТ»ПоәГҙҰФЪУЪЈ¬ЛьЗҝЦЖДъҪ«ТөОсВЯјӯјҜЦРөҪТ»ёцО»ЦГЈЁҝЙДЬКЗТ»ёцЎ°ЦРјдІгЎұЈ©Ј¬ТтҙЛHTMLәНXMLҪУҝЪ¶јҝЙТФУлКэҫЭҝвНЁРЕІў»сөГПаН¬өДҪб№ыЎЈ
ЎЎЎЎФКРнwebУҰУГіМРтНЁ№эXMLУлЖдЛыіМРтНЁРЕөДјЫЦө¶ФДъАҙЛөҝЙДЬПФ¶шТЧјыЈ¬ө«КЗ¶ФОТАҙЛөІў·ЗИзҙЛЈ¬ЦБЙЩЧоіхКЗХвСщЎЈТтҙЛұҫОДҪІКцТ»ёцКҫАэЈ¬СЭКҫНЁ№эФЪУҰУГіМРтЦРЙиЦГXMLҪУҝЪҝЙТФКөПЦДДР©№ҰДЬЎЈКЧПИҪІКцјтөҘөДHTMLЗ°¶ЛЈ¬И»әуПФКҫИзәО№№ҪЁXMLҪУҝЪІўМнјУёчЦЦФД¶БЖчЈЁ°ьАЁAjaxЎўRSSәНAdobe FlexЈ©ЎЈ
ЎЎЎЎОДХВУҰУГіМРт
ЎЎЎЎКЧПИҪІКцөДІвКФУҰУГіМРтКЗКэҫЭҝвЦРУРТ»ёцОДХВБРұнөДіМРтЎЈЗеөҘ1ПФКҫБЛХвёцКэҫЭҝвЎЈ
ЎЎЎЎЗеөҘ 1. articles.sql
ЎЎЎЎDROP TABLE IF EXISTS articles;
ЎЎЎЎCREATE TABLE articles (
ЎЎЎЎid INTEGER NOT NULL AUTO_INCREMENT,
ЎЎЎЎtitle VARCHAR(255),
ЎЎЎЎauthor VARCHAR(255),
ЎЎЎЎdescription TEXT,
ЎЎЎЎPRIMARY KEY( id ) );
ЎЎЎЎINSERT INTO articles VALUES ( null,
ЎЎЎЎ'What I like about dogs', 'Megan Herrington',
ЎЎЎЎ'Everything that I love about dogs I learned in preschool' );
ЎЎЎЎINSERT INTO articles VALUES ( null,
ЎЎЎЎ'Making action movies', 'Jack Herrington',
ЎЎЎЎ'How to script, produce and direct Hong Kong action flicks' );
ЎЎЎЎINSERT INTO articles VALUES ( null,
ЎЎЎЎ'Super Paper Mario Tips', 'Lori Herrington',
ЎЎЎЎ'Everything you need to know to win at Paper Mario' );
ЎЎЎЎINSERT INTO articles VALUES ( null,
ЎЎЎЎ'Why I bark', 'Oso Herrington',
ЎЎЎЎ'' );
ЎЎЎЎёГіМРт·ЗіЈјтөҘЎЈЛь°ьә¬Т»ёцҙжҙўОДХВБРұнөДјтөҘұнёсЈ»ГҝЖӘОДХВ¶јУРұкМвЎўЧчХЯәНГиКцЎЈ
ЎЎЎЎЗеөҘ2ПФКҫҙЛұнёсөДПкПёHTMLЗ°¶ЛЎЈ
ЎЎЎЎЗеөҘ2. articles.php
ЎЎЎЎ
ЎЎЎЎ
ЎЎЎЎ
ЎЎЎЎ
require_once( "DB.php" );
$db =& DB::Connect( 'mysql://root@localhost/articles1', array() );
if (PEAR::isError($db)) { die($db->ЎЎЎЎrequire_once( "DB.php" );
ЎЎЎЎ$db =& DB::Connect( 'mysql://root@localhost/articles1', array() );
ЎЎЎЎif (PEAR::isError($db)) { die($db->getMessage()); }
ЎЎЎЎ$res = $db->query( "SELECT * FROM articles" );
ЎЎЎЎ$rows = array();
ЎЎЎЎwhile( $res->fetchInto($row, DB_FETCHMODE_ASSOC) ) {
ЎЎЎЎ>
ЎЎЎЎ
ЎЎЎЎ
ЎЎЎЎ0 ) { ?>
ЎЎЎЎ
ЎЎЎЎ
ЎЎЎЎ
ЎЎЎЎ
ЎЎЎЎ
ЎЎЎЎ
ЎЎЎЎИз№ыТ»ЗР№ӨЧчХэіЈІўЗТЙиЦГБЛҙЛКэҫЭҝвЈ¬ҫНДЬФЪдҜААЖчЦРөјәҪөҪҙЛТіГжКұПФКҫНј2ЛщКҫөДТіГжЎЈ
ЎЎЎЎ
ЎЎЎЎ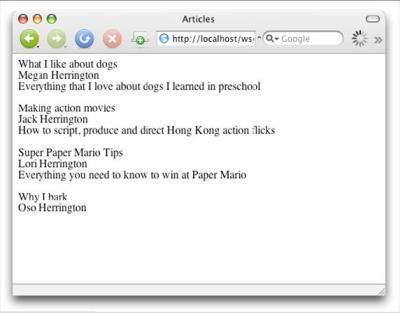
ЎЎЎЎ
ЎЎЎЎНј2. ОДХВТіГж
ЎЎЎЎҝҙөҪөДДЪИЭІўІ»¶аЈ¬ө«КЗОТПЈНыХвёцКҫАэҫЎБҝјтөҘЎЈЦчТӘКЗТтОӘәуГжөДДЪИЭІ»ИЭТЧҙҰАнЎЈ
ЎЎЎЎМṩXMLҪУҝЪөДТ»ёцЦчТӘФӯТтКЗИЛГЗІ»ұШұаРҙЗеөҘ3ЛщКҫөДҙъВлЎЈ
ЎЎЎЎЗеөҘ 3. fetch.rb
ЎЎЎЎrequire 'net/http'
ЎЎЎЎarticles = []
ЎЎЎЎNet::HTTP.start('localhost', 80) { |http|
ЎЎЎЎresponse = http.get('/ws/articles.php')
ЎЎЎЎbody = response.body
ЎЎЎЎbody.scan( /(
ЎЎЎЎtitle = item[0].scan( /
ЎЎЎЎauthor = item[0].scan( /
ЎЎЎЎdescription = item[0].scan( /
ЎЎЎЎtitle = title[0][0] if ( title[0].length >0 )
ЎЎЎЎauthor = author[0][0] if ( author[0].length >0 )
ЎЎЎЎdescription = ( description.length >0 ) ? description[0][0] : ''
ЎЎЎЎarticles.push( { :title => title,
ЎЎЎЎ:author => author, :description => description } )
ЎЎЎЎ}
ЎЎЎЎ}
ЎЎЎЎp articles
ЎЎЎЎХвКЗ»щУЪRubyөДЎ°ЖБД»ҪШИЎЖчЎұЎЈХвёцҪЕұҫТФТ»ёцҙуОДұҫЧЦ·ыҙ®»сИЎТіГжЈ¬И»әуК№УГТ»ЧйёҙФУөДХэФтұнҙпКҪҪвОцТіГжөДұкМвЎўЧчХЯәНГиКцФӘЛШЎЈ
ЎЎЎЎФЪГьБоРРФЛРРКұЈ¬Ҫ«ҝҙөҪЗеөҘ4ЛщКҫөДҙъВлЎЈ
ЎЎЎЎЗеөҘ4. ФЛРРfetch.rb
ЎЎЎЎ% ruby fetch.rb
ЎЎЎЎ[{:author=>"Megan Herrington", :description=>"Everything that I love about dogs I
ЎЎЎЎlearned in preschool", :title=>"What I like about dogs"}, {:author=>"Jack
ЎЎЎЎHerrington", :description=>"How to script, produce and direct Hong Kong action
ЎЎЎЎflicks", :title=>"Making action movies"}, {:author=>"Lori Herrington",
ЎЎЎЎ:description=>"Everything you need to know to win at Paper Mario", :title=>"Super
ЎЎЎЎPaper Mario Tips"}, {:author=>"Oso Herrington", :description=>"", :title=>"Why I
ЎЎЎЎbark"}]
ЎЎЎЎКЗөДЈ¬Ль»сөГБЛКэҫЭЈ¬ө«КЗІ»ДЬ»сөГХвР©ФӘЛШөДIDЈ¬ТтОӘHTMLГ»УРIDЎЈ
ЎЎЎЎДъҝЙДЬПлЦӘөАОӘКІГҙОТСЎФсК№УГRubyКөПЦЎЈХвЦчТӘКЗТтОӘЛьәЬҝбЈ¬ІўЗТТЧУЪФД¶БЈ¬ҝЙКЗХвАпИҙҝҙІ»өҪХвР©УЕөгЎЈө«ХвІ»КЗRubyөДҙнЎЈЖБД»ҪШИЎЖчұҫЙнҫНәЬёҙФУЎЈЛьГЗДСУЪұаРҙЎўТЧУЪіцҙнЎўДСТФО¬»ӨЈ¬јҙК№¶ФҪУҝЪөДHTMLЙФјУРЮёДҫНҝЙДЬұААЈЎЈұҫОДЦРөДЛщУРЖБД»ҪШИЎЖчҙъВл¶јЦ»УРТ»ёцДҝөДЈәЛө·юДъ¶ФКэҫЭЙиЦГXMLҪУҝЪЎЈИз№ыДъөДКэҫЭәЬУРИӨЈ¬ИЛГЗҫНДЬНЁ№эДіЦЦНҫҫ¶ХТөҪЛьЎЈИз№ыДъІ»Ц§іЦXMLЈ¬өұДъёьРВХҫөгТФЎ°ГА»ҜЎұҪзГжКұЈ¬ҫН»б»сөГЖБД»ҪШИЎЈ¬ІўЗТҙҘЕӯҝН»§ЎЈ
ЎЎЎЎМнјУXML·юОс
ЎЎЎЎТтҙЛЈ¬ОӘБЛұЬГвЖБД»ҪШИЎОКМвЈ¬ІўЦЖЧчТ»Р©мЕҝбөДіМРтАҙК№УГОТГЗөДКэҫЭЈ¬ОТҪ«¶ФұнёсұаРҙТ»ёцXMLҪУҝЪЈ¬ИзЗеөҘ5ЛщКҫЎЈ
ЎЎЎЎЗеөҘ5. artxml.php
ЎЎЎЎ
require_once( "DB.php" );
$db =& DB::Connect( 'mysql://root@localhost/articles1', array() );
if (PEAR::isError($db)) { die($db->ЎЎЎЎrequire_once( "DB.php" );
ЎЎЎЎ$db =& DB::Connect( 'mysql://root@localhost/articles1', array() );
ЎЎЎЎif (PEAR::isError($db)) { die($db->getMessage()); }
ЎЎЎЎ$dom = new DomDocument();
ЎЎЎЎ$dom->formatOutput = true;
ЎЎЎЎ$root = $dom->createElement( "articles" );
ЎЎЎЎ$dom->appendChild( $root );
ЎЎЎЎ$res = $db->query( "SELECT * FROM articles" );
ЎЎЎЎ$rows = array();
ЎЎЎЎwhile( $res->fetchInto($row, DB_FETCHMODE_ASSOC) ) {
ЎЎЎЎ$art = $dom->createElement( "article" );
ЎЎЎЎ$art->setAttribute( 'id', $row['id'] );
ЎЎЎЎ$root->appendChild( $art );
ЎЎЎЎ$title = $dom->createElement( "title" );
ЎЎЎЎ$title->appendChild( $dom->createTextNode( $row['title'] ) );
ЎЎЎЎ$art->appendChild( $title );
ЎЎЎЎ$author = $dom->createElement( "author" );
ЎЎЎЎ$author->appendChild( $dom->createTextNode( $row['author'] ) );
ЎЎЎЎ$art->appendChild( $author );
ЎЎЎЎ$desc = $dom->createElement( "description" );
ЎЎЎЎ$desc->appendChild( $dom->createTextNode( $row['description'] ) );
ЎЎЎЎ$art->appendChild( $desc );
ЎЎЎЎ}
ЎЎЎЎheader( "Content-type: text/xml" );
ЎЎЎЎecho $dom->saveXML();
ЎЎЎЎ>
ЎЎЎЎФЪГьБоРРФЛРРҙЛҪЕұҫКұЈ¬Ҫ«»сөГЗеөҘ6ЛщКҫөДКдіцЎЈ
ЎЎЎЎЗеөҘ6. ОДХВXML
ЎЎЎЎ% php artxml.php
ЎЎЎЎ
ЎЎЎЎ
ЎЎЎЎ
ЎЎЎЎ
ЎЎЎЎ
ЎЎЎЎ
ЎЎЎЎpreschool
ЎЎЎЎ
ЎЎЎЎ
ЎЎЎЎ
ЎЎЎЎ
ЎЎЎЎ
ЎЎЎЎflicks
ЎЎЎЎ
ЎЎЎЎ...
ЎЎЎЎХв·ЗіЈЦұ№ЫЎЈУРТ»ёцёщОДХВұкјЗЈ¬Ль°ьә¬Т»ЧйОДХВұкјЗЎЈГҝёцОДХВұкјЗ¶јУРidКфРФЈЁ°ьә¬јЗВјөДКэЧЦidЈ©Ј¬ТФј°ҙжҙўПаУҰКэҫЭөДЧчХЯәНГиКцұкјЗЎЈ
ЎЎЎЎОТК№УГБЛPHPЦРөДXMLОДөө¶ФПуДЈРНЈЁDocument Object ModelЈ¬DOMЈ©№ҰДЬЈ¬¶шІ»КЗКЦ¶ҜұаРҙұкјЗЎЈХвСщDOMҪ«ОӘОТҙҰАнЛщУРXMLҪЪөгЖҪәвәНұаВл№ӨЧчЎЈХвКЗИ·ұЈТіГж·ө»ШөДXMЧЬКЗУРР§өДјтұг·ҪКҪЎЈЗҝБТНЖјцК№УГXML DOM№ҰДЬАҙКдіцXMLЎЈЛщУРЦчТӘөДwebУпСФ¶јЦ§іЦ№№ҪЁәНөјіцXML DOMЎЈ
ЎЎЎЎ»сИЎXML
ЎЎЎЎЙПОДЦРОТХ№КҫБЛҙУHTMLЦРМбИЎКэҫЭөДHTMLәНRubyҙъВлЎЈјИИ»УөУРБЛҙЛXML·юОсЈ¬ПВГжҪ«№ЫІм»сөГПаН¬КэҫЭөДRubyҙъВлЖ¬¶ПЈ¬ө«КЗХвҙОК№УГXMLУпСФЎЈЗеөҘ7ПФКҫБЛXMLМбИЎҙъВлЎЈ
ЎЎЎЎЗеөҘ7. fetchxml.rb
ЎЎЎЎrequire 'net/http'
ЎЎЎЎrequire 'rexml/document'
ЎЎЎЎarticles = []
ЎЎЎЎNet::HTTP.start('localhost', 80) { |http|
ЎЎЎЎresponse = http.get('/ws/artxml.php')
ЎЎЎЎbody = response.body
ЎЎЎЎdoc = REXML::Document.new body
ЎЎЎЎdoc.each_element( '/articles/article' ) { |art|
ЎЎЎЎarticles.push( {
ЎЎЎЎ:id => art.attributes['id'],
ЎЎЎЎ:title => art.elements['title'].text,
ЎЎЎЎ:author => art.elements['author'].text,
ЎЎЎЎ:description => art.elements['description'].text
ЎЎЎЎ} )
ЎЎЎЎ}
ЎЎЎЎ}
ЎЎЎЎp articles
ЎЎЎЎХвёьјтөҘЎЈИФИ»ДЬТФПаН¬өД·ҪКҪ»сөГТіГжЈ¬ө«КЗҪ«ТіГжДЪҙжМṩёшREXMLҝвЈ¬ІўК№УГXML№ҰДЬЗбЛЙҝмҪЭөШ»сөГidЎўұкМвЎўЧчХЯәНГиКцКэҫЭЎЈҙЛҙъВлТЧУЪФД¶БЎўТЧУЪО¬»ӨІўЗТІ»»бұААЈЈ¬іэ·ЗXMLёсКҪ·ўЙъұд»ҜЈ¬ө«ХвІ»М«ҝЙДЬЎЈ
ЎЎЎЎЧчОӘұИҪПЈ¬ОТК№УГC#ұаРҙБЛПаН¬өДҙъВлТФПФКҫИзәОК№УГБҪЦЦІ»Н¬өДУпСФФД¶БөҘёцКэҫЭФҙЎЈИзЗеөҘ8ЛщКҫЎЈ
ЎЎЎЎЗеөҘ8. WebServiceTest.cs
ЎЎЎЎusing System;
ЎЎЎЎusing System.IO;
ЎЎЎЎusing System.Net;
ЎЎЎЎusing System.Xml;
ЎЎЎЎnamespace wstest1
ЎЎЎЎ{
ЎЎЎЎclass WebServiceTest
ЎЎЎЎ{
ЎЎЎЎ[STAThread]
ЎЎЎЎstatic void Main(string[] args)
ЎЎЎЎ{
ЎЎЎЎHttpWebRequest r = (HttpWebRequest)WebRequest.Create(
ЎЎЎЎ"http://localhost/ws/artxml.php" );
ЎЎЎЎWebResponse res = r.GetResponse();
ЎЎЎЎstring sPage;
ЎЎЎЎStreamReader reader = new StreamReader( res.GetResponseStream() );
ЎЎЎЎsPage = reader.ReadToEnd();
ЎЎЎЎreader.Close();
ЎЎЎЎres.Close();
ЎЎЎЎXmlDocument doc = new XmlDocument();
ЎЎЎЎdoc.LoadXml( sPage );
ЎЎЎЎforeach( XmlElement elArticle in doc.GetElementsByTagName( "article" ) )
ЎЎЎЎ{
ЎЎЎЎstring sTitle = (elArticle.SelectSingleNode( "title" )).InnerXml;
ЎЎЎЎstring sAuthor = (elArticle.SelectSingleNode( "author" )).InnerXml;
ЎЎЎЎstring sDescription = (elArticle.SelectSingleNode( "description"
ЎЎЎЎ)).InnerXml;
ЎЎЎЎint nID = Int32.Parse( elArticle.Attributes["id"].Value );
ЎЎЎЎ}
ЎЎЎЎ}
ЎЎЎЎ}
ЎЎЎЎ}
ЎЎЎЎҪвҫцБЛұҫОДЦРЧоДСТФҙҰАнөДІҝ·ЦәуЈ¬ПВГжУҰёГМЦВЫУРИӨөДКВЗйБЛЈ¬ұИИзТФЖдЛы·ҪКҪК№УГXMLҝЙТФКөПЦКІГҙ№ҰДЬЎЈ
ЎЎЎЎФЪXSLTЦРК№УГXML
ЎЎЎЎөИөИЈ¬ОТёХІЕКЗІ»КЗЛөЧоДСТФҙҰАнөДІҝ·ЦТСҫӯҪвҫцБЛЈҝЕ¶Ј¬І»әГТвЛјЈ¬»№УРБнНвТ»ПоЎЈҪб№ы·ўПЦК№УГXML Style Sheet»тXSLҝЙТФҝмЛЩЙиЦГXMLКэҫЭёсКҪЎЈЗеөҘ9ЛщКҫөДҙъВлЙиЦГweb·юОсЈЁҙУarticles.phpТіГжРҙИлөҪHTMLЈ©Лщ·ө»ШөДXMLҙъВлөДёсКҪЎЈ
ЎЎЎЎЗеөҘ9. articles.xsl
ЎЎЎЎ xmlns:xsl="http://www.w3.org/1999/XSL/Transform" xmlns="http://www.w3.org/TR/xhtml1/strict">ЎЎЎЎxmlns:xsl="http://www.w3.org/1999/XSL/Transform" ЎЎЎЎxmlns="http://www.w3.org/TR/xhtml1/strict"> ЎЎЎЎ ЎЎЎЎ ЎЎЎЎ ЎЎЎЎ ЎЎЎЎ ЎЎЎЎ ЎЎЎЎ
ЎЎЎЎ
ЎЎЎЎ ЎЎЎЎ
ЎЎЎЎ ЎЎЎЎ ЎЎЎЎ ЎЎЎЎ ЎЎЎЎ
ЎЎЎЎ¶БЖрАҙУРөгІ»М«ИЭТЧЈ¬ө«КЗХвКЗДъөДXSLЎЈ»щұҫЙПЈ¬XSLКЗДЈКҪЖҘЕдЖчЈ¬ОТ¶ЁТеБЛЖҘЕдҙ«ИлXMLКчөДёщұкјЗөДXSLДЈ°еЎЈЛьКдіцHTMLұЁН·Ј¬И»әуК№УГfor-eachСӯ»·ұйАъГҝЖӘОДХВЈ¬ІўКдіцұкМвЎўЧчХЯәНГиКцөДЦөЈЁИз№ыУРЈ©ЎЈ
ЎЎЎЎҙЛСщКҪұнҝЙТФёҪјУөҪXMLКдіцұҫЙнЈ¬ҙу¶аКэдҜААЖчҪ«К№УГЛьҪ«XMLіКПЦөҪHTMLТФЧФ¶ҜПФКҫЎЈФхГҙСщЈЎ
ЎЎЎЎAjax
ЎЎЎЎҙУУҰУГіМРтЦРөјіцXMLөДЧоҝЙДЬөДАнУЙКЗОӘБЛДЬ№»ФЪwebҝН»§¶ЛЦРК№УГЎЈҝН»§¶ЛөДJavaScriptҝЙТФФЪјУФШТіГжЦ®әуҙУ·юОсЖчЗлЗуXMLЈ¬ІўТФЛьЛщСЎФсөДИОәО·ҪКҪЈЁҫӯіЈёщҫЭУГ»§КдИл¶ҜМ¬ёьёДЈ©іКПЦЈ¬ІўЗТІ»РиТӘЛўРВТіГжЎЈ
ЎЎЎЎЗеөҘ10ПФКҫБЛТ»ёц»щУЪAjaxөДјтөҘұнёсЈ¬ЛьіКПЦАҙЧФXML feedөДКэҫЭЎЈ
ЎЎЎЎЗеөҘ10. ajax.html
ЎЎЎЎ
ЎЎЎЎ
ЎЎЎЎ
ЎЎЎЎ
ЎЎЎЎ
ЎЎЎЎҙЛҙъВлК№УГPrototype.jsҝвҙУКэҫЭҝв·ГОККэҫЭЈ¬И»әуК№УГдҜААЖчЦРөДXML DOM№ҰДЬ·ГОКЧчХЯЎўұкМвәНГиКцЧЦ¶ОЎЈИ»әуЈ¬К№УГHTML DOMәҜКэХл¶ФКэҫЭјҜЦРөДГҝЖӘОДХВПтЎ°articlesЎұұнёсМнјУРВРРәНөҘФӘёсЎЈ
ЎЎЎЎНј3ПФКҫБЛAjaxҙъВлФЪдҜААЖчЦРөДКдіцЎЈ
ЎЎЎЎ
ЎЎЎЎ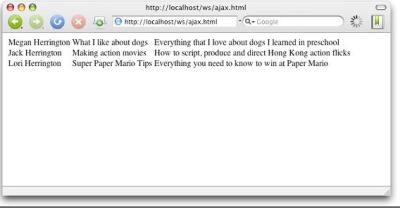
ЎЎЎЎ
ЎЎЎЎНј3. ТіГжөДAjax°жұҫ
ЎЎЎЎХвКЗ·ЗіЈ»щҙЎөДКҫАэЈ¬ө«КЗНкИ«І»ұШПт·юОсЖч¶ЛЗлЗу¶оНвөДКэҫЭЈ¬јҙҝЙЗбЛЙөШЙиПлМнјУҝН»§¶ЛЕЕРт»тЛСЛчЎЈ
ЎЎЎЎК№УГFlex·ГОКXML
ЎЎЎЎПВТ»ҙъДЪИЭ·бё»өДInternetУҰУГіМРтҝтјЬЈЁИзAdobe FlexЈ©КЗ»щУЪXMLІъЙъәН·ўХ№ЖрАҙөДЎЈТтҙЛҝЙТФЗбЛЙК№УГәНПФКҫXMLКэҫЭЎЈ№ЫІмЗеөҘ11ЛщКҫөДКҫАэFlexУҰУГіМРтЎЈ
ЎЎЎЎЗеөҘ11. wstest.mxml
ЎЎЎЎ
ЎЎЎЎ
ЎЎЎЎ
ЎЎЎЎ
ЎЎЎЎ
ЎЎЎЎ
ЎЎЎЎ
ЎЎЎЎ
ЎЎЎЎ
ЎЎЎЎ
ЎЎЎЎ
ЎЎЎЎ
ЎЎЎЎ
ЎЎЎЎЖдЦРІўГ»УРКөјКҙъВлЈ¬ҪцҪцКЗ¶ФXMLКэҫЭФҙөДТэУГЈ¬И»әуҙЛКэҫЭФҙұ»ҙ«ЛНөҪDataGridҝШјюЎЈНј4ПФКҫБЛКдіцЎЈ
ЎЎЎЎ
ЎЎЎЎ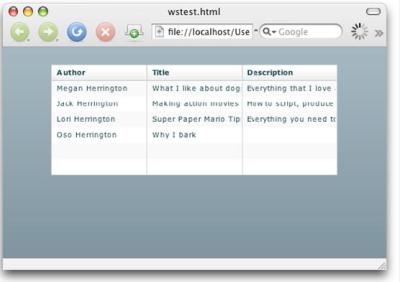
ЎЎЎЎ
ЎЎЎЎНј4. БРұнөДFlex°жұҫ
ЎЎЎЎКЗІ»КЗәЬҝбЈҝКөПЦҙЛ№ҰДЬІ»РиТӘИОәОҙъВлЎЈХвЦ»КЗFlex әНActionScriptК№УГXMLҝЙТФКөПЦөД»щұҫ№ҰДЬЎЈActionScriptУРТ»ёцДЪЦГөДУпСФА©Х№Ј¬ГыОӘE4XЎЈҪиЦъE4XЈ¬ҝЙТФПсК№УГЎ°өгұкЧўЎұУп·ЁТ»СщјтөҘөШөјәҪXMLОДөөКчЎЈХвТвО¶ЧЕГ»УРМ«¶аіБГЖөДXML DOM·Ҫ·ЁЈ¬ҪцҪцКЗЦұ№Ы¶ФПуәНКэЧйТэУГЈ¬ҫНПсДЪҙжЦРУРИОәОЖдЛыКэҫЭҪб№№Т»СщЎЈ
ЎЎЎЎұкЧј»Ҝ
ЎЎЎЎОТК№УГБЛҪцККУЪұҫКҫАэөДXML·зёсЎЈө«КЗТІҝЙТФК№УГұкЧјXMLёсКҪКөПЦЈ¬ИзRSSЎЈЗеөҘ12ЦРөДҙъВлТФRSSёсКҪПФКҫБЛПаН¬КэҫЭҝвКдіцЎЈ
ЎЎЎЎЗеөҘ12. artrss.php
ЎЎЎЎ
require_once( "DB.php" );
$db =& DB::Connect( 'mysql://root@localhost/articles1', array() );
if (PEAR::isError($db)) { die($db->ЎЎЎЎrequire_once( "DB.php" );
ЎЎЎЎ$db =& DB::Connect( 'mysql://root@localhost/articles1', array() );
ЎЎЎЎif (PEAR::isError($db)) { die($db->getMessage()); }
ЎЎЎЎ$dom = new DomDocument();
ЎЎЎЎ$dom->formatOutput = true;
ЎЎЎЎ$rss = $dom->createElement( "rss" );
ЎЎЎЎ$rss->setAttribute( "version", "0.91" );
ЎЎЎЎ$dom->appendChild( $rss );
ЎЎЎЎ$root = $dom->createElement( "channel" );
ЎЎЎЎ$rss->appendChild( $root );
ЎЎЎЎ$rtitle = $dom->createElement( "title" );
ЎЎЎЎ$rtitle->appendChild( $dom->createTextNode( "Article list" ) );
ЎЎЎЎ$root->appendChild( $rtitle );
ЎЎЎЎ$rdesc = $dom->createElement( "description" );
ЎЎЎЎ$rdesc->appendChild( $dom->createTextNode( "The article list" ) );
ЎЎЎЎ$root->appendChild( $rdesc );
ЎЎЎЎ$res = $db->query( "SELECT * FROM articles" );
ЎЎЎЎ$rows = array();
ЎЎЎЎwhile( $res->fetchInto($row, DB_FETCHMODE_ASSOC) ) {
ЎЎЎЎ$art = $dom->createElement( "item" );
ЎЎЎЎ$root->appendChild( $art );
ЎЎЎЎ$title = $dom->createElement( "title" );
ЎЎЎЎ$title->appendChild( $dom->createTextNode( $row['title'] ) );
ЎЎЎЎ$art->appendChild( $title );
ЎЎЎЎ$title = $dom->createElement( "link" );
ЎЎЎЎ$title->appendChild( $dom->createTextNode(
ЎЎЎЎ"http://myhost/showarticle.php?id=".$row['id'] ) );
ЎЎЎЎ$art->appendChild( $title );
ЎЎЎЎ$desc = $dom->createElement( "description" );
ЎЎЎЎ$desc->appendChild( $dom->createTextNode( $row['description'] ) );
ЎЎЎЎ$art->appendChild( $desc );
ЎЎЎЎ}
ЎЎЎЎheader( "Content-type: text/xml" );
ЎЎЎЎecho $dom->saveXML();
ЎЎЎЎ>
ЎЎЎЎҙЛ·Ҫ·ЁөДәГҙҰФЪУЪЈ¬іэБЛҝЙТФФД¶БXMLөДИОәОЧФ¶ЁТеҙъВлЦ®НвЈ¬»№ҝЙТФК№УГЛщУРөДRSS№ӨҫЯЎЈАэИзЈ¬ҝЙТФФЪfeedЦРЦёПтОТөДFirefoxдҜААЖчЈ¬ҫН»бҙҙҪЁҝЙТФ·ЕөҪ№ӨҫЯАёІўјмІйёьРВөДЎ°»о¶ҜКйЗ©ЎұЈ¬ИзНј5ЛщКҫЎЈ
ЎЎЎЎ
ЎЎЎЎ
ЎЎЎЎ
ЎЎЎЎНј5. К№УГFirefoxөДRSS feed
ЎЎЎЎөұИ»Ј¬І»КЗЛщУРКэҫЭ¶јДЬ·ҪұгөШЙиЦГОӘRSSёсКҪЈ¬ХвГ»КІГҙОКМвЎЈө«КЗИз№ыҝЙТФіЙОӘRSSЎўRDF»тИОәОЖдЛы·ҪұгөДXMLёсКҪЎЈДЗГҙЧоәГЧсСӯХвР©ёсКҪЈ¬¶шІ»КЗЧФјә·ўГчЎЈ
ЎЎЎЎҪбКшУп
ЎЎЎЎПЈНыұҫОДДЬ№»К№ДъТФХэИ·өДҪЗ¶ИАнҪвУҰУГіМРтөДweb·юОсЎЈОТЦӘөАІўГ»УРҪІКцЛщУРRESTЎўXML/RPC»тSOAP»щҙЎЦӘК¶ЎЈУРәЬ¶аОДХВМЦВЫ№эХвР©јјКхЈ¬¶аДкТФАҙЈ¬јјКхИЛФұТСҫӯАъ№эәЬ¶а»щУЪұкЧјөДШ¬ГОЎЈПа·ҙЈ¬ОТПЈНыХ№КҫҙУУҰУГіМРтЦР»сөГXMLКэҫЭІўТФКөУГөД·ҪКҪК№УГЛьКЗјю¶аГҙЗбЛЙөДКВЗйЎЈИз№ыОТіЙ№ҰБЛЈ¬ЗлРҙРЕёжЦӘОТІўХ№КҫҙУДъөДУҰУГіМРтЦРМбИЎөДXMLКэҫЭЎЈТІРнОТГЗҝЙТФК№УГЖдЛыweb·юОсТ»ЖрНкіЙТ»ёцmash-upЎЈ
ЎЎЎЎЧКФҙ
ЎЎЎЎFlexКЗ»щУЪҝӘ·ЕФҙВлөДДЪИЭ·бё»өДInternetУҰУГіМРтҝӘ·ў»·ҫіЈ¬УЙAdobeМбіцЎЈ
ЎЎЎЎRESTКЗјтөҘөДweb·юОсұкЧјЈ¬УГАҙёьЦұҪУөШУіЙдөҪHTTPРӯТйЎЈ
ЎЎЎЎSOAPКЗHTTPРӯТйЦ®ЙПөДёЯј¶өД¶ФПу·Ҫ·ЁөчУГРӯТйЎЈ
ЎЎЎЎXML/RPCКЗHTTPРӯТйЦ®ЙПөДЦРјдІг·Ҫ·ЁөчУГРӯТйЈ¬УлSOAPПаұИЈ¬КЗВФОўЗбБҝј¶өДРӯТйЎЈ
ЎЎЎЎRSSКЗҫЫәПұкЧјЈ¬УГУЪІ©ҝНМхДҝәНРВОДХВЦ®АаөДДЪИЭЎЈ
ЎЎЎЎGoogleөДReader·юОсҫНКЗwebдҜААЖч»тЦЗДЬөз»°өДЗҝҙуЎўГв·СөДRSS№ЬАнЖчЎЈ
ЎЎЎЎPrototype.jsКЗГв·СөДJavaScriptҝвЈ¬ҝЙТФ°пЦъұаРҙТЧУЪО¬»ӨөДҝздҜААЖчAjaxҙъВлЎЈЎЎЎЎ
Из№ыДъ·ЗіЈЖИЗРөДПлБЛҪвITБмУтЧоРВІъЖ·УлјјКхРЕПўЈ¬ДЗГҙ¶©ФДЦБ¶ҘНшјјКхУКјюҪ«КЗДъөДЧојСНҫҫ¶Ц®Т»ЎЈ




