10 月 9 日我将去南京,参加支付宝 2008 校园招聘南京大学站。Cocolog是日本领先的 Blog 社区,基于 SixApart 的 TypePad 技术框架。运营公司是 NIFTY(最新的调查报告显示,NIFTY 在日本流量排名第 10) 。前一段时间看到这篇 Migrating from PostgreSQL to MySQL at Cocolog, Japan's Largest Blog Community,比较详细的描述了从 PostgreSQL 迁移到 MySQL 的经验,很有参考价值(日本互联网技术特点?),在这里做一篇学习笔记。
核心系统的支撑软件
Linux 2.4/2.6
Apache 1.3/2.0/2.2 &mod_perl
Perl5.8+CPAN
PostgreSQL 8.1
MySQL 5.0
Memcached/TheSchwartz/cfengine
都是一些司空见惯的东西, cfengine是用作软件维护、部署、分发的玩意儿。
初期技术架构示意图
这是我第一次知道 TypePad 除了 SixApart 自己的服务之外还支撑了第三方的站点(孤陋寡闻!)。
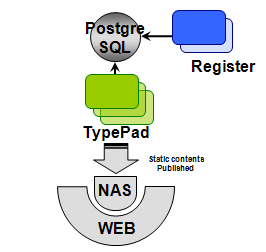
初期 PostgreSQL 基本上是用来存储本地注册用户信息。这个阶段数据库分区之前,服务器数量在 10 个以下。
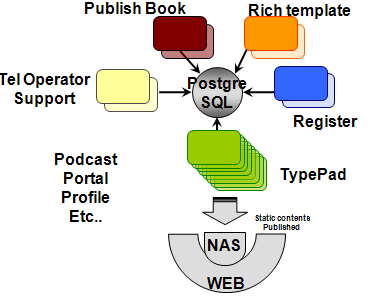
第二阶段
这阶段数据库分区之前,服务器数量在 50 个以下,可以看到 DB 还额外存储了富内容模板等元数据信息。系统各个模块紧耦合,数据库 Schema 变更有些费劲了。
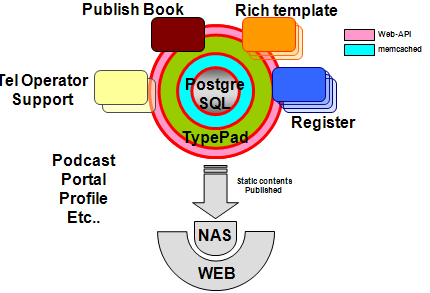
第三阶段
Web API的引入在一定程度上消除了紧耦合的问题,Memcached 的引入很大程度减轻了 DB 的负担。服务器数量在 200 个以下,未分区之前。
第四阶段
数据库分区之前,服务器数量在 300 个以下,增加对移动互联网的支持能力。这个时候 PostgreSQL 貌似还是单实例的样子。数据超过 100GB,40% 是索引。要忍受比较严重的数据碎片问题,备份是个麻烦事儿。
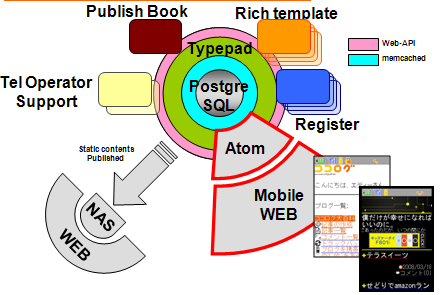
在此之前,PostgreSQL 服务器在硬件上一直是 Scale Up 的思路,内存从最初的 1GB 扩展到 07 年底迁移前的 16GB,磁盘换到了阵列上,阵列是富士通的 E8000。国内倒是很少遇到有把 PostgreSQL 扔到企业存储上的案例。
现阶段
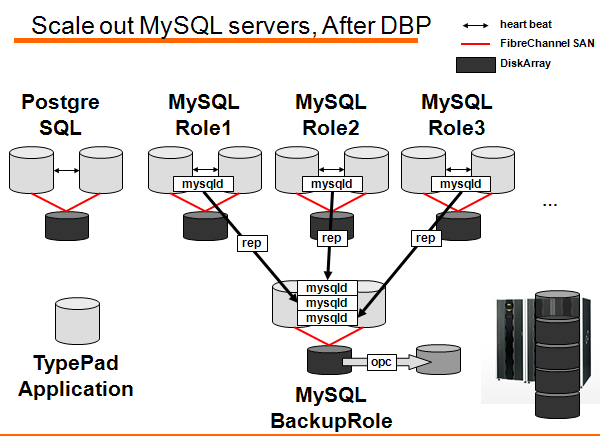
这是迁移后的架构示意图。引入了多个 MySQL 实例。从原来的 Scale Up 切换到 Scale Out 的路线上。数据库分区,服务器数量 150 个。
集群软件采用了 NEC 的 ClusterPro。数据库是共享存储的,不过 I/O 瓶颈应该消除了,因为读的压力分散在每个 MySQL 服务器上,内存承担了大部分工作。写操作的压力在一台存储上,问题不会很大。
实施步骤
1. 服务器准备;
2. 全局写问题(Global Write) 应对策略:写用户信息到全局 DB 中;
3. 全局读问题 应对策略:读、写用户信息在全局 DB 中折腾;
4. 迁移序列 应对策略:全局 DB 承担;
5. 用户数据迁移 (User Data Move) 应对策略:移动用户数据到用户分区中;
6. 新用户分区 (New User Partition) 应对策略:所有新用户直接保存到新用户分区1中;
7. 新用户数据处理策略 根据需求设定一个策略;
8. 非用户数据迁移。
这几个过程都不难理解,数据迁移的一节倒是值得描述一下:

对上图做个解释(其实也是翻译 PPT上的注释):
1 Job 服务器提交一个新的Schwartz Job 迁移已有的用户数据,用户数据异步迁移;
2 迁移中的用户发布的留言保存到 Schwartz ,稍后发布;
3 迁移完毕后,所有用户数据存放在用户角色 DB 分区;
4 一旦所有用户数据迁移完毕,只有非用户相关数据存在 PostgreSQL 中。
这个迁移的技术细节其实可能不那么重要,但重要的是必须有个迁移流程的制定过程,任何所谓的迁移,如果没有制定详细的计划,无疑会吃苦头。
迁移后的备份示意图:
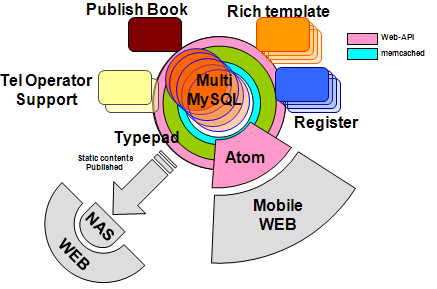
最后看一下架构概览图(点击可放大):

Tip:这个架构图中关于 NAS 部分,可能不那么可靠的。
上面引用的图版权归原 PPT 作者所有。转载我这篇流水帐的网站请不要随便给图片打水印。
--EOF--
P.S. 如果你有耐心看完前面的部分,你或许应该提出如下疑问:
1)为什么要迁移到 MySQL ? PostgreSQL 也是支持分区的啊 ...
2) 这其实就是个数据 Sharding (分片)的问题, 作者为啥不直接说?
3) 第五阶段, 服务器数量为什么变少了?
4) 迁移全是在线进行的么? 有没有影响用户访问?
如果一个问题都没有, 其实和没看差不多。
又及:PPT 里面提到的监控指标也需要注意一下,你的网站监控了这些内容么?



