
Salesforce研究院创建“瑞士军刀式”自然语言处理架构
至顶网软件频道消息:Salesforce研究院(Salesforce Research)创建的自然语言处理架构可以处理多种模型和任务。在通常情况下,自然语言处理(NLP)针对每种功能(如翻译、情感分析和问题和答案)都需建一个模型。
由Salesforce首席科学家Richard Socher领导的一项研究旨在完成名为自然语言 Decathlon(decaNLP)的挑战任务。decaNLP挑战涵盖了10个任务: 问题回答、机器翻译、汇总、自然语言推理、情感分析、语义角色标注、关系提取、目标导向对话、数据库查询生成和代词解析,这些任务被送至系统进行共同学习。
可以将decaNLP想象成自然语言处理瑞士军刀。如果NLP需要重复定制,规模大了以后就不能使用。 Salesforce想寻找一种通用的NLP方法,将每项任务转换为问题回答格式并进行共同训练。
Socher表示,该方法融合了深度学习和NLP,可将问题的讨论转向围绕元架构的讨论。他补充表示,架构方法也可以用来防止NLP函数分层的模型蔓延。
Socher表示,“这个项目可以即时用在一些有用的应用上,因为项目是个单一部署模型,而且易于维护。我们将一堆工具整合在一起。”
Salesforce可能会在爱因斯坦分析及各种云计算的产品路线图里使用decaNLP方法。
decaNLP可与多任务问答网络结合在一起,无需任何特定模型就可以针对所有任务进行共同学习。该网络还可以通过新任务相关的说明进行自适应调变。
下图是多任务问答网络图。
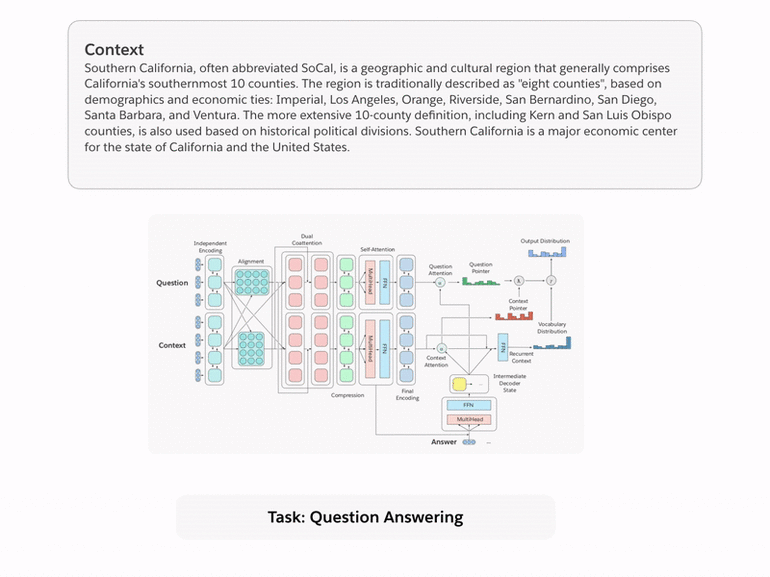
另外,Salesforce 研究院还完成了处理数据集、训练和评估模型的代码,并定义了一个名为decaScore的评分。
用decaNLP系统训练过的NLP理论上可以为聊天机器人提供更好的框架及更好地提供客户服务交换中的任何信息。
来源:ZDNet
好文章,需要你的鼓励


Uber年度遗失物报告揭示:数千件物品遗留在无人驾驶出租车中
Uber年度失物报告首次纳入无人驾驶出租车数据。过去一年,乘客在Uber平台的机器人出租车中遗留了数千件物品,包括手机、钥匙、钱包等常见物品,以及假牙、15磅溜溜球等奇特物件。乘客可通过App联系客服找回失物,支付15美元即可享受同城配送,或前往车辆停放站自取。Uber表示,将依托现有运营体系为自动驾驶业务提供全面支持,计划2025年底前在全球15座城市开通无人驾驶打车服务。

当AI学生卡在难题前:LinkedIn等机构如何让AI通过“偷师学艺“突破学习瓶颈
TREK方法通过引入外部验证解法对AI进行短期校准,解决了GRPO训练在困难题目上因无法探索正确解法区域而陷入瓶颈的问题,在数学推理和智能体任务上均取得明显提升。

Uber今年将部署500辆数据采集车辆,助力自动驾驶发展
Uber周三发布了一款基于现代Ioniq 5改装的数据采集原型车,搭载14个摄像头、8个固态激光雷达和9个雷达,通过英伟达双驱Thor计算机处理数据。Uber计划今年在全球部署500辆此类车辆,每月可采集200万英里高保真驾驶数据,供Avride、Waymo、WeRide等30余家自动驾驶合作伙伴使用。这是Uber自2020年出售自动驾驶部门以来首次自主组装车辆,也是其AV Labs部门的重要进展。

LMMs-Lab与NTU MMLab联手微软:让AI智能体“一句话自我进化“的秘密
SkillOpt-Lite通过将智能体技能优化形式化为零阶优化问题,提出极简流水线:把执行轨迹存为文本文件,让AI直接用文件系统工具翻日志、找规律、改技能,配合独立验证门控,比复杂的多智能体优化框架跑得更快效果更好,并自然延伸至执行框架自动优化(HarnessOpt),使轻量模型能够超越大模型。
2018
06/21
16:00
分享
点赞

Uber年度遗失物报告揭示:数千件物品遗留在无人驾驶出租车中
Uber今年将部署500辆数据采集车辆,助力自动驾驶发展
Uber、Wayve与Waymo的伦敦无人驾驶出租车大战即将开启
Mobileye计划2027年在美国推出自动驾驶出租车服务
Waymo召回近4000辆无人出租车,原因是其进入高速公路施工区域
特斯拉在奥斯汀开始测试无方向盘无踏板Cybercab量产版
图灵奖得主Patterson:摩尔定律的真相,CPU、GPU、TPU的诞生与分工
Omdia报告:Dell PowerProtect助力企业三年期网络弹性TCO最高降低61%
“驯服”千亿模型,鏖战“黑猴打瓦”,龙虾“一键接管” ,锐龙AI Max+ 395开启全能桌面AI主机“王炸”时刻
豪声电子泰国电声工厂初步投产:2500万泰铢项目进入产能爬坡
地瓜机器人将560TOPS端侧算力,加载到了20+头部团队机器人中
WAIC 2026主论坛(下午场)重磅揭晓!
