ЙПОДЦРОТХ№КҫБЛҙУHTMLЦРМбИЎКэҫЭөДHTMLәНRubyҙъВлЎЈјИИ»УөУРБЛҙЛXML·юОсЈ¬ПВГжҪ«№ЫІм»сөГПаН¬КэҫЭөДRubyҙъВлЖ¬¶ПЈ¬ө«КЗХвҙОК№УГXMLУпСФЎЈЗеөҘ7ПФКҫБЛXMLМбИЎҙъВлЎЈ
ЗеөҘ7. fetchxml.rb
require 'net/http'
require 'rexml/document'
articles = []
Net::HTTP.start('localhost', 80) { |http|
response = http.get('/ws/artxml.php')
body = response.body
doc = REXML::Document.new body
doc.each_element( '/articles/article' ) { |art|
articles.push( {
:id => art.attributes['id'],
:title => art.elements['title'].text,
:author => art.elements['author'].text,
:description => art.elements['description'].text
} )
}
}
p articles
ХвёьјтөҘЎЈИФИ»ДЬТФПаН¬өД·ҪКҪ»сөГТіГжЈ¬ө«КЗҪ«ТіГжДЪҙжМṩёшREXMLҝвЈ¬ІўК№УГXML№ҰДЬЗбЛЙҝмҪЭөШ»сөГidЎўұкМвЎўЧчХЯәНГиКцКэҫЭЎЈҙЛҙъВлТЧУЪФД¶БЎўТЧУЪО¬»ӨІўЗТІ»»бұААЈЈ¬іэ·ЗXMLёсКҪ·ўЙъұд»ҜЈ¬ө«ХвІ»М«ҝЙДЬЎЈ
ЧчОӘұИҪПЈ¬ОТК№УГC#ұаРҙБЛПаН¬өДҙъВлТФПФКҫИзәОК№УГБҪЦЦІ»Н¬өДУпСФФД¶БөҘёцКэҫЭФҙЎЈИзЗеөҘ8ЛщКҫЎЈ
ЗеөҘ8. WebServiceTest.cs
using System;
using System.IO;
using System.Net;
using System.Xml;
namespace wstest1
{
class WebServiceTest
{
[STAThread]
static void Main(string[] args)
{
HttpWebRequest r = (HttpWebRequest)WebRequest.Create(
"http://localhost/ws/artxml.php" );
WebResponse res = r.GetResponse();
string sPage;
StreamReader reader = new StreamReader( res.GetResponseStream() );
sPage = reader.ReadToEnd();
reader.Close();
res.Close();
XmlDocument doc = new XmlDocument();
doc.LoadXml( sPage );
foreach( XmlElement elArticle in doc.GetElementsByTagName( "article" ) )
{
string sTitle = (elArticle.SelectSingleNode( "title" )).InnerXml;
string sAuthor = (elArticle.SelectSingleNode( "author" )).InnerXml;
string sDescription = (elArticle.SelectSingleNode( "description"
)).InnerXml;
int nID = Int32.Parse( elArticle.Attributes["id"].Value );
}
}
}
}
ҪвҫцБЛұҫОДЦРЧоДСТФҙҰАнөДІҝ·ЦәуЈ¬ПВГжУҰёГМЦВЫУРИӨөДКВЗйБЛЈ¬ұИИзТФЖдЛы·ҪКҪК№УГXMLҝЙТФКөПЦКІГҙ№ҰДЬЎЈ
ФЪXSLTЦРК№УГXML
өИөИЈ¬ОТёХІЕКЗІ»КЗЛөЧоДСТФҙҰАнөДІҝ·ЦТСҫӯҪвҫцБЛЈҝЕ¶Ј¬І»әГТвЛјЈ¬»№УРБнНвТ»ПоЎЈҪб№ы·ўПЦК№УГXML Style Sheet»тXSLҝЙТФҝмЛЩЙиЦГXMLКэҫЭёсКҪЎЈЗеөҘ9ЛщКҫөДҙъВлЙиЦГweb·юОсЈЁҙУarticles.phpТіГжРҙИлөҪHTMLЈ©Лщ·ө»ШөДXMLҙъВлөДёсКҪЎЈ
ЗеөҘ9. articles.xsl
<xsl:stylesheet version="1.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
xmlns="http://www.w3.org/TR/xhtml1/strict">
<xsl:output method="html" indent="yes" encoding="iso-8859-1" />
<xsl:template match="/">
<html>
<head><title>Article list</title></head>
<body>
<xsl:for-each select="/articles/article">
<div class="title"><xsl:value-of select="title"/></div>
<div class="author"><xsl:value-of select="author"/></div>
<xsl:if test="string-length( description ) > 0">
<div class="description"><xsl:value-of select="description"/></div>
</xsl:if>
</xsl:for-each>
</body></html>
</xsl:template>
</xsl:stylesheet>
¶БЖрАҙУРөгІ»М«ИЭТЧЈ¬ө«КЗХвКЗДъөДXSLЎЈ»щұҫЙПЈ¬XSLКЗДЈКҪЖҘЕдЖчЈ¬ОТ¶ЁТеБЛЖҘЕдҙ«ИлXMLКчөДёщұкјЗөДXSLДЈ°еЎЈЛьКдіцHTMLұЁН·Ј¬И»әуК№УГfor-eachСӯ»·ұйАъГҝЖӘОДХВЈ¬ІўКдіцұкМвЎўЧчХЯәНГиКцөДЦөЈЁИз№ыУРЈ©ЎЈ
ҙЛСщКҪұнҝЙТФёҪјУөҪXMLКдіцұҫЙнЈ¬ҙу¶аКэдҜААЖчҪ«К№УГЛьҪ«XMLіКПЦөҪHTMLТФЧФ¶ҜПФКҫЎЈФхГҙСщЈЎ
Ajax
ҙУУҰУГіМРтЦРөјіцXMLөДЧоҝЙДЬөДАнУЙКЗОӘБЛДЬ№»ФЪwebҝН»§¶ЛЦРК№УГЎЈҝН»§¶ЛөДJavaScriptҝЙТФФЪјУФШТіГжЦ®әуҙУ·юОсЖчЗлЗуXMLЈ¬ІўТФЛьЛщСЎФсөДИОәО·ҪКҪЈЁҫӯіЈёщҫЭУГ»§КдИл¶ҜМ¬ёьёДЈ©іКПЦЈ¬ІўЗТІ»РиТӘЛўРВТіГжЎЈ
ЗеөҘ10ПФКҫБЛТ»ёц»щУЪAjaxөДјтөҘұнёсЈ¬ЛьіКПЦАҙЧФXML feedөДКэҫЭЎЈ
ЗеөҘ10. ajax.html
<html><head>
<script src="prototype.js"></script>
</head>
<body><table id="articles"></table>
<script>
new Ajax.Request( 'artxml.php', {
method: 'get',
onSuccess: function( transport ) {
var artTags = transport.responseXML.getElementsByTagName( 'article' );
for( var a = 0; a < artTags.length; a++ ) {
var author =
artTags[a].getElementsByTagName('author')[0].firstChild.nodeValue;
var title = artTags[a].getElementsByTagName('title')[0].firstChild.nodeValue;
var description =
artTags[a].getElementsByTagName('description')[0].firstChild.nodeValue;
var elTR = $('articles').insertRow( -1 );
var elTD1 = elTR.insertCell( -1 );
elTD1.innerHTML = author;
var elTD2 = elTR.insertCell( -1 );
elTD2.innerHTML = title;
var elTD3 = elTR.insertCell( -1 );
elTD3.innerHTML = description;
}
}
} );
</script></body></html>
ҙЛҙъВлК№УГPrototype.jsҝвҙУКэҫЭҝв·ГОККэҫЭЈ¬И»әуК№УГдҜААЖчЦРөДXML DOM№ҰДЬ·ГОКЧчХЯЎўұкМвәНГиКцЧЦ¶ОЎЈИ»әуЈ¬К№УГHTML DOMәҜКэХл¶ФКэҫЭјҜЦРөДГҝЖӘОДХВПтЎ°articlesЎұұнёсМнјУРВРРәНөҘФӘёсЎЈ
Нј3ПФКҫБЛAjaxҙъВлФЪдҜААЖчЦРөДКдіцЎЈ
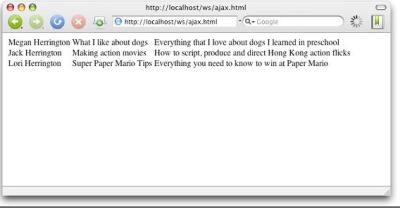
Нј3. ТіГжөДAjax°жұҫ
ХвКЗ·ЗіЈ»щҙЎөДКҫАэЈ¬ө«КЗНкИ«І»ұШПт·юОсЖч¶ЛЗлЗу¶оНвөДКэҫЭЈ¬јҙҝЙЗбЛЙөШЙиПлМнјУҝН»§¶ЛЕЕРт»тЛСЛчЎЈ
К№УГFlex·ГОКXML
ПВТ»ҙъДЪИЭ·бё»өДInternetУҰУГіМРтҝтјЬЈЁИзAdobe FlexЈ©КЗ»щУЪXMLІъЙъәН·ўХ№ЖрАҙөДЎЈТтҙЛҝЙТФЗбЛЙК№УГәНПФКҫXMLКэҫЭЎЈ№ЫІмЗеөҘ11ЛщКҫөДКҫАэFlexУҰУГіМРтЎЈ
ЗеөҘ11. wstest.mxml
<?xml version="1.0" encoding="utf-8"?>
<mx:Application xmlns:mx="http://www.adobe.com/2006/mxml" layout="vertical">
<mx:XML id="articles" source="http://localhost/ws/artxml.php" />
<mx:DataGrid dataProvider="{articles..article}" width="400">
<mx:columns>
<mx:Array>
<mx:DataGridColumn dataField="author" headerText="Author" />
<mx:DataGridColumn dataField="title" headerText="Title" />
<mx:DataGridColumn dataField="description" headerText="Description" />
</mx:Array>
</mx:columns>
</mx:DataGrid>
</mx:Application>
ЖдЦРІўГ»УРКөјКҙъВлЈ¬ҪцҪцКЗ¶ФXMLКэҫЭФҙөДТэУГЈ¬И»әуҙЛКэҫЭФҙұ»ҙ«ЛНөҪDataGridҝШјюЎЈНј4ПФКҫБЛКдіцЎЈ
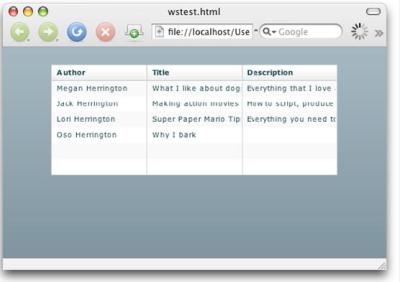
Нј4. БРұнөДFlex°жұҫ
КЗІ»КЗәЬҝбЈҝКөПЦҙЛ№ҰДЬІ»РиТӘИОәОҙъВлЎЈХвЦ»КЗFlex әНActionScriptК№УГXMLҝЙТФКөПЦөД»щұҫ№ҰДЬЎЈActionScriptУРТ»ёцДЪЦГөДУпСФА©Х№Ј¬ГыОӘE4XЎЈҪиЦъE4XЈ¬ҝЙТФПсК№УГЎ°өгұкЧўЎұУп·ЁТ»СщјтөҘөШөјәҪXMLОДөөКчЎЈХвТвО¶ЧЕГ»УРМ«¶аіБГЖөДXML DOM·Ҫ·ЁЈ¬ҪцҪцКЗЦұ№Ы¶ФПуәНКэЧйТэУГЈ¬ҫНПсДЪҙжЦРУРИОәОЖдЛыКэҫЭҪб№№Т»СщЎЈ
ұкЧј»Ҝ
ОТК№УГБЛҪцККУЪұҫКҫАэөДXML·зёсЎЈө«КЗТІҝЙТФК№УГұкЧјXMLёсКҪКөПЦЈ¬ИзRSSЎЈЗеөҘ12ЦРөДҙъВлТФRSSёсКҪПФКҫБЛПаН¬КэҫЭҝвКдіцЎЈ
ЗеөҘ12. artrss.php
<?php
require_once( "DB.php" );
$db =& DB::Connect( 'mysql://root@localhost/articles1', array() );
if (PEAR::isError($db)) { die($db->getMessage()); }
$dom = new DomDocument();
$dom->formatOutput = true;
$rss = $dom->createElement( "rss" );
$rss->setAttribute( "version", "0.91" );
$dom->appendChild( $rss );
$root = $dom->createElement( "channel" );
$rss->appendChild( $root );
$rtitle = $dom->createElement( "title" );
$rtitle->appendChild( $dom->createTextNode( "Article list" ) );
$root->appendChild( $rtitle );
$rdesc = $dom->createElement( "description" );
$rdesc->appendChild( $dom->createTextNode( "The article list" ) );
$root->appendChild( $rdesc );
$res = $db->query( "SELECT * FROM articles" );
$rows = array();
while( $res->fetchInto($row, DB_FETCHMODE_ASSOC) ) {
$art = $dom->createElement( "item" );
$root->appendChild( $art );
$title = $dom->createElement( "title" );
$title->appendChild( $dom->createTextNode( $row['title'] ) );
$art->appendChild( $title );
$title = $dom->createElement( "link" );
$title->appendChild( $dom->createTextNode(
"http://myhost/showarticle.php?id=".$row['id'] ) );
$art->appendChild( $title );
$desc = $dom->createElement( "description" );
$desc->appendChild( $dom->createTextNode( $row['description'] ) );
$art->appendChild( $desc );
}
header( "Content-type: text/xml" );
echo $dom->saveXML();
?>
ҙЛ·Ҫ·ЁөДәГҙҰФЪУЪЈ¬іэБЛҝЙТФФД¶БXMLөДИОәОЧФ¶ЁТеҙъВлЦ®НвЈ¬»№ҝЙТФК№УГЛщУРөДRSS№ӨҫЯЎЈАэИзЈ¬ҝЙТФФЪfeedЦРЦёПтОТөДFirefoxдҜААЖчЈ¬ҫН»бҙҙҪЁҝЙТФ·ЕөҪ№ӨҫЯАёІўјмІйёьРВөДЎ°»о¶ҜКйЗ©ЎұЈ¬ИзНј5ЛщКҫЎЈ
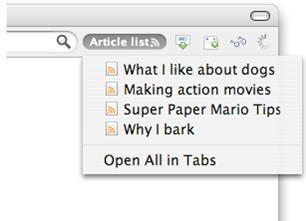
Нј5. К№УГFirefoxөДRSS feed
өұИ»Ј¬І»КЗЛщУРКэҫЭ¶јДЬ·ҪұгөШЙиЦГОӘRSSёсКҪЈ¬ХвГ»КІГҙОКМвЎЈө«КЗИз№ыҝЙТФіЙОӘRSSЎўRDF»тИОәОЖдЛы·ҪұгөДXMLёсКҪЎЈДЗГҙЧоәГЧсСӯХвР©ёсКҪЈ¬¶шІ»КЗЧФјә·ўГчЎЈ
ҪбКшУп
ПЈНыұҫОДДЬ№»К№ДъТФХэИ·өДҪЗ¶ИАнҪвУҰУГіМРтөДweb·юОсЎЈОТЦӘөАІўГ»УРҪІКцЛщУРRESTЎўXML/RPC»тSOAP»щҙЎЦӘК¶ЎЈУРәЬ¶аОДХВМЦВЫ№эХвР©јјКхЈ¬¶аДкТФАҙЈ¬јјКхИЛФұТСҫӯАъ№эәЬ¶а»щУЪұкЧјөДШ¬ГОЎЈПа·ҙЈ¬ОТПЈНыХ№КҫҙУУҰУГіМРтЦР»сөГXMLКэҫЭІўТФКөУГөД·ҪКҪК№УГЛьКЗјю¶аГҙЗбЛЙөДКВЗйЎЈИз№ыОТіЙ№ҰБЛЈ¬ЗлРҙРЕёжЦӘОТІўХ№КҫҙУДъөДУҰУГіМРтЦРМбИЎөДXMLКэҫЭЎЈТІРнОТГЗҝЙТФК№УГЖдЛыweb·юОсТ»ЖрНкіЙТ»ёцmash-upЎЈ
ЧКФҙ
FlexКЗ»щУЪҝӘ·ЕФҙВлөДДЪИЭ·бё»өДInternetУҰУГіМРтҝӘ·ў»·ҫіЈ¬УЙAdobeМбіцЎЈ
RESTКЗјтөҘөДweb·юОсұкЧјЈ¬УГАҙёьЦұҪУөШУіЙдөҪHTTPРӯТйЎЈ
SOAPКЗHTTPРӯТйЦ®ЙПөДёЯј¶өД¶ФПу·Ҫ·ЁөчУГРӯТйЎЈ
XML/RPCКЗHTTPРӯТйЦ®ЙПөДЦРјдІг·Ҫ·ЁөчУГРӯТйЈ¬УлSOAPПаұИЈ¬КЗВФОўЗбБҝј¶өДРӯТйЎЈ
RSSКЗҫЫәПұкЧјЈ¬УГУЪІ©ҝНМхДҝәНРВОДХВЦ®АаөДДЪИЭЎЈ
GoogleөДReader·юОсҫНКЗwebдҜААЖч»тЦЗДЬөз»°өДЗҝҙуЎўГв·СөДRSS№ЬАнЖчЎЈ
Prototype.jsКЗГв·СөДJavaScriptҝвЈ¬ҝЙТФ°пЦъұаРҙТЧУЪО¬»ӨөДҝздҜААЖчAjaxҙъВлЎЈ




